python绘图pyecharts+pandas的使用详解
pyecharts介绍
pyecharts 是一个用于生成 Echarts 图表的类库。Echarts 是百度开源的一个数据可视化 JS 库。用 Echarts 生成的图可视化效果非常棒
为避免绘制缺漏,建议全部安装
为了避免下载缓慢,作者全部使用镜像源下载过了
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ echarts-countries-pypkg pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ echarts-china-provinces-pypkg pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ echarts-china-cities-pypkg pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ echarts-china-counties-pypkg pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ echarts-china-misc-pypkg pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ echarts-united-kingdom-pypkg
基础案例
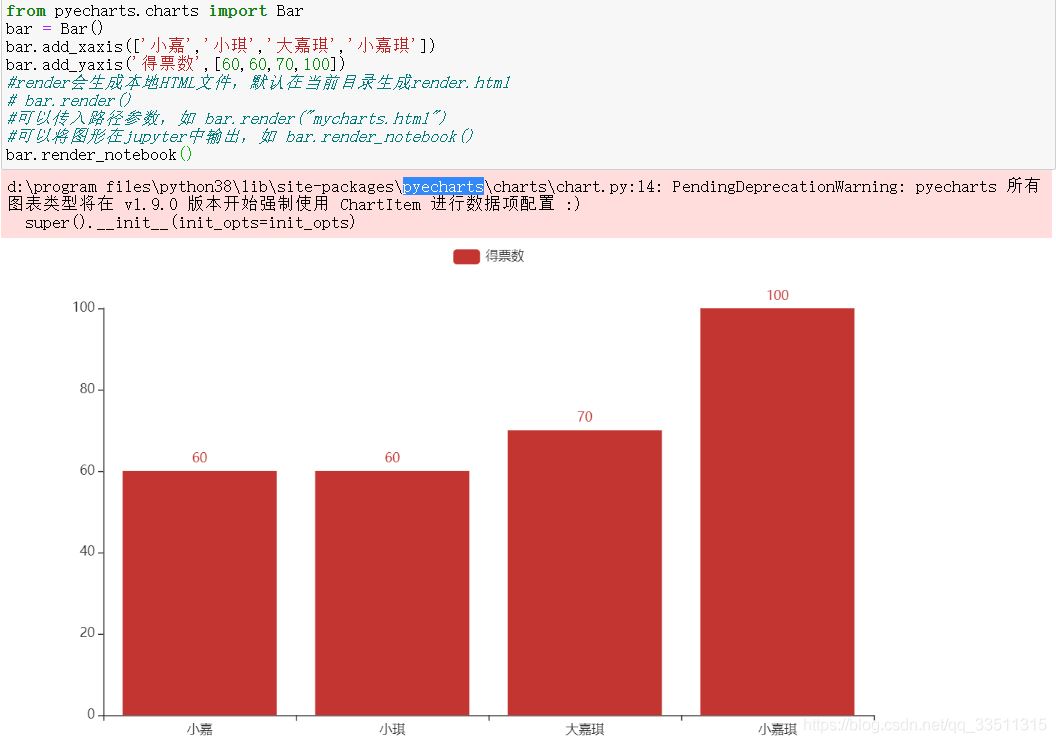
from pyecharts.charts import Bar
bar = Bar()
bar.add_xaxis(['小嘉','小琪','大嘉琪','小嘉琪'])
bar.add_yaxis('得票数',[60,60,70,100])
#render会生成本地HTML文件,默认在当前目录生成render.html
# bar.render()
#可以传入路径参数,如 bar.render("mycharts.html")
#可以将图形在jupyter中输出,如 bar.render_notebook()
bar.render_notebook()
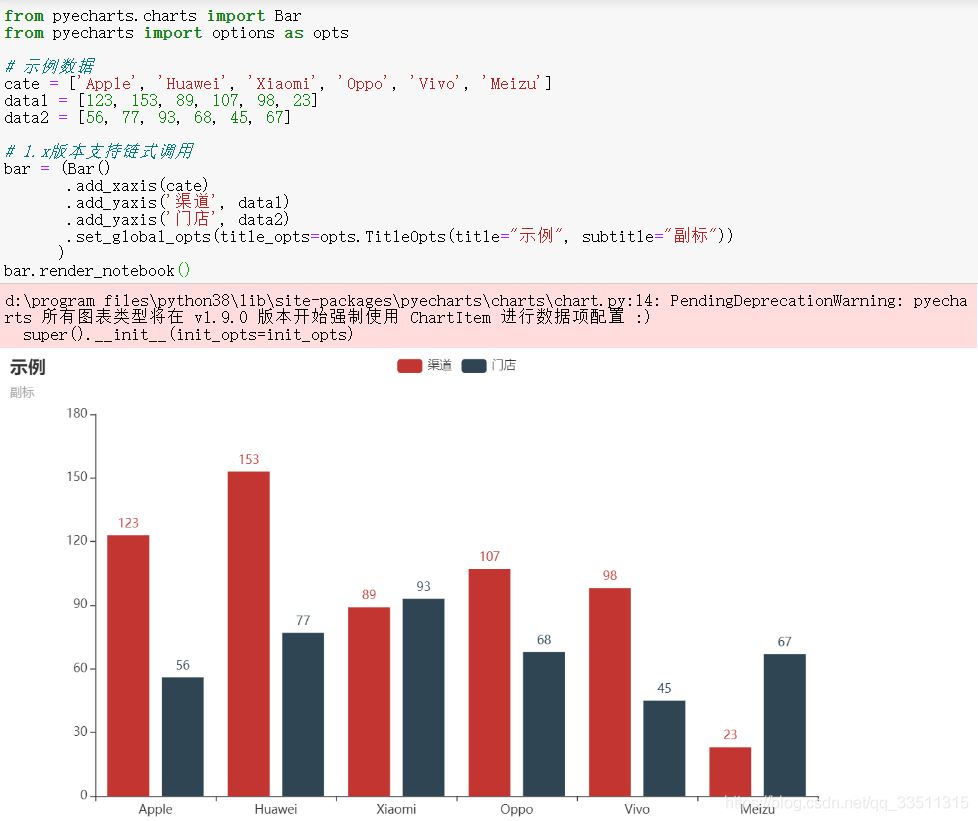
from pyecharts.charts import Bar
from pyecharts import options as opts
