Python使用ClickHouse的实践与踩坑记录
目录
- 1. 关于ClickHouse使用实践
- 1.1. ClickHouse 应用于数据仓库场景
- 1.2. 客户端工具DBeaver
- 1.3. 大数据应用实践
- 2. Python使用ClickHouse实践
- 2.1. ClickHouse第三方Python驱动clickhouse_driver
- 2.2. 实践程序代码
- 3. 小结一下
- 操作ClickHouse删除指定数据
ClickHouse是近年来备受关注的开源列式数据库(DBMS),主要用于数据联机分析(OLAP)领域,于2016年开源。目前国内社区火热,各个大厂纷纷跟进大规模使用。
- 今日头条,内部用ClickHouse来做用户行为分析,内部一共几千个ClickHouse节点,单集群最大1200节点,总数据量几十PB,日增原始数据300TB左右。
- 腾讯内部用ClickHouse做游戏数据分析,并且为之建立了一整套监控运维体系。
- 携程内部从2018年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。每天数据增量十多亿,近百万次查询请求。
- 快手内部也在使用ClickHouse,存储总量大约10PB, 每天新增200TB, 90%查询小于3S。
在国外,Yandex内部有数百节点用于做用户点击行为分析,CloudFlare、Spotify等头部公司也在使用。
ClickHouse最初是为 YandexMetrica 世界第二大Web分析平台 而开发的。多年来一直作为该系统的核心组件被该系统持续使用着。
1. 关于ClickHouse使用实践
首先,我们回顾一些基础概念:
OLTP:是传统的关系型数据库,主要操作增删改查,强调事务一致性,比如银行系统、电商系统。OLAP:是仓库型数据库,主要是读取数据,做复杂数据分析,侧重技术决策支持,提供直观简单的结果。
1.1. ClickHouse 应用于数据仓库场景
ClickHouse做为列式数据库,列式数据库更适合OLAP场景,OLAP场景的关键特征:
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
1.2. 客户端工具DBeaver
Clickhouse客户端工具为dbeaver,官网为https://dbeaver.io/。
- dbeaver是免费和开源(GPL)为开发人员和数据库管理员通用数据库工具。[百度百科]
- 易用性是该项目的主要目标,是经过精心设计和开发的数据库管理工具。免费、跨平台、基于开源框架和允许各种扩展写作(插件)。
- 它支持任何具有一个JDBC驱动程序数据库。
- 它可以处理任何的外部数据源。
通过操作界面菜单中“数据库”创建配置新连接,如下图所示,选择并下载ClickHouse驱动(默认不带驱动)。

DBeaver配置是基于Jdbc方式,一般默认URL和端口如下:
jdbc:clickhouse://192.168.17.61:8123
如下图所示。
在是用DBeaver连接Clickhouse做查询时,有时候会出现连接或查询超时的情况,这个时候可以在连接的参数中添加设置socket_timeout参数来解决问题。
jdbc:clickhouse://{host}:{port}[/{database}]?socket_timeout=600000

1.3. 大数据应用实践
- 环境简要说明:
- 硬件资源有限,仅有16G内存,交易数据为亿级。
本应用是某交易大数据,主要包括交易主表、相关客户信息、物料信息、历史价格、优惠及积分信息等,其中主交易表为自关联树状表结构。
为了分析客户交易行为,在有限资源的条件下,按日和交易点抽取、汇集交易明细为交易记录,如下图所示。
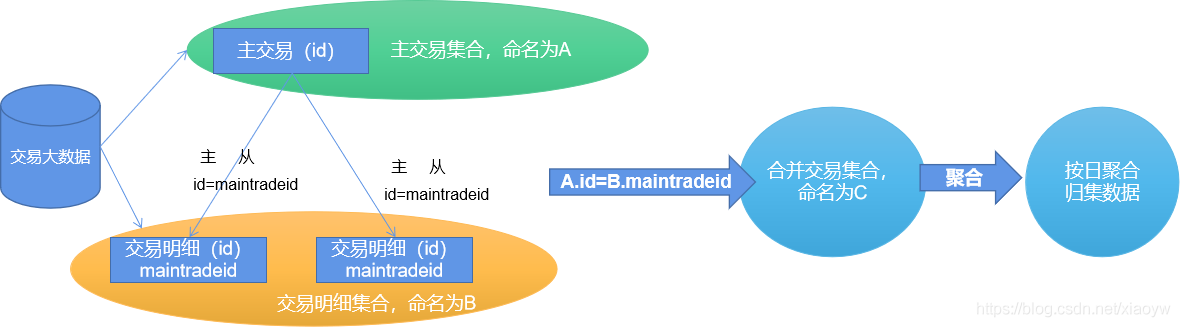
其中,在ClickHouse上,交易数据结构由60个列(字段)组成,截取部分如下所示:

针对频繁出现“would use 10.20 GiB , maximum: 9.31 GiB”等内存不足的情况,基于ClickHouse的SQL,编写了提取聚合数据集SQL语句,如下所示。

大约60s返回结果,如下所示:

2. Python使用ClickHouse实践
2.1. ClickHouse第三方Python驱动clickhouse_driver
ClickHouse没有提供官方Python接口驱动,常用第三方驱动接口为clickhouse_driver,可以使用pip方式安装,如下所示:
pip install clickhouse_driver
Collecting clickhouse_driver
Downloading https://files.pythonhosted.org/packages/88/59/c570218bfca84bd0ece896c0f9ac0bf1e11543f3c01d8409f5e4f801f992/clickhouse_driver-0.2.1-cp36-cp36m-win_amd64.whl (173kB)
100% |████████████████████████████████| 174kB 27kB/s
Collecting tzlocal<3.0 (from clickhouse_driver)
Downloading https://files.pythonhosted.org/packages/5d/94/d47b0fd5988e6b7059de05720a646a2930920fff247a826f61674d436ba4/tzlocal-2.1-py2.py3-none-any.whl
Requirement already satisfied: pytz in d:\python\python36\lib\site-packages (from clickhouse_driver) (2020.4)
Installing collected packages: tzlocal, clickhouse-driver
Successfully installed clickhouse-driver-0.2.1 tzlocal-2.1
使用的client api不能用了,报错如下:
File "clickhouse_driver\varint.pyx", line 62, in clickhouse_driver.varint.read_varint
File "clickhouse_driver\bufferedreader.pyx", line 55, in clickhouse_driver.bufferedreader.BufferedReader.read_one
File "clickhouse_driver\bufferedreader.pyx", line 240, in clickhouse_driver.bufferedreader.BufferedSocketReader.read_into_buffer
EOFError: Unexpected EOF while reading bytes
Python驱动使用ClickHouse端口9000。
ClickHouse服务器和客户端之间的通信有两种协议:http(端口8123)和本机(端口9000)。DBeaver驱动配置使用jdbc驱动方式,端口为8123。
ClickHouse接口返回数据类型为元组,也可以返回Pandas的DataFrame,本文代码使用的为返回DataFrame。
collection = self.client.query_dataframe(self.query_sql)
2.2. 实践程序代码
由于我本机最初资源为8G内存(现扩到16G),以及实际可操作性,分批次取数据保存到多个文件中,每个文件大约为1G。
# -*- coding: utf-8 -*-
'''
Created on 2021年3月1日
@author: xiaoyw
'''
import pandas as pd
import json
import numpy as np
import datetime
from clickhouse_driver import Client
#from clickhouse_driver import connect
# 基于Clickhouse数据库基础数据对象类
class DB_Obj(object):
'''
192.168.17.61:9000
ebd_all_b04.card_tbl_trade_m_orc
'''
def __init__(self, db_name):
self.db_name = db_name
host='192.168.17.61' #服务器地址
port ='9000' #'8123' #端口
user='***' #用户名
password='***' #密码
database=db_name #数据库
send_receive_timeout = 25 #超时时间
self.client = Client(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
#self.conn = connect(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
def setPriceTable(self,df):
self.pricetable = df
def get_trade(self,df_trade,filename):
print('Trade join price!')
df_trade = pd.merge(left=df_trade,right=self.pricetable[['occurday','DIM_DATE','END_DATE','V_0','V_92','V_95','ZDE_0','ZDE_92',
'ZDE_95']],how="left",on=['occurday'])
df_trade.to_csv(filename,mode='a',encoding='utf-8',index=False)
def get_datas(self,query_sql):
n = 0 # 累计处理卡客户数据
k = 0 # 取每次DataFrame数据量
batch = 100000 #100000 # 分批次处理
i = 0 # 文件标题顺序累加
flag=True # 数据处理解释标志
filename = 'card_trade_all_{}.csv'
while flag:
self.query_sql = query_sql.format(n, n+batch)
print('query started')
collection = self.client.query_dataframe(self.query_sql)
print('return query result')
df_trade = collection #pd.DataFrame(collection)
i=i+1
k = len(df_trade)
if k > 0:
self.get_trade(df_trade, filename.format(i))
n = n + batch
if k == 0:
flag=False
print('Completed ' + str(k) + 'trade details!')
print('Usercard count ' + str(n) )
return n
# 价格变动数据集
class Price_Table(object):
def __init__(self, cityname, startdate):
self.cityname = cityname
self.startdate = startdate
self.filename = 'price20210531.csv'
def get_price(self):
df_price = pd.read_csv(self.filename)
......
self.price_table=self.price_table.append(data_dict, ignore_index=True)
print('generate price table!')
class CardTradeDB(object):
def __init__(self,db_obj):
self.db_obj = db_obj
def insertDatasByCSV(self,filename):
# 存在数据混合类型
df = pd.read_csv(filename,low_memory=False)
# 获取交易记录
def getTradeDatasByID(self,ID_list=None):
# 字符串过长,需要使用'''
query_sql = '''select C.carduser_id,C.org_id,C.cardasn,C.occurday as
......
limit {},{})
group by C.carduser_id,C.org_id,C.cardasn,C.occurday
order by C.carduser_id,C.occurday'''
n = self.db_obj.get_datas(query_sql)
return n
if __name__ == '__main__':
PTable = Price_Table('湖北','2015-12-01')
PTable.get_price()
db_obj = DB_Obj('ebd_all_b04')
db_obj.setPriceTable(PTable.price_table)
CTD = CardTradeDB(db_obj)
df = CTD.getTradeDatasByID()
返回本地文件为:

3. 小结一下
ClickHouse在OLAP场景下应用,查询速度非常快,需要大内存支持。Python第三方clickhouse-driver 驱动基本满足数据处理需求,如果能返回Pandas DataFrame最好。
ClickHouse和Pandas聚合都是非常快的,ClickHouse聚合函数也较为丰富(例如文中anyLast(x)返回最后遇到的值),如果能通过SQL聚合的,还是在ClickHouse中完成比较理想,把更小的结果集反馈给Python进行机器学习。
操作ClickHouse删除指定数据
def info_del2(i):
client = click_client(host='地址', port=端口, user='用户名', password='密码',
database='数据库')
sql_detail='alter table SS_GOODS_ORDER_ALL delete where order_id='+str(i)+';'
try:
client.execute(sql_detail)
except Exception as e:
print(e,'删除商品数据失败')
在进行数据删除的时候,python操作clickhou和mysql的方式不太一样,这里不能使用以往常用的%s然后添加数据的方式,必须完整的编辑一条语句,如同上面方法所写的一样,传进去的参数统一使用str类型
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python实现MySQL指定表增量同步数据到clickhouse的脚本
python实现MySQL指定表增量同步数据到clickhouse,脚本如下: #!/usr/bin/env python3 # _*_ coding:utf8 _*_ from pymysqlreplication import BinLogStreamReader from pymysqlreplication.row_event import (DeleteRowsEvent,UpdateRowsEvent,WriteRowsEvent,) import clickhouse_driver
-
python连接clickhouse数据库的两种方式小结
目录 python连接clickhouse数据库 主要针对clickhouse_driver的使用进行简要介绍 python将数据写入clickhouse python连接clickhouse数据库 在Python中获取系统信息的一个好办法是使用psutil这个第三方模块. 顾名思义,psutil = process and system utilities,它不仅可以通过一两行代码实现系统监控,还可以跨平台使用. 主要针对clickhouse_driver的使用进行简要介绍 第一步: 通过pi
-

