python UDF 实现对csv批量md5加密操作
工作上遇到需求,一批手机号要md5加密导出。为了保证数据安全,所以没有采用网上工具来加密。
md5的加密算法是开源的且成熟的,很多语言都有对应包可以直接用,我写了一个简单的python来实现,另一位同事做了一个hiveUDF来实现,这里都给大家分享一下。
目标:
读取csv文件,并且对其中的内容进行md5加密,32位加密,将加密后的密文存入另一个csv文件。
python实现:
(1)准备好要读取的csv文件。单列,一行存一个手机号码。
(2)python代码:
#encoding=utf8
import hashlib #加密模块
import os
#定义一个加密函数,32位md5加密
def md5_encryption(str):
m=hashlib.md5()
m.update(str)
return m.hexdigest()
#准备要读取的csv和要被写入的csv,两个文件要和此python放在同一个文件夹里
readfilename=os.path.join(os.path.dirname(__file__),"testcsv.csv")
writefilename=os.path.join(os.path.dirname(__file__),"writecsv.csv")
print('read:',readfilename)
print('write:',writefilename)
with open(readfilename,'r') as rf:
#逐行写入加密后的密文,strip函数用于剔除换行符\n,不然是对“13000000\n”加密而不是对“13000000”加密
with open(writefilename,'w') as wf:
for row in rf.readlines():
wf.write(md5_encryption(row.strip()))
wf.write('\n')
#计算一下写入的行数
with open(writefilename,'r') as rwf:
count=0
while 1:
buffer=rwf.read(1024*8192)
if not buffer:
break
count+=buffer.count('\n')
print('line writed number:',count)
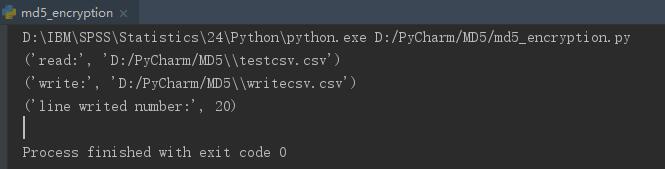
(3)结果

hive UDF 实现:
(1)用java写一个类用来实现加密,用maven打成jar包
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.commons.lang.StringUtils;
import java.security.MessageDigest;
public class MD5 extends UDF {
public String evaluate (final String str) {
if (StringUtils.isBlank(str)){
return "";
}
String digest = null;
StringBuffer buffer = new StringBuffer();
try {
MessageDigest digester = MessageDigest.getInstance("md5");
byte[] digestArray = digester.digest(str.getBytes("UTF-8"));
for (int i = 0; i < digestArray.length; i++) {
buffer.append(String.format("%02x", digestArray[i]));
}
digest = buffer.toString();
} catch (Exception e) {
e.printStackTrace();
}
return digest;
}
public static void main (String[] args ) {
MD5 md5 = new MD5();
System.out.println(md5.evaluate(" "));
}
}
(2)配置一下pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>HiveUdf</groupId> <artifactId>HiveUdf</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>0.14.0</version> </dependency> <dependency> <groupId>org.apache.calcite</groupId> <artifactId>calcite-core</artifactId> <version>0.9.2-incubating</version> </dependency> <dependency> <groupId>org.apache.calcite</groupId> <artifactId>calcite-avatica</artifactId> <version>0.9.2-incubating</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.0</version> </dependency> </dependencies> </project>
(3)hive中配置udf
导入jar包:
hive> add jar hdfs:/user/udf/HiveUdf-1.0-SNAPSHOT.jar;
新建一个函数:
hive> create temporary function MD5 as 'MD5';
使用:
hive> select MD5('12345');
OK
827ccb0eea8a706c4c34a16891f84e7b
Time taken: 0.139 seconds, Fetched: 1 row(s)
hive>
hive> select phone,MD5(phone) from mid_latong_20200414 limit 5;
OK
1300****436 856299f44928e90****181b0cc1758c4
1300****436 856299f44928e90****181b0cc1758c4
1300****689 771dfa9ef00f43c****4901a3f1d1fa0
1300****689 771dfa9ef00f43c****4901a3f1d1fa0
1300****689 771dfa9ef00f43c****4901a3f1d1fa0
Time taken: 0.099 seconds, Fetched: 5 row(s)
以上就是python和hiveUDF两种实现md5加密的方法啦!
补充:python的MD5加密的一点坑
曾经在做某ctf题目时,被这点坑,坑了好久。
废话不多说,进入正题。
python MD5加密方法
import hashlib //导入hash库函数 text = "bolg.csdn.net" //要加密的文本 md5_object = hashlib.md5() //创建一个MD5对象 md5_object.update(text) //添加去要加密的文本 print md5_object.hexdigest() //输出加密后的MD5值
坑在哪?