# 示例数据
cate = ['Apple', 'Huawei', 'Xiaomi', 'Oppo', 'Vivo', 'Meizu']
data1 = [123, 153, 89, 107, 98, 23]
data2 = [56, 77, 93, 68, 45, 67]
# 1.x版本支持链式调用
bar = (Bar()
.add_xaxis(cate)
.add_yaxis('渠道', data1)
.add_yaxis('门店', data2)
.set_global_opts(title_opts=opts.TitleOpts(title="示例", subtitle="副标"))
)
bar.render_notebook()
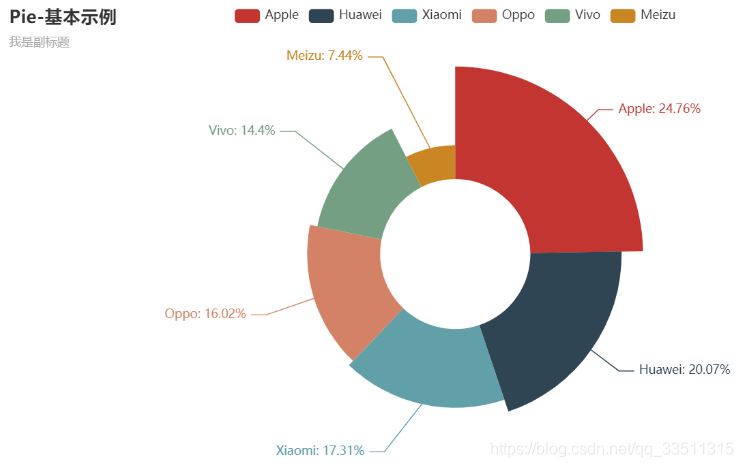
from pyecharts.charts import Pie
from pyecharts import options as opts
# 示例数据
cate = ['Apple', 'Huawei', 'Xiaomi', 'Oppo', 'Vivo', 'Meizu']
data = [153, 124, 107, 99, 89, 46]
pie = (Pie()
.add('', [list(z) for z in zip(cate, data)],
radius=["30%", "75%"],
rosetype="radius")
.set_global_opts(title_opts=opts.TitleOpts(title="Pie-基本示例", subtitle="我是副标题"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
)
pie.render_notebook()
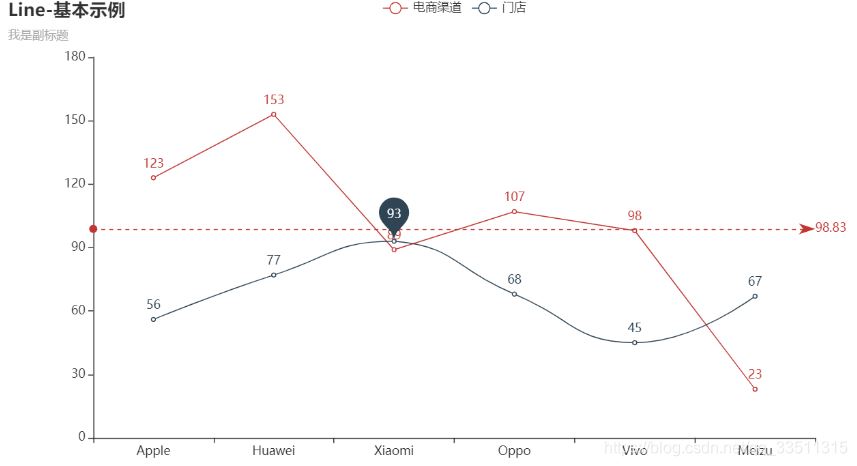
from pyecharts.charts import Line
from pyecharts import options as opts
# 示例数据
cate = ['Apple', 'Huawei', 'Xiaomi', 'Oppo', 'Vivo', 'Meizu']
data1 = [123, 153, 89, 107, 98, 23]
data2 = [56, 77, 93, 68, 45, 67]
"""
折线图示例:
1. is_smooth 折线 OR 平滑
