Java并发编程之ConcurrentLinkedQueue源码详解
一、ConcurrentLinkedQueue介绍
并编程中,一般需要用到安全的队列,如果要自己实现安全队列,可以使用2种方式:
方式1:加锁,这种实现方式就是我们常说的阻塞队列。
方式2:使用循环CAS算法实现,这种方式实现队列称之为非阻塞队列。
从点到面, 下面我们来看下非阻塞队列经典实现类:ConcurrentLinkedQueue (JDK1.8版)
ConcurrentLinkedQueue 是一个基于链接节点的无界线程安全的队列。当我们添加一个元素的时候,它会添加到队列的尾部,当我们获取一个元素时,它会返回队列头部的元素。它采用了“wait-free”算法来实现,用CAS实现了非阻塞的线程安全队列。当多个线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。此队列不允许使用 null 元素,因为移除元素时实际是将节点中item置为null,如果元素本身为null,则跟删除有冲突
我们首先看一下ConcurrentLinkedQueue的类图结构先,好有一个内部逻辑有一个大概的印象,如下图所示:
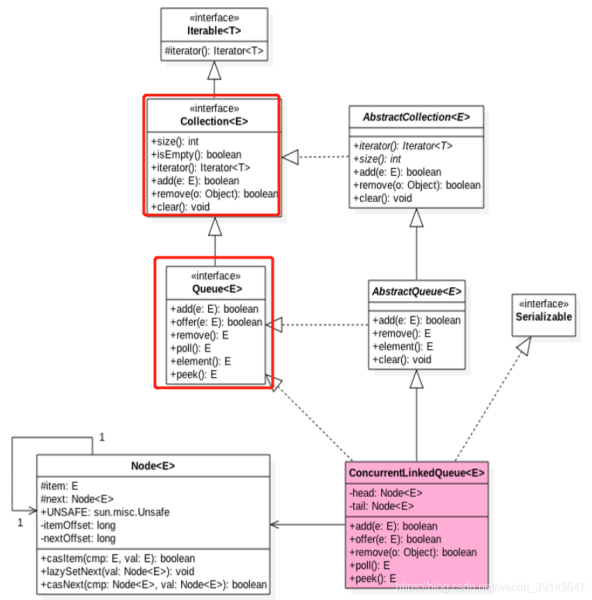
主要属性head节点,tail节点
// 链表头节点 private transient volatile Node<E> head; // 链表尾节点 private transient volatile Node<E> tail;
主要内部类Node
类Node在static方法里获取到item和next的内存偏移量,之后通过casItem和casNext更改item值和next节点
private static class Node<E> {
volatile E item;
volatile Node<E> next;
/**
* Constructs a new node. Uses relaxed write because item can
* only be seen after publication via casNext.
*/
Node(E item) {
//将item存放在本节点的itemOffset偏移量位置的内存里
UNSAFE.putObject(this, itemOffset, item);//设置this对象的itemoffset位置
}
//更新item值
boolean casItem(E cmp, E val) {
//this对象的itemoffset位置存放的值如果和期望值cmp相等,则替换为val
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
//this对象的nextOffset位置存入val
UNSAFE.putOrderedObject(this, nextOffset, val);
}
//更新next节点值
boolean casNext(Node<E> cmp, Node<E> val) {
//this对象的nextOffset位置存放的值如果和期望值cmp相等,则替换为val
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
//当前节点存放的item的内存偏移量
private static final long itemOffset;
//当前节点的next节点的内存偏移量
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
concurrentlinkedqueue同样在static方法里获取到head和tail的内存偏移量:之后通过casHead和casTail更改head节点和tail节点值
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentLinkedQueue.class;
headOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("head"));
tailOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("tail"));
} catch (Exception e) {
throw new Error(e);
}
}
private boolean casTail(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, tailOffset, cmp, val);
}
private boolean casHead(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, headOffset, cmp, val);
}
二、构造方法
- 无参构造函数,head=tail=new Node<E>(null)=空节点(里面无item值)
- 集合构造函数(集合中每个元素不能为null):就是将集合中的元素挨个链起来
//无参构造函数,head=tail=new Node<E>(null)=空节点
//初始一个为空的ConcurrentLinkedQueue,此时head和tail都指向一个item为null的节点
public ConcurrentLinkedQueue() {
// 初始化头尾节点
head = tail = new Node<E>(null);
}
//集合构造函数:就是将集合中的元素挨个链起来
public ConcurrentLinkedQueue(Collection<? extends E> c) {
Node<E> h = null, t = null;
for (E e : c) {
checkNotNull(e);
Node<E> newNode = new Node<E>(e);
if (h == null)
h = t = newNode;
else {
t.lazySetNext(newNode);//可以理解为一种懒加载, 将t的next值设置为newNode
t = newNode;
}
}
if (h == null)
h = t = new Node<E>(null);
head = h;
tail = t;
}
private static void checkNotNull(Object v) {
if (v == null)
throw new NullPointerException();
}
//putObjectVolatile的内存非立即可见版本,
//写后结果并不会被其他线程看到,通常是几纳秒后被其他线程看到,这个时间比较短,所以代价可以接收
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}
三、入队
获取到当前尾节点p=tail:
- 如果p.next=null,代表是真正的尾节点,将新节点链入p.next=newNode。此时检查tail是否还是p,如果不是p了,此时更新tail为最新的newNode(只有在tail节点后面tail.next成功添加的元素才不需要更新tail,其实更新不更新tail是交替的,即每添加俩次更新一次tail)。
- 如果p.next=p,此时其实是p.next==p==null,此时代表p被删除了,此时需要从新的tail节点检查,如果此时tail节点还是原来的tail(原来的tail在p前面,肯定也被删除了),那就只能从head节点开始遍历了
- 如果p.next!=null,代表有别的线程抢先添加元素了,此时需要继续p=p.next遍历获取是null的节点(此时需要如果tail变了就使用新的tail往后遍历)
public boolean offer (E e){
//先检查元素是否为null,是null则抛出异常 不是null,则构造新节点准备入队
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
//初始p指针和t指针都指向尾节点,p指针用来向队列后面推移,t指针用来判断尾节点是否改变
Node<E> t = tail, p = t;
for (; ; ) {
Node<E> q = p.next;
if (q == null) {//p.next为null,则代表p为尾节点,则将p.next指向新节点
// p is last node
if (p.casNext(null, newNode)) {
/**
* 如果p!=t,即p向后推移了,t没动,则此时同时将tail更新
* 不符合条件不更新tail,这里可以看出并不是每入队一个节点都会更新tail的
* 而此时真正的尾节点其实是newNode了,所以tail不一定是真正的尾节点,
* tail的更新具有滞后性,这样设计提高了入队的效率,不用每入队一个,更新一次
*尾节点
*/
if (p != t)
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
} else if (p == q)
/**
* 如果p.next和p相等,这种情况是出队时的一种哨兵节点代表已被遗弃删除,
* 那就是有线程在一直删除节点,删除到了p.next 那此时如果有线程已经更新了tail,那就从p指向tail再开始继续像后推移
* 如果始终没有线程更新tail,则p指针从head开始向后推移
*
* p从head开始推移的原因:tail没有更新,以前的tail肯定在哨兵节点的前面(因为此循环是从tail向后推移到哨兵节点的),
* 而head节点一定在哨兵节点的后面(出队时只有更新了head节点,才会把前面部分的某个节点置为哨兵节点)
* 此时其实是一种tail在head之前,但实际上tail已经无用了,哨兵之前的节点都无用了,
* 等着其他线程入队时更新尾节点tail,此时的tail才有用所以从head开始,从head开始可以找到任何节点
*
*/
p = (t != (t = tail)) ? t : head;
else
/**
* p.next和p不相等时,此时p应该向后推移到p.next,即p=p.next,
* 如果next一直不为null一直定位不到尾节点,会一直next,
* 但是中间会优先判断tail是否已更新,如果tail已更新则p直接从tail向后推移即可。就没必要一直next了。
*/
// Check for tail updates after two hops.
p = (p != t && t != (t = tail)) ? t : q;
}
}
四、出队
poll出队:
获取到当前头节点p=head:如果成功设置了item为null,即p.catItem(item,null),
如果此时被其他线程抢走消费了,此时需要p=p.next,向后继续争抢消费,直到成功执行p.catItem(item,null),此时检查p是不是head节点,如果不是更新p.next为头结点
public E poll() {
restartFromHead:
for (;;) {
// p节点表示首节点,即需要出队的节点
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// 如果p节点的元素不为null,则通过CAS来设置p节点引用的元素为null,如果成功则返回p节点的元素
if (item != null && p.casItem(item, null)) {
// Successful CAS is the linearization point
// for item to be removed from this queue.