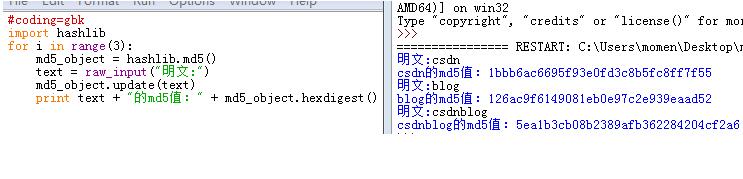
当你在进行第一次加密时,程序正常输出MD5值,但是在同一程序中进行第二次明文加密时,如果你的代码是这样写,就不会得到正确的MD5值。
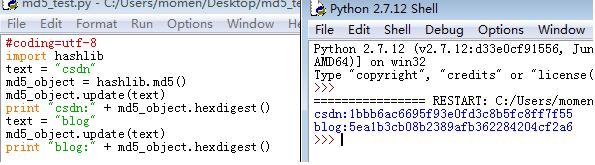
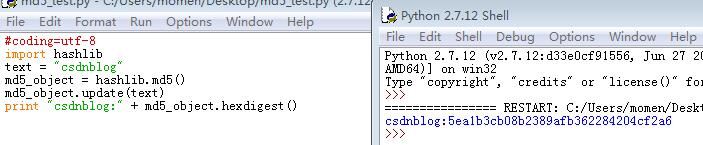
通过对第一张图片和第二张图片的比较,发现如果按照第一张图片的代码进行连续加密时,它实质上是在加密每次明文的叠加。
即第一次加密:csdn
第二次加密:csdnblog
正确做法应该是:
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
用python计算文件的MD5值
md5是一种常见不可逆加密算法,使用简单,计算速度快,在很多场景下都会用到,比如:给用户上传的文件命名,数据库中保存的用户密码,下载文件后检验文件是否正确等.下面讲解在python中如何使用md5算法. 一.计算字符串的md5值 #!/usr/bin/env python # -*- coding: utf-8 -*- import sys import hashlib reload(sys) sys.setdefaultencoding('utf-8') if __name__ == '__m
-
python计算Content-MD5并获取文件的Content-MD5值方式
1.首先计算MD5加密的二进制数组(128位),然后再对这个二进制数组进行base64编码(而不是对32位字符串编码). 例如,用Python计算0123456789的Content-MD5,主要代码如下: import base64, hashlib hash = hashlib.md5() hash.update("0123456789") base64.b64encode(hash.digest()) 这样就生成了 'eB5eJF1ptWaXm4bijSPyxw==' 的Cont
-
python MD5加密的示例
什么是MD5 Message Digest Algorithm MD5(中文名为消息摘要算法第五版)为计算机安全领域广泛使用的一种散列函数,用以提供消息的完整性保护.该算法的文件号为RFC 1321(R.Rivest,MIT Laboratory for Computer Science and RSA Data Security Inc. April 1992). MD5即Message-Digest Algorithm 5(信息-摘要算法5),用于确保信息传输完整一致.是计算机广泛使用的杂凑
-
详解python实现可视化的MD5、sha256哈希加密小工具
本文主要介绍了详解python实现可视化的MD5.sha256哈希加密小工具,分享给大家,具体如下: 效果图: 刚启动的状态 输入文本.触发加密按钮后支持复制 超过十条不全量显示 代码 import hashlib import tkinter as tk #窗口控制 windowss=tk.Tk() windowss.title('Python_md5')#窗口title,并非第一行 windowss.geometry('820x550') windowss.resizable(width=T
-

如何利用python生成MD5并去重
给每个文件生成一个MD5值,来对文件进行加密,是常用的文件校验方法,但是MD5的缺陷就是不能防止碰撞, 所以不同文件生成的MD5可能是相同的,因此就需要进行去重操作. 为方便演示,我用txt文件代替文件夹,用txt文件中的字符串代替文件夹中文件来生成MD5值并进行去重操作. 每个txt文件中有字符串,用于生成MD5值: 然后用代码生成MD5值并输出为文件,打印了一下字符串的数量和MD5的数量,两者是相同的: 生成的MD5文件内容就是128位的MD5值,每个值一行: 接下来对这些MD5进行去重操作
-
Python实现常见的几种加密算法(MD5,SHA-1,HMAC,DES/AES,RSA和ECC)
生活中我们经常会遇到一些加密算法,今天我们就聊聊这些加密算法的Python实现.部分常用的加密方法基本都有对应的Python库,基本不再需要我们用代码实现具体算法. MD5加密 全称:MD5消息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致.md5加密算法是不可逆的,所以解密一般都是通过暴力穷举方法,通过网站的接口实现解密.Python代码: i
-
Python常用base64 md5 aes des crc32加密解密方法汇总
1.base64 Python内置的base64模块可以实现base64.base32.base16.base85.urlsafe_base64的编码解码,python 3.x通常输入输出都是二进制形式,2.x可以是字符串形式. base64模块的base64编码.解码调用了binascii模块,binascii模块中的b2a_base64()函数用于base64编码,binascii模块中的a2b_base64()函数用于base64解码. >>>import base64 >&
-
python UDF 实现对csv批量md5加密操作
工作上遇到需求,一批手机号要md5加密导出.为了保证数据安全,所以没有采用网上工具来加密. md5的加密算法是开源的且成熟的,很多语言都有对应包可以直接用,我写了一个简单的python来实现,另一位同事做了一个hiveUDF来实现,这里都给大家分享一下. 目标: 读取csv文件,并且对其中的内容进行md5加密,32位加密,将加密后的密文存入另一个csv文件. python实现: (1)准备好要读取的csv文件.单列,一行存一个手机号码. (2)python代码: #encoding=utf8 i