2. markline_opts 标记线 OR 标记点
"""
line = (Line()
.add_xaxis(cate)
.add_yaxis('电商渠道', data1,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]))
.add_yaxis('门店', data2,
is_smooth=True,
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(name="自定义标记点",
coord=[cate[2], data2[2]], value=data2[2])]))
.set_global_opts(title_opts=opts.TitleOpts(title="Line-基本示例", subtitle="我是副标题"))
)
line.render_notebook()
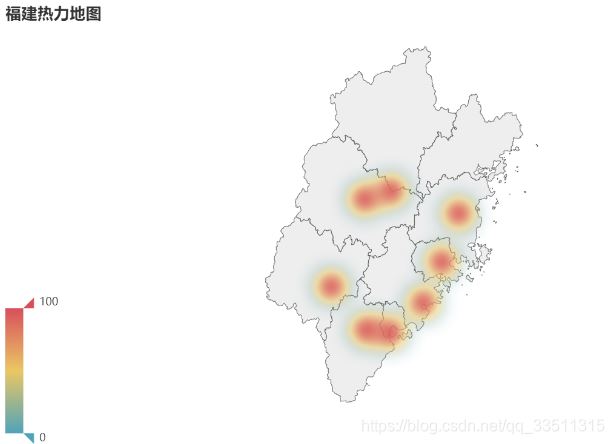
from pyecharts import options as opts
from pyecharts.charts import Geo
from pyecharts.globals import ChartType
import random
province = ['福州市', '莆田市', '泉州市', '厦门市', '漳州市', '龙岩市', '三明市', '南平']
data = [(i, random.randint(200, 550)) for i in province]
geo = (Geo()
.add_schema(maptype="福建")
.add("门店数", data,
type_=ChartType.HEATMAP)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(),
legend_opts=opts.LegendOpts(is_show=False),
title_opts=opts.TitleOpts(title="福建热力地图"))
)
geo.render_notebook()

啊哈这个还访问不了哈
ImportError: Missing optional dependency ‘xlrd'. Install xlrd >= 1.0.0 for Excel support Use pip or conda to install xlrd.


20200822pyecharts+pandas 初步学习
作者今天学习做数据分析,有错误请指出
下面贴出源代码
# 获取数据
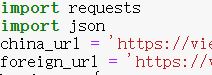
import requests
import json
china_url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'
#foreign_url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_foreign'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36 Edg/84.0.522.59',
'referer': 'https://news.qq.com/zt2020/page/feiyan.htm'
}
#获取json数据
response = requests.get(url=china_url,headers=headers).json()
print(response)
#先将json数据转 python的字典
data = json.loads(response['data'])
#保存数据 这里使用encoding='utf-8' 是因为作者想在jupyter上面看
with open('./国内疫情.json','w',encoding='utf-8') as f:
#再将python的字典转json数据
# json默认中文以ASCII码显示 在这里我们以中文显示 所以False
#indent=2:开头空格2
f.write(json.dumps(data,ensure_ascii=False,indent=2))
转换为json格式输出的文件

# 将json数据转存到Excel中
import pandas as pd
#读取文件
with open('./国内疫情.json',encoding='utf-8') as f:
data = f.read()
#将数据转为python数据格式
data = json.loads(data)
type(data)#字典类型
lastUpdateTime = data['lastUpdateTime']
#获取中国所有数据
chinaAreaDict = data['areaTree'][0]
#获取省级数据
provinceList = chinaAreaDict['children']
# 获取的数据有几个省市和地区
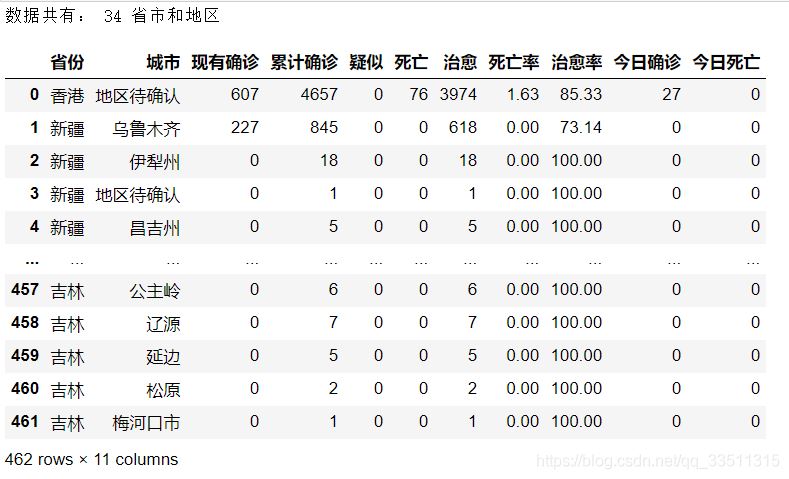
print('数据共有:',len(provinceList),'省市和地区')
#将中国数据按城市封装,例如【{湖北,武汉},{湖北,襄阳}】,为了方便放在dataframe中
china_citylist = []
for x in range(len(provinceList)):
# 每一个省份的数据
province =provinceList[x]['name']
#有多少个市
province_list = provinceList[x]['children']
for y in range(len(province_list)):
# 每一个市的数据
city = province_list[y]['name']
# 累积所有的数据
total = province_list[y]['total']
# 今日的数据
today = province_list[y]['today']
china_dict = {'省份':province,
'城市':city,
'total':total,
'today':today
}
china_citylist.append(china_dict)
chinaTotaldata = pd.DataFrame(china_citylist)