Python使用ClickHouse的实践与踩坑记录
目录 1. 关于ClickHouse使用实践 1.1. ClickHouse 应用于数据仓库场景 1.2. 客户端工具DBeaver 1.3. 大数据应用实践 2. Python使用ClickHouse实践 2.1. ClickHouse第三方Python驱动clickhouse_driver 2.2. 实践程序代码 3. 小结一下 操作ClickHouse删除指定数据 ClickHouse是近年来备受关注的开源列式数据库(DBMS),主要用于数据联机分析(OLAP)领域,于2016年开源.目前
-
Java 热更新 Groovy 实践及踩坑指南(推荐)
目录 Groovy 是什么? Java 为何需要 Groovy ? 热部署技术设计及实现 使用场景 风控安全——规则引擎 监控中心 活动营销 技术实现 脚本加载/更新 脚本执行 生产踩坑指南 Java8 lambda 与 Groovy 语法问题 GroovyClassLoader 加载机制导致频繁gc问题 脚本首次执行耗时高 Groovy 是什么? Apache的Groovy是Java平台上设计的面向对象编程语言.这门动态语言拥有类似Python.Ruby和Smalltalk中的一些特性,可以作
-
关于python scrapy中添加cookie踩坑记录
问题发现: 前段时间项目中,为了防止被封号(提供的可用账号太少),对于能不登录就可以抓取的内容采用不带cookie的策略,只有必要的内容才带上cookie去访问. 本来想着很简单:在每个抛出来的Request的meta中带上一个标志位,通过在CookieMiddleware中查看这个标志位,决定是否是给这个Request是否装上Cookie. 实现的代码大致如下: class CookieMiddleware(object): """ 每次请求都随机从账号池中选择一个账号去访
-
python中remove函数的踩坑记录
摘要: 在python的使用过程中,难免会遇到要移除列表中对象的要求.这时可以使用remove函数. 对于python中的remove()函数,官方文档的解释是:Remove first occurrence of value.大意也就是移除列表中等于指定值的第一个匹配的元素. 语法 list.remove() 参数 obj 参数:从列表中删除的对象的索引 返回值 删除后不会返回值 常见用法: a = [1,2,3,4],a.remove(1),然后a就是[2,3,4]:对于a = [1,1,1
-
python变量赋值机制踩坑记录
目录 1.可变类型赋值 2.不可变类型赋值 3.自定义类型变量赋值 先说结论: 变量赋值属于浅拷贝(关于深拷贝和浅拷贝的区别可以自己了解下).故如果是可变类型变量(如a是list类型,a=b)赋值,修改a会牵连到b:如果是不可变类型(如int)的赋值,则修改任意变量不会传递. 1. 可变类型赋值 可以看出,对于可变类型赋值,变量始终指向同一块地址. 2. 不可变类型赋值 对于不可变类型变量的赋值,刚开始是指向同一块地址,但修改任意变量,则修改的变量指向另外一块地址,不会影响另外一个变量. 那么问
-
.net core 3.1在iis上发布的踩坑记录
前言 写这篇文章的目的是希望像我一样喜欢.net 的人在发布 core到 iis上时少走点弯路 网上找了些资料,其实实际操作比较简单,就是有几个坑很恶心 踩坑记录 首先是你的服务器需要有core 的运行环境,安装前先关闭iis dotnet-hosting-3.1.4-win.exe 可以去微软的官网找最新的版本(去微软的官网找你要的版本就好了) 安装成功后,第一个坑出现了,启动iis,发现原来在iis上的网站都报503错误了. 直接玩大了,最后发现就是这个东西搞的鬼,你卸载它iis之前的网站就
-
Linux/Docker 中使用 System.Drawing.Common 踩坑记录分享
前言 在项目迁移到 .net core 上面后,我们可以使用 System.Drawing.Common 组件来操作 Image,Bitmap 类型,实现生成验证码.二维码,图片操作等功能.System.Drawing.Common 组件它是依赖于 GDI+ 的,然后在 Linux 上并没有 GDI+,面向谷歌编程之后发现,Mono 团队使用 C语言 实现了GDI+ 接口,提供对非Windows系统的 GDI+ 接口访问能力,这个应该就是libgdiplus.所以想让代码在 linux 上稳定运
-
Java踩坑记录之Arrays.AsList
前言 java.util.Arrays的asList方法可以方便的将数组转化为集合,我们平时开发在初始化ArrayList时使用的比较多,可以简化代码,但这个静态方法asList()有几个坑需要注意: 一. 如果对集合使用增加或删除元素的操作将会报错 如下代码: List list = Arrays.asList("a","b","c"); list.add("d"); 输出结果: Exception in thread &q
-
Java踩坑记录之BigDecimal类
前言 在java.math包中提供了对大数字的操作类,用于进行高精确计算,如BigInteger,BigDecimal类.而平常我们开发中使用最多的float和double只能适用于一般的科学和工程计算,如果要在比较精确的计算方面如货币,那么使用float和double会相应的丢失精度,因此用于精密计算大数字的类BigDecimal就必不可少了.所以BigDecimal适合商业计算场景,用来对超过16位有效位的数进行精确的运算.但是BigDecimal的使用并不像float和double那样,使
-
Echarts在Taro微信小程序开发中的踩坑记录
背景 近期笔者在使用Taro进行微信小程序开发,当引入Echarts图表库时,微信检测单包超限2M的一系列优化措施的踩坑记录,期望能指导读者少走一些弯路. 为什么选择Echarts? 微信小程序目录市面上使用最多的两款图表库,如下: echarts-for-weixin--echarts微信小程序版本 wx-charts--基于微信小程序的图表库 对比两款图表库优缺点刚好相反. echarts-for-weixin:功能强大,但体积非常大 wx-charts:功能相对简单,但体积小 由于笔者对e