-
python实现对csv文件的列的内容读取
以下代码测试在python2.7 mac上运行成功 import csv with open('/Users/wangzhao/Downloads/test.csv', 'U') as csvfile: reader = csv.DictReader(csvfile) column = [row['Employee Name'] for row in reader] print column import csv with open('/Users/wangzhao/Downloads/test
-
Python实现对PPT文件进行截图操作的方法
本文实例讲述了Python实现对PPT文件进行截图操作的方法.分享给大家供大家参考.具体分析如下: 下面的代码可以为powerpoint文件ppt进行截图,可以指定要截取的幻灯片页面,需要本机安装了powerpoint,可以指定截图的大小分辨率 import os import comtypes.client def export_presentation(path_to_ppt, path_to_folder): if not (os.path.isfile(path_to_ppt) and
-
C# 实现对PPT文档加密、解密及重置密码的操作方法
工作中我们会使用到各种各样的文档,其中,PPT起着不可或缺的作用.一份PPT文档里可能包含重要商业计划.企业运营资料或者公司管理资料等.因此,在竞争环境里,企业重要资料的保密工作就显得尤为重要,而对于重要资料我们可以选择添加密码的形式来进行文档保护.本文将介绍如何通过C#来给PPT添加密码,当然你也可以根据需要来修改密码或者解除密码.下面将对三种操作方法进行具体讲述. 所用工具: Spire.Presentation for. NET Visual Studio 2013 工具使用说明:Spir
-
在python中实现对list求和及求积
如下所示: # the basic way s = 0 for x in range(10): s += x # the right way s = sum(range(10)) # the basic way s = 1 for x in range(1, 10): s *= x # the other way from operator import mul reduce(mul, range(1, 10)) 以上这篇在python中实现对list求和及求积就是小编分享给大家的全部内容了,希
-
Python+Selenium实现在Geoserver批量发布Mongo矢量数据
目录 一.安装 Selenium和ChromeDriver 二.安装Geoserver必要插件 三.关于Selenium中XPath的使用技巧 四.脚本编写 首先,声明一下,这里我完成的脚步属于半自动化的,我戏称它为“有监督的半自动化”脚本.具体原因后面会详细说明. 一.安装 Selenium和ChromeDriver 安装Selenium: pip install selenium 安装ChromeDriver ChromeDriver下载地址:chromedirver. 注意:下载的版本号要
-
java实现对map的字典序排序操作示例
本文实例讲述了java实现对map的字典序排序操作.分享给大家供大家参考,具体如下: java中对map的字典序排序,算法验证比对微信官网https://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1421141115&token=&lang=zh_CN,搜索关键字"附录1-JS-SDK使用权限签名算法" import java.util.ArrayList; import java.util.Collectio
-
ASP语言实现对SQL SERVER数据库的操作
目前管理信息系统已从传统的客户机/服务器(C/S)模式转向了浏览器/服务器(B/S)模式,特别是微软公司推出它的新产品ASP语言之后,这种转变更加迅猛.管理信息系统的核心是对数据库进行包括添加.修改和查询等等操作,ASP提供的ADO数据库接口控件,使得程序员再也勿需编写复杂的CGI程序了,而只要用几句简单的语句即可实现以上操作.1.系统环境 PII 350,Ram 64M,WINNT Server 4.0, Service Pack4, IIS 4.0, SQL Server7.0. 2.系统功
-
express+mongoose实现对mongodb增删改查操作详解
本文实例讲述了express+mongoose实现对mongodb增删改查操作.分享给大家供大家参考,具体如下: 项目地址:https://github.com/jrainlau/mongoose_crud 写在开头 本文主要分享我如何使用express+mongoose对mongodb实现增删改查操作,感谢cnode社区所有精品文章的帮助,以及@airuikun的开源项目airuikun/mongoose_crud对我的启发. 学习nodejs已经小半个月了,一直琢磨着做一些什么东西出来.由于
-
Java使用jdbc连接实现对MySQL增删改查操作的全过程
目录 1.新建项目 2.添加jar包 3.jdbc的连接 4.简单的MySQL增删改查操作 总结 1.新建项目 新建一个项目,fileànewàproject如下图: 选择Javaà下一步,如下图:(注意如果jdk推荐使用jdk1.8版本哦,如果不是可以在project SDK中更换,Add JDK,找到自己电脑上放JDK1.8的地方,没有的话自行下载哦) 继续下一步 创建项目名字(自己起就行,注意项目名不要大写),找一个存放的地址,也自己决定就行. 2.添加jar包 一般默认位置是在如下位置: