Python celery原理及运行流程解析
celery简介
celery是一个基于分布式消息传输的异步任务队列,它专注于实时处理,同时也支持任务调度。它的执行单元为任务(task),利用多线程,如Eventlet,gevent等,它们能被并发地执行在单个或多个职程服务器(worker servers)上。任务能异步执行(后台运行)或同步执行(等待任务完成)。
在生产系统中,celery能够一天处理上百万的任务。它的完整架构图如下:
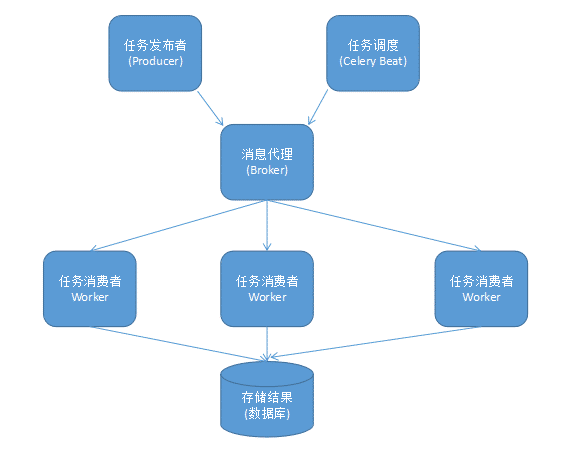
组件介绍:
- Producer:调用了Celery提供的API、函数或者装饰器而产生任务并交给任务队列处理的都是任务生产者。
- Celery Beat:任务调度器,Beat进程会读取配置文件的内容,周期性地将配置中到期需要执行的任务发送给任务队列。
- Broker:消息代理,又称消息中间件,接受任务生产者发送过来的任务消息,存进队列再按序分发给任务消费方(通常是消息队列或者数据库)。Celery目前支持RabbitMQ、Redis、MongoDB、Beanstalk、SQLAlchemy、Zookeeper等作为消息代理,但适用于生产环境的只有RabbitMQ和Redis, 官方推荐 RabbitMQ。
- Celery Worker:执行任务的消费者,通常会在多台服务器运行多个消费者来提高执行效率。
- Result Backend:任务处理完后保存状态信息和结果,以供查询。Celery默认已支持Redis、RabbitMQ、MongoDB、Django ORM、SQLAlchemy等方式。
工作原理
它的基本工作就是管理分配任务到不同的服务器,并且取得结果。至于说服务器之间是如何进行通信的?这个Celery本身不能解决。所以,RabbitMQ作为一个消息队列管理工具被引入到和Celery集成,负责处理服务器之间的通信任务。和rabbitmq的关系只是在于,celery没有消息存储功能,他需要介质,比如rabbitmq、redis、mysql、mongodb 都是可以的。推荐使用rabbitmq,他的速度和可用性都很高。
Celery安装及使用
1、安装celery
pip install celery
2、查看完整可用命令选项
celery worker --help
3、创建一个工程项目project,然后再项目内创建一个celery_tasks异步任务列表。如图:
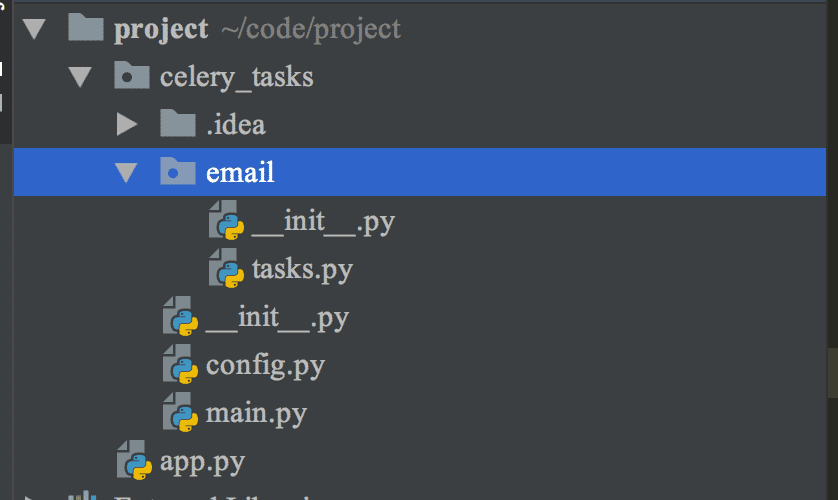
4、首先是celery_tasks异步任务主程序main.py,代码如下:
from celery import Celery
# 生成celery应用
celery_app = Celery("caicai")
# 加载配置文件
celery_app.config_from_object('celery_tasks.config')
# 注册任务
celery_app.autodiscover_tasks(['celery_tasks.email']) # 注意:传递的参数是任务列表
分析一下这个程序:
- "from celery import Celery"是导入celery中的Celery类。celery_app
- celery_app是Celery类的实例。
- 把Celery配置存放进project/config.py文件,使用celery_app.config_from_object加载配置。
- 将任务注册到应用中
5、接着是配置文件config.py,代码如下:
BROKER_URL = 'redis://localhost:6379/1' # 使用Redis作为消息代理 CELERY_RESULT_BACKEND = 'redis://localhost:6379/0' # 把任务结果存在了Redis # CELERY_TASK_SERIALIZER = 'msgpack' # 任务序列化和反序列化使用msgpack方案 CELERY_RESULT_SERIALIZER = 'json' # 读取任务结果一般性能要求不高,所以使用了可读性更好的JSON CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24 # celery任务结果有效期 CELERY_ACCEPT_CONTENT = ['json', 'msgpack'] # 指定接受的内容类型 CELERY_TIMEZONE = 'Asia/Shanghai' # celery使用的时区 CELERY_ENABLE_UTC = True # 启动时区设置 CELERYD_LOG_FILE = "/var/log/celery/celery.log" # celery日志存储位置
6、创建email目录,目录下创建tesks.py文件用来编写发送邮件的代码,代码如下:
import time from celery_tasks.main import celery_app @celery_app.task(name='seed_email') # 添加celery_app.task这个装饰器,指定该任务的任务名name='seed_email' def seed(): time.sleep(1) return "我将发送邮件"
7、在项目app.py中,采用delay()用来调用任务。
from celery_tasks.email.tasks import seed seed.delay() seed.delay() seed.delay() seed.delay() seed.delay()
8、项目运行
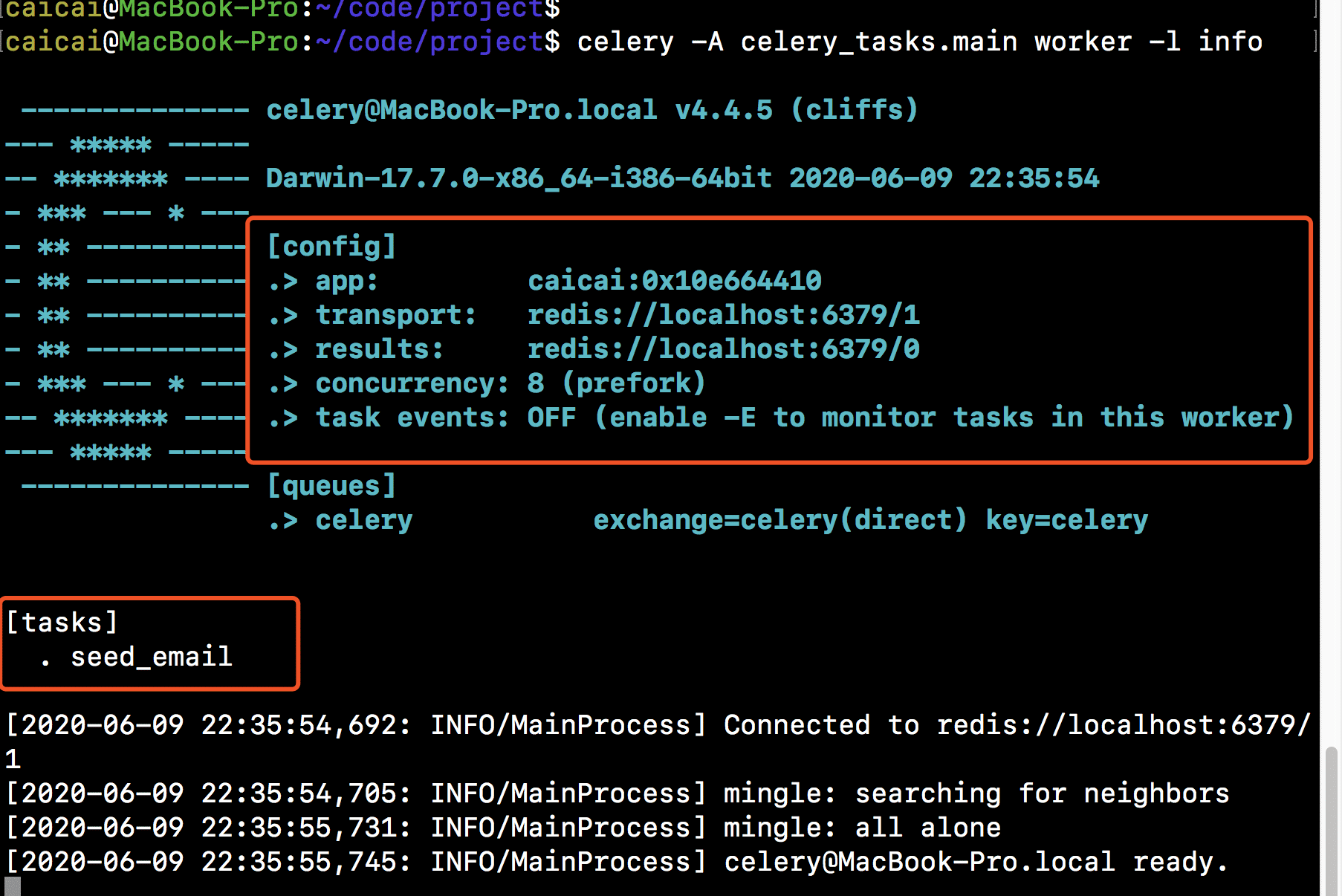
首先,我们需要启动redis。接着,切换至proj项目所在目录,并运行命令:
celery -A celery_tasks.main worker -l info
界面如下:
然后,我们运行app.py,app.py调用添加异步任务,输出的结果如下:


以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python环境下安装使用异步任务队列包Celery的基础教程
1.简介 celery(芹菜)是一个异步任务队列/基于分布式消息传递的作业队列.它侧重于实时操作,但对调度支持也很好. celery用于生产系统每天处理数以百万计的任务. celery是用Python编写的,但该协议可以在任何语言实现.它也可以与其他语言通过webhooks实现. 建议的消息代理RabbitMQ的,但提供有限支持Redis, Beanstalk, MongoDB, CouchDB, ,和数据库(使用SQLAlchemy的或Django的 ORM) . celery是易于集成Dja
-

python Celery定时任务的示例