// 如果p != h,则更新head
if (p != h) // hop two nodes at a time
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
// 如果头节点的元素为空或头节点发生了变化,这说明头节点已经被另外一个线程修改了。
// 那么获取p节点的下一个节点,如果p节点的下一节点为null,则表明队列已经空了
else if ((q = p.next) == null) {
// 更新头结点
updateHead(h, p);
return null;
}
// p == q,则使用新的head重新开始
else if (p == q)
continue restartFromHead;
// 如果下一个元素不为空,则将头节点的下一个节点设置成头节点
else
p = q;
}
}
}
五、总结
offer:
找到尾节点,将新节点链入到尾节点后面,tail.next=newNode,
由于多线程操作,所以拿到p=tail后cas操作执行p.next=newNode可能由于被其他线程抢去而执行不成功,此时需要p=p.next向后遍历,直到找到p.next=null的目标节点。继续尝试向其后面添加元素,添加成功后检查p是否是tail,如果不是tail,则更新tail=p,添加不成功继续向后next遍历
poll:
获取到当前头节点p=head:如果成功设置了item为null,即p.catItem(item,null),
如果此时被其他线程抢走消费了,此时需要p=p.next,向后继续争抢消费,直到成功执行p.catItem(item,null),此时检查p是不是head节点,如果不是更新头结点head=p.next(因为p已经删除了)
更新tail和head:
不是每次添加都更新tail,而是间隔一次更新一次(head也是一样道理):第一个抢到的线程拿到tail执行成功tail.next=newNode1此时不更新tail,那么第二个线程再执行成功添加p.next=newNode2会判断出p是newNode1而不是tail,所以就更新tail为newNode2。
tail节点不总是最后一个,head节点不总是第一个设计初衷:
让tail节点永远作为队列的尾节点,这样实现代码量非常少,而且逻辑非常清楚和易懂。但是这么做有个缺点就是每次都需要使用循环CAS更新tail节点。如果能减少CAS更新tail节点的次数,就能提高入队的效率。
在JDK 1.7的实现中,doug lea使用hops变量来控制并减少tail节点的更新频率,并不是每次节点入队后都将 tail节点更新成尾节点,而是当tail节点和尾节点的距离大于等于常量HOPS的值(默认等于1)时才更新tail节点,tail和尾节点的距离越长使用CAS更新tail节点的次数就会越少,但是距离越长带来的负面效果就是每次入队时定位尾节点的时间就越长,因为循环体需要多循环一次来定位出尾节点,但是这样仍然能提高入队的效率,因为从本质上来看它通过增加对volatile变量的读操作来减少了对volatile变量的写操作,而对volatile变量的写操作开销要远远大于读操作,所以入队效率会有所提升。
在JDK 1.8的实现中,tail的更新时机是通过p和t是否相等来判断的,其实现结果和JDK 1.7相同,即当tail节点和尾节点的距离大于等于1时,更新tail。
到此这篇关于Java并发编程之ConcurrentLinkedQueue源码详解的文章就介绍到这了,更多相关Java ConcurrentLinkedQueue源码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java并发编程之ReadWriteLock读写锁的操作方法
1.ReadWriteLock介绍 为什么我们有了Lock,还要用ReadWriteLock呢.我们对共享资源加锁之后,所有的线程都将会等待.Lock读操作也锁,写操作也会锁,而对共享资源读的时候,其实是不用加锁的.当然读写同时存在的情况也会有. 比如我们数据库常用操作有增删改查,增删改都是写操作,写操作必须加锁,而读操作可以共享.不是所有的操作都需要加锁. 为了进一步提高复用性和粒度,写操作独占,读操作共享,不加锁. ReadWriteLock管理一组锁,一个是只读的锁,一个是写锁.读锁可以在
-
Java 实现并发的几种方式小结
Java实现并发的几种方法 Java程序默认以单线程方式运行. synchronized Java 用过synchronized 关键字来保证一次只有一个线程在执行代码块. public synchronized void code() { // TODO } Volatile Volatile 关键字保证任何线程在读取Volatile修饰的变量的时候,读取的都是这个变量的最新数据. Threads 和 Runnable public class MyRunnable implements Ru
-
Java并发编程之Exchanger方法详解
简介 Exchanger是一个用于线程间数据交换的工具类,它提供一个公共点,在这个公共点,两个线程可以交换彼此的数据. 当一个线程调用exchange方法后将进入等待状态,直到另外一个线程调用exchange方法,双方完成数据交换后继续执行. Exchanger的使用 方法介绍 exchange(V x):阻塞当前线程,直到另外一个线程调用exchange方法或者当前线程被中断. x : 需要交换的对象. exchange(V x, long timeout, TimeUnit unit):阻塞
-
Java并发编程之CountDownLatch源码解析
一.前言 CountDownLatch维护了一个计数器(还是是state字段),调用countDown方法会将计数器减1,调用await方法会阻塞线程直到计数器变为0.可以用于实现一个线程等待所有子线程任务完成之后再继续执行的逻辑,也可以实现类似简易CyclicBarrier的功能,达到让多个线程等待同时开始执行某一段逻辑目的. 二.使用 一个线程等待其它线程执行完再继续执行 ...... CountDownLatch cdl = new CountDownLatch(10); Executor
-
java关于并发模型中的两种锁知识点详解
1.悲观锁 悲观锁假设最坏的情况(如果果你不锁门,那么捣蛋鬼就会闯入并搞得一团糟),只有在确保其他线程不受干扰(获得正确的锁)的情况下才能执行. 一般实现如独占锁等. 安全性更高,但中低并发性效率更低. 2.乐观锁 乐观锁通过冲突检查机制判断更新过程中是否存在其他线程干扰.如果存在,操作将失败,重试(也可以不重试). CAS等常见实现. 一些乐观锁削弱了一致性,但在中低并发性下效率大大提高. 知识点扩展: 并行与分布式编程 关注的是复杂软件系统的构造,"复杂"是指多线程.分布式与GUI
-
Java并发(Runnable+Thread)实现硬盘文件搜索功能
零.插播2020CSDN博客之星投票新闻 近日(1月11日-1月24日),2020CSDN博客之星评选正在火热进行中,作为码龄1年的小白有幸入选Top 200,首先很感谢CSDN官方把我选上,本来以为只是来凑热闹,看大佬们PK . 综合过去9天大佬们战况,前10名大佬基本坐得很稳,后期出现黑马发力,势不可挡,都在冲刺Top 20,有了微妙的变化,不得不令人佩服点赞!真正的实力可以看出,文章数量不重要,更重要的是质量!一切用数据说话,如图: 截至 2021-01-20 11:50:02 看了大佬的
-
Java并发编程之线程之间的共享和协作
一.线程间的共享 1.1 ynchronized内置锁 用处 Java支持多个线程同时访问一个对象或者对象的成员变量 关键字synchronized可以修饰方法或者以同步块的形式来进行使用 它主要确保多个线程在同一个时刻,只能有一个线程处于方法或者同步块中 它保证了线程对变量访问的可见性和排他性(原子性.可见性.有序性),又称为内置锁机制. 对象锁和类锁 对象锁是用于对象实例方法,或者一个对象实例上的 类锁是用于类的静态方法或者一个类的class对象上的 类的对象实例可以有很多个,但是每个类只有
-
如何使用JCTools实现Java并发程序
概述 在本文中,我们将介绍JCTools(Java并发工具)库. 简单地说,这提供了许多适用于多线程环境的实用数据结构. 非阻塞算法 传统上,在可变共享状态下工作的多线程代码使用锁来确保数据一致性和发布(一个线程所做的更改对另一个线程可见). 这种方法有许多缺点: 线程在试图获取锁时可能会被阻塞,在另一个线程的操作完成之前不会取得任何进展-这有效地防止了并行性 锁争用越重,JVM处理调度线程.管理争用和等待线程队列的时间就越多,实际工作就越少 如果涉及多个锁,并且它们以错误的顺序获取/释放,则可
-
Java高并发BlockingQueue重要的实现类详解
ArrayBlockingQueue 有界的阻塞队列,内部是一个数组,有边界的意思是:容量是有限的,必须进行初始化,指定它的容量大小,以先进先出的方式存储数据,最新插入的在对尾,最先移除的对象在头部. public class ArrayBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable { /** 队列元素 */ final Object
-
Java基础之并发相关知识总结
一.Java并发是什么? 用学术定义来说就是 并发:同一时间段,多个任务都在执行 (单位时间内不一定同时执行): 简单来说就是,同一个时间段,让计算机同时做多个事情. 说到并发,不得不提就是并行: 并行:单位时间内,多个任务同时执行. 两者大眼一看很像,仔细一想却并不相同,因为并行强调某个时间点多个任务同时执行,而并发强调的是一个时间段内多个任务都在执行. 二.怎么做? 大部分并发问题,最终都可以抽象成三类问题分工.同步和互斥.而且针对不同的问题有着不同的方式来解决,具体如下图所示: 三.分工
-
JAVA并发中VOLATILE关键字的神奇之处详解
并发编程中的三个概念: 1.原子性 在Java中,对基本数据类型的变量的读取和赋值操作是原子性操作,即这些操作是不可被中断的,要么执行,要么不执行. 2.可见性 对于可见性,Java提供了volatile关键字来保证可见性. 当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值. 而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保