nowconfirmlist=[]
confirmlist=[]
suspectlist=[]
deadlist=[]
heallist=[]
deadRatelist=[]
healRatelist=[]
# 将整体数据chinaTotaldata的数据添加dataframe
for value in chinaTotaldata['total'] .values.tolist():#转成列表
confirmlist.append(value['confirm'])
suspectlist.append(value['suspect'])
deadlist.append(value['dead'])
heallist.append(value['heal'])
deadRatelist.append(value['deadRate'])
healRatelist.append(value['healRate'])
nowconfirmlist.append(value['nowConfirm'])
chinaTotaldata['现有确诊']=nowconfirmlist
chinaTotaldata['累计确诊']=confirmlist
chinaTotaldata['疑似']=suspectlist
chinaTotaldata['死亡']=deadlist
chinaTotaldata['治愈']=heallist
chinaTotaldata['死亡率']=deadRatelist
chinaTotaldata['治愈率']=healRatelist
#拆分today列
today_confirmlist=[]
today_confirmCutlist=[]
for value in chinaTotaldata['today'].values.tolist():
today_confirmlist.append(value['confirm'])
today_confirmCutlist.append(value['confirmCuts'])
chinaTotaldata['今日确诊']=today_confirmlist
chinaTotaldata['今日死亡']=today_confirmCutlist
#删除total列 在原有的数据基础
chinaTotaldata.drop(['total','today'],axis=1,inplace=True)
# 将其保存到excel中
from openpyxl import load_workbook
book = load_workbook('国内疫情.xlsx')
# 避免了数据覆盖
writer = pd.ExcelWriter('国内疫情.xlsx',engine='openpyxl')
writer.book = book
writer.sheets = dict((ws.title,ws) for ws in book.worksheets)
chinaTotaldata.to_excel(writer,index=False)
writer.save()
writer.close()
chinaTotaldata
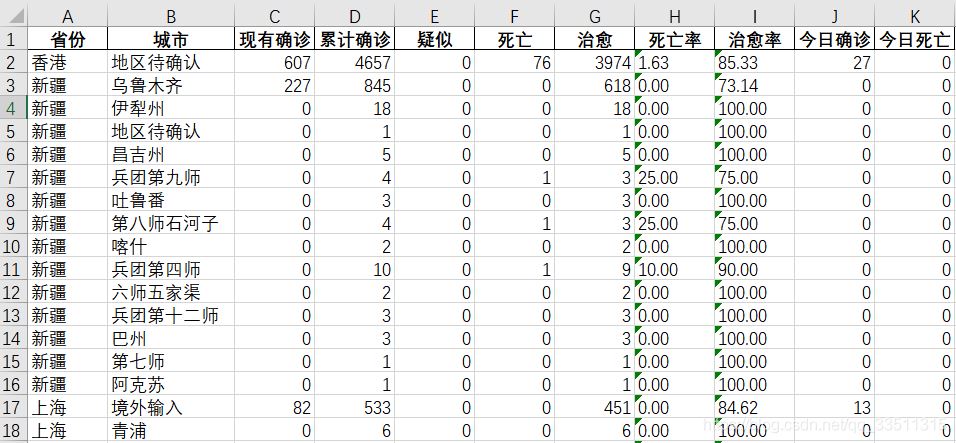
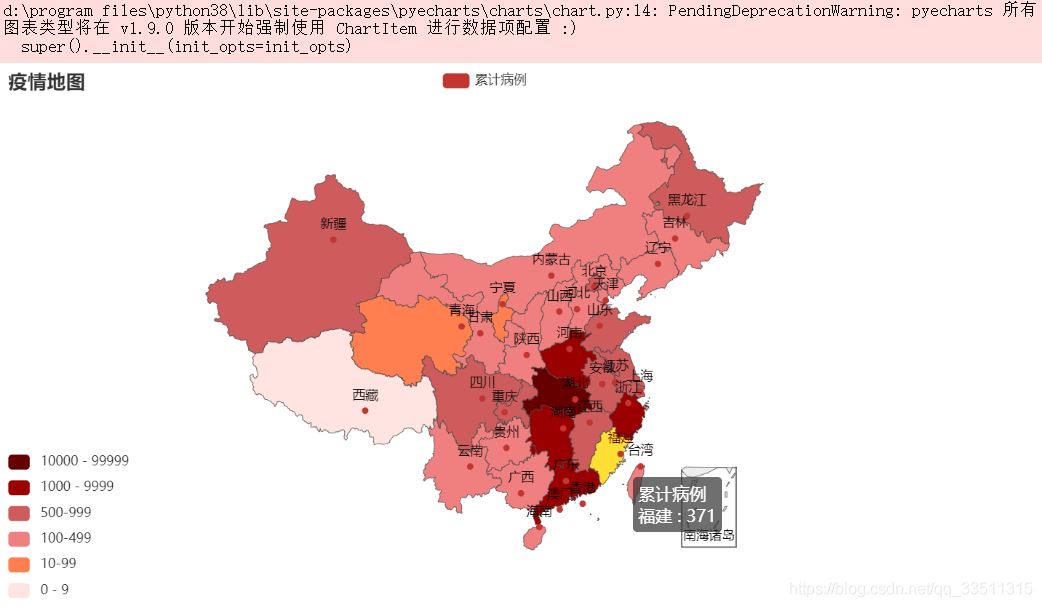
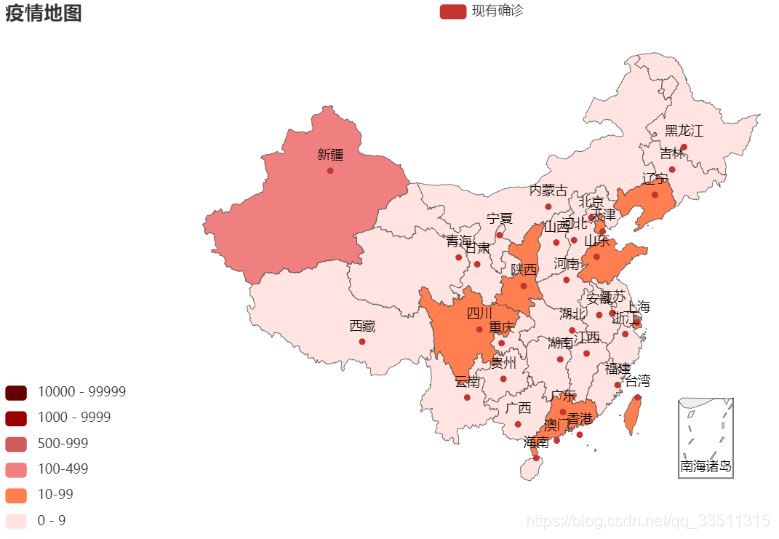
作者这边还有国外的,不过没打算分享出来,大家就看看,总的来说我们国内情况还是非常良好的
到此这篇关于python绘图pyecharts+pandas的使用详解的文章就介绍到这了,更多相关pyecharts pandas使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
安装pyecharts1.8.0版本后导入pyecharts模块绘图时报错: “所有图表类型将在 v1.9.0 版本开始强制使用 ChartItem 进行数据项配置 ”的解决方法
安装pyecharts1.8.0版本后导入pyecharts模块绘图时报错: "所有图表类型将在 v1.9.0 版本开始强制使用 ChartItem 进行数据项配置 "的解决方法; 作者这里可能仅仅只是针对某些情况,希望对你有所帮助! 安装pyecharts: 对于学习大数据可视化萌新来说我们一般都会使用 pip install pyecharts 命令来安装pyecharts包,因为这个pip命令是最简单快捷的方式,但是使用这个命令一般来说默认安装的是最新版本的包. 当我们安装完成后
-

Android系统自带的VPN服务框架实例详解
Android系统自带的VPN服务框架 Android从4.0开始(API LEVEL 15),自己带了一个帮助在设备上建立VPN连接的解决方案,且不需要root权限,本文将对其做一个简单的介绍. 一.基本原理 在介绍如何使用这些新增的API之前,先来说说其基本的原理. android设备上,如果已经使用了VpnService框架,建立起了一条从设备到远端的VPN链接,那么数据包在设备上大致经历了如下四个过程的转换: 1)应用程序使用socket,将相应的数据包发送到真实的网络设备上.一般移动设
-
python绘图pyecharts+pandas的使用详解
pyecharts介绍 pyecharts 是一个用于生成 Echarts 图表的类库.Echarts 是百度开源的一个数据可视化 JS 库.用 Echarts 生成的图可视化效果非常棒 为避免绘制缺漏,建议全部安装 为了避免下载缓慢,作者全部使用镜像源下载过了 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ echarts-countries-pypkg pip install -i https://pypi.tuna.tsin
-
Python pyecharts绘制折线图详解
一.绘制折线图 import seaborn as sns import numpy as np import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt %matplotlib inline plt.rcParams['font.sans-serif']=['Microsoft YaHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False
-
Python pandas常用函数详解
本文研究的主要是pandas常用函数,具体介绍如下. 1 import语句 import pandas as pd import numpy as np import matplotlib.pyplot as plt import datetime import re 2 文件读取 df = pd.read_csv(path='file.csv') 参数:header=None 用默认列名,0,1,2,3... names=['A', 'B', 'C'...] 自定义列名 index_col='
-
Python实现制作销售数据可视化看板详解
目录 1. 数据 2. 网页标题和图标 3. 侧边栏和多选框 4. 主页面信息 5. 主页面图表 6. 隐藏部件 在数据时代,销售数据分析的重要性已无需赘言. 只有对销售数据的准确分析我们才有可能找准数据变动(增长或下滑)的原因. 然后解决问题.发现新的增长点才会成为可能! 今天就给大家介绍一个用Python制作销售数据大屏的方法. 主要使用Python的Streamlit库.Plotly库.Pandas库进行搭建. 其中Pandas处理数据,Plotly制作可视化图表,Streamlit搭建可
-
Python可视化模块altair的使用详解
目录 Altair是啥 Altair初体验 图表的保存 Altair之进阶操作 今天小编来和大家聊一下Python当中的altair可视化模块,并且通过调用该模块来绘制一些常见的图表,借助Altair,我们可以将更多的精力和时间放在理解数据本身以及数据的意义上面,从复杂的数据可视化过程中解脱出来. Altair是啥 Altair被称为是统计可视化库,因为它可以通过分类汇总.数据变换.数据交互.图形复合等方式全面地认识数据.理解和分析数据,并且其安装的过程也是十分的简单,直接通过pip命令来执行,
-
Python可视化绘制图表的教程详解
目录 1.Matplotlib 程序包 2.绘图命令的基本架构及其属性设置 3.Seaborn 模块介绍 3.1 未加Seaborn 模块的效果 4.描述性统计图形概览 4.1制作数据 4.2 频数分析 python 有许多可视化工具,但本书只介绍Matplotlib.Matplotlib是一种2D的绘图库,它可以支持硬拷贝和跨系统的交互,它可以在python脚本,IPython的交互环境下.Web应用程序中使用.该项目是由John Hunter 于2002年启动,其目的是为python构建MA
-
Python Matplotlib数据可视化模块使用详解
目录 前言 1 matplotlib 开发环境搭建 2 绘制基础 2.1 绘制直线 2.2 绘制折线 2.3 设置标签文字和线条粗细 2.4 绘制一元二次方程的曲线 y=x^2 2.5 绘制正弦曲线和余弦曲线 3 绘制散点图 4 绘制柱状图 5 绘制饼状图 6 绘制直方图 7 绘制等高线图 8 绘制三维图 总结 本文主要介绍python 数据可视化模块 Matplotlib,并试图对其进行一个详尽的介绍. 通过阅读本文,你可以: 了解什么是 Matplotlib 掌握如何用 Matplotlib
-
使用python来玩一次股票代码详解
目录 准备工作 获取数据部分 爬虫的基本流程 代码实现 发送请求 获取数据 解析数据 保存数据 准备工作 我们需要使用这些模块,通过pip安装即可. 后续使用的其它的模块都是Python自带的, 不需要安装,直接导入使用即可. requests: 爬虫数据请求模块 pyecharts: 数据分析 可视化模块 pandas: 数据分析 可视化模块里面的设置模块(图表样式) 获取数据部分 爬虫的基本流程 思路分析 采集什么数据?怎么采集? 首先我们找到数据来源 代码实现 我们想要实现通过爬虫获取到数
-
matplotlib在python上绘制3D散点图实例详解
大家可以先参考官方演示文档: 效果图: ''' ============== 3D scatterplot ============== Demonstration of a basic scatterplot in 3D. ''' from mpl_toolkits.mplot3d import Axes3D import matplotlib.pyplot as plt import numpy as np def randrange(n, vmin, vmax): ''' Helper f
-
VTK与Python实现机械臂三维模型可视化详解
三维可视化系统的建立依赖于三维图形平台, 如 OpenGL.VTK.OGRE.OSG等, 传统的方法多采用OpenGL进行底层编程,即对其特有的函数进行定量操作, 需要开发人员熟悉相关函数, 从而造成了开发难度大. 周期长等问题.VTK. ORGE.OSG等平台使用封装更好的函数简化了开发过程.下面将使用Python与VTK进行机器人上位机监控界面的快速原型开发. 完整的上位机程序需要有三维显示模块.机器人信息监测模块(位置/角度/速度/电量/温度/错误信息...).通信模块(串口/USB/WI