本文介绍了python Celery定时任务的示例,分享给大家,具体如下: 配置 启用Celery的定时任务需要设置CELERYBEAT_SCHEDULE . Celery的定时任务都由celery beat来进行调度.celery beat默认按照settings.py之中的时区时间来调度定时任务. 创建定时任务 一种创建定时任务的方式是配置CELERYBEAT_SCHEDULE: #每30秒调用task.add from datetime import timedelta CELERYBEA
-
在RedHat系Linux上部署Python的Celery框架的教程
Celery (芹菜)是基于Python开发的分布式任务队列.它支持使用任务队列的方式在分布的机器/进程/线程上执行任务调度. 架构设计 Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成. 1. 消息中间件 Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成.包括,RabbitMQ, Redis, MongoDB (experimental), Amazon
-
Python Celery多队列配置代码实例
这篇文章主要介绍了Python Celery多队列配置代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Celery官方文档 项目结构 /proj -__init__ -app.py #实例化celery对象 -celeryconfig.py #celery的配置文件 -tasks.py #celery编写任务文件 app.py #coding:utf-8 from __future__ import absolute_import fr
-
Python Django2.0集成Celery4.1教程
环境准备 Python3.6 pip install Django==2.0.1 pip install celery==4.1.0 pip install eventlet (加入协程支持) 安装erlang和rabbitMQ-server 配置settings.py文件 在settings.py文件中添加如下内容 ... LANGUAGE_CODE = 'zh-hans' TIME_ZONE = 'Asia/Shanghai' USE_I18N = True USE_L10N = True
-
python使用celery实现异步任务执行的例子
使用celery在django项目中实现异步发送短信 在项目的目录下创建celery_tasks用于保存celery异步任务. 在celery_tasks目录下创建config.py文件,用于保存celery的配置信息 ```broker_url = "redis://127.0.0.1/14"``` 在celery_tasks目录下创建main.py文件,用于作为celery的启动文件 from celery import Celery # 为celery使用django配置文件进行
-
python celery分布式任务队列的使用详解
一.Celery介绍和基本使用 Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理, 如果你的业务场景中需要用到异步任务,就可以考虑使用celery, 举几个实例场景中可用的例子: 你想对100台机器执行一条批量命令,可能会花很长时间 ,但你不想让你的程序等着结果返回,而是给你返回 一个任务ID,你过一段时间只需要拿着这个任务id就可以拿到任务执行结果, 在任务执行ing进行时,你可以继续做其它的事情. 你想做一个定时任务,比如每天检测一下你们
-
Python并行分布式框架Celery详解
Celery 简介 除了redis,还可以使用另外一个神器---Celery.Celery是一个异步任务的调度工具. Celery 是 Distributed Task Queue,分布式任务队列,分布式决定了可以有多个 worker 的存在,队列表示其是异步操作,即存在一个产生任务提出需求的工头,和一群等着被分配工作的码农. 在 Python 中定义 Celery 的时候,我们要引入 Broker,中文翻译过来就是"中间人"的意思,在这里 Broker 起到一个中间人的角色.在工头提
-
Python celery原理及运行流程解析
celery简介 celery是一个基于分布式消息传输的异步任务队列,它专注于实时处理,同时也支持任务调度.它的执行单元为任务(task),利用多线程,如Eventlet,gevent等,它们能被并发地执行在单个或多个职程服务器(worker servers)上.任务能异步执行(后台运行)或同步执行(等待任务完成). 在生产系统中,celery能够一天处理上百万的任务.它的完整架构图如下: 组件介绍: Producer:调用了Celery提供的API.函数或者装饰器而产生任务并交给任务队列处理的
-
Openstack各组件逻辑关系及运行流程解析
目录 各组件逻辑关系图 Openstack 新建云主机流程图 虚拟机启动过程 各组件逻辑关系图 Keystone:认证服务 Glance:镜像服务 Nova:计算服务 Neutron:网络服务 Cinder:存储服务 Horizon:web 界面 Cellometer:监控计费 Swit:对象存储 Heat:编排服务(通过剧本,批量部署虚拟机) Openstack 新建云主机流程图 keystone 身份认证 填写创建云主机的相关配置–> nova-api --> 将相关信息保存到 MySQL
-
Python Django源码运行过程解析
目录 一.Django运行顺序 1.启动 1.1 命令行启动(测试服务器) 2.监听 2.1 runserver(测试服务器) 3.中间件的执行 本文只算是本人片面之言(当然也会借鉴网络上公开资料),而且技术含量比较低,内容质量也一般,大家仅限参考即可 如果对本文看不太懂,请先阅读后面文章,等都差不多看完再回顾来看 一.Django运行顺序 WSGI会不断监听客户端发送来的请求 先经过中间件进行分析验证处理 然后经过url分发与验证 视图层进行处理 再经过中间件进行分析验证处理 返回响应内容 1
-
深入解析Session工作原理及运行流程
一.session的概念及特点 session概念:在计算机中,尤其是在网络应用中,称为"会话控制".Session 对象存储特定用户会话所需的属性及配置信息.说白了session就是一种可以维持服务器端的数据存储技术.session主要有以下的这些特点: session保存的位置是在服务端 session一般来说要配合cookie使用,如果用户浏览器禁用了cookie,那么只能使用URL重写来实现session的存储功能 单纯的使用session来存储用户回话信息,那么当用户量较多时
-
Python threading模块condition原理及运行流程详解
Condition的处理流程如下: 首先acquire一个条件变量,然后判断一些条件. 如果条件不满足则wait: 如果条件满足,进行一些处理改变条件后,通过notify方法通知其他线程,其他处于wait状态的线程接到通知后会重新判断条件. 不断的重复这一过程,从而解决复杂的同步问题. Condition的基本原理如下: 可以认为Condition对象维护了一个锁(Lock/RLock)和一个waiting池.线程通过acquire获得Condition对象,当调用wait方法时,线程会释放Co
-
Python Celery异步任务队列使用方法解析
Celery是一个异步的任务队列(也叫做分布式任务队列),一个简单,灵活,可靠的分布式系统,用于处理大量消息,同时为操作提供维护此类系统所需要的工具. celery的优点 1:简单,容易使用,不需要配置文件 2:高可用,任务执行失败或执行过程中发生连续中断,celery会自动尝试重新执行任务 3:快速,一个单进程的celery每分钟可以处理上百万个任务 4:灵活,几乎celery的各个组件都可以被扩展 celery应用场景 1:异步发邮件,一般发邮件等比较耗时的操作,这个时候需要提交任务给cel
-
JavaScript构造函数原理及实现流程解析
在学习构造函数之前我们需要知道我们学习构造函数需要学习什么: 1.什么是构造函数 2.构造函数用来做什么 3.构造函数的执行过程 4.构造函数的返回值 1.所以首先我们需要知道什么是构造函数: 在我看来,构造函数具有两个特点可以判断是否为构造函数: 1.当函数名为首字母大写时,这个是一个可以大概判断构造函数与普通函数的一个特点,但是不是绝对正确,因为普通函数也可以是大写字母开头 2.当我们需要调用构造函数时我们需要new <构造函数>,也就是产生一个实例化对象. function Studen
-
SpringMVC拦截器配置及运行流程解析
1.与过滤器filter的区别 2.springMVC中拦截器的必须实现的三个方法: 3. 拦截器类的编写: package com.imooc.core; import com.imooc.bean.User; import org.springframework.web.servlet.HandlerInterceptor; import org.springframework.web.servlet.ModelAndView; import javax.servlet.http.HttpS
-
Python爬虫程序架构和运行流程原理解析
1 前言 Python开发网络爬虫获取网页数据的基本流程为: 发起请求 通过URL向服务器发起request请求,请求可以包含额外的header信息. 获取响应内容 服务器正常响应,将会收到一个response,即为所请求的网页内容,或许包含HTML,Json字符串或者二进制的数据(视频.图片)等. 解析内容 如果是HTML代码,则可以使用网页解析器进行解析,如果是Json数据,则可以转换成Json对象进行解析,如果是二进制的数据,则可以保存到文件做进一步处理. 保存数据 可以保存到本地文件,也
-
python manage.py runserver流程解析
这篇文章主要介绍了python manage.py runserver流程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 版本 python27 django 1.0 搭建可运行的环境 创建python27 虚拟环境 github 下载 django-1.0.tar.gz(1.0 版本的django) 解压 可以看到,有个 demo 在 examples 目录 把 django 目录拷贝到 examples 下面,这样 example 可以