python机器学习基础特征工程算法详解
目录
- 一、机器学习概述
- 二、数据集的构成
- 1.数据集存储
- 2.可用的数据集
- 3.常用数据集的结构
- 三、特征工程
- 1.字典数据特征抽取
- 2.文本特征抽取
- 3.文本特征抽取:tf-idf
- 4.特征预处理:归一化
- 5.特征预处理:标准化
- 6.特征预处理:缺失值处理
一、机器学习概述
机器学习是从数据中,自动分析获得规律(模型),并利用规律对未知数据进行预测。
二、数据集的构成
1.数据集存储
机器学习的历史数据通常使用csv文件存储。
不用mysql的原因:
1、文件大的话读取速度慢;
2、格式不符合机器学习要求的格式
2.可用的数据集
Kaggle:大数据竞赛平台、80万科学家、真实数据、数据量巨大
Kaggle网址:https://www.kaggle.com/datasets
UCI:360个数据集、覆盖科学生活经济等领域、数据量几十万
UCI数据集网址: http://archive.ics.uci.edu/ml/
scikit-learn:数据量较小、方便学习
scikit-learn网址:http://scikit-learn.org/stable/datasets/index.html#datasets
3.常用数据集的结构
特征值(用以判断目标值所用的条件:比如房子的面积朝向等)+目标值(希望实现的目标:比如房子价格)
有些数据集可以没有目标值。
三、特征工程
”将原始数据转换为能更好地代表预测模型的潜在问题的特征“的过程,叫做特征工程,能够提高对未知数据的预测准确性。特征如果不好,很可能即使算法好,结果也不会尽如人意。
pandas可用于数据读取、对数据的基本处理
sklearn有更多对于特征的处理的强大的接口
特征抽取:
特征抽取API:sklearn.feature_extraction
1.字典数据特征抽取
API:sklearn.feature_extraction.DictVectorizer
语法如下:

字典数据抽取:将字典中的类别数据分别进行转换为特征数据。因此,如果输入的是数组形式,并且有类别的这些特征,需要先转换成字典数据,然后进行抽取。
2.文本特征抽取
Count
类:sklearn.feature_extraction.text.CountVectorizer
用法:

1.统计所有文章当中所有的词,重复的只看做一次
2.对每篇文章,在词的列表里面,统计每个词出现的次数
3.单个字母不统计
注意:该方法默认不支持中文,每个中文汉字被视为一个英文字母,中间有空格或者逗号就会被分开,同样的,一个汉字不予统计。(中文可使用jieba分词:pip install jieba,使用:jieba.cut("我是一个程序员"))
3.文本特征抽取:tf-idf
上面的countvec不能处理中性词比如“明天,中午,因为”等。于是可以使用tfidf方法。
tf:term frequency词频(和countvec方法一样)
idf:inverse document frequency逆文档频率 log(总文档数量/该词出现的文档数)
tf * idf 重要性程度
类:sklearn.feature_extraction.text.TfidfVectorizer
4.特征预处理:归一化
特征预处理:通过特定的统计方法,将数据转换为算法要求的数据
特征预处理API:sklearn.preprocessing

归一化API:sklearn.preprocessing.MinMaxScaler

多个特征同等重要并且特征数据之间差距较大的时候,进行归一化。但归一化容易受异常点的影响,因此该方法鲁棒性较差,只适合传统精确小数据场景。
5.特征预处理:标准化
将原始数据变换到均值为0,标准差为1的范围内

标准化API:
sklearn.preprocessing.StandardScaler

标准化适合现代嘈杂大数据场景,在已有样本足够多的情况下比较稳定。
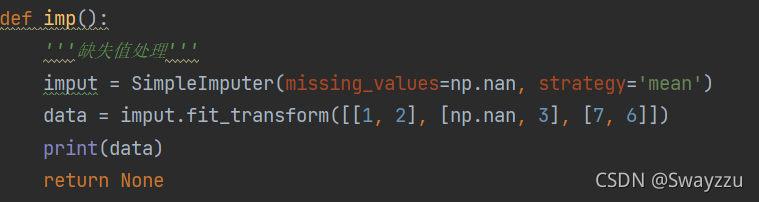
6.特征预处理:缺失值处理
插补:通过缺失值每行或每列的平均值、中位数来填补(一般按列填补)
API:sklearn.impute.SimpleImputer
数据当中的缺失值标记:默认为np.nan
以上就是python机器学习基础特征工程算法详解的详细内容,更多关于python机器学习特征工程的资料请关注我们其它相关文章!
相关推荐
-

python机器学习基础决策树与随机森林概率论
目录 一.决策树原理概述 1.决策树原理 2.信息论 ①信息熵 ②决策树的分类依据 ③其他决策树使用的算法 ④决策树API 二.决策树算法案例 1.案例概述 2.数据处理 3.特征工程 4.使用决策树进行预测 5.决策树优缺点及改进 三.随机森林 1.集成学习方法 2.单个树建立过程 3.随机森林API 4.随机森林使用案例 5.随机森林的优点 一.决策树原理概述 1.决策树原理 决策树的分类原理,相当于程序中的if-then结构,通过条件判断,来决定结果. 2.信息论 ①信息熵 假设有32支球
-
python机器学习算法与数据降维分析详解
目录 一.数据降维 1.特征选择 2.主成分分析(PCA) 3.降维方法使用流程 二.机器学习开发流程 1.机器学习算法分类 2.机器学习开发流程 三.转换器与估计器 1.转换器 2.估计器 一.数据降维 机器学习中的维度就是特征的数量,降维即减少特征数量.降维方式有:特征选择.主成分分析. 1.特征选择 当出现以下情况时,可选择该方式降维: ①冗余:部分特征的相关度高,容易消耗计算性能 ②噪声:部分特征对预测结果有影响 特征选择主要方法:过滤式(VarianceThreshold).嵌入式(正
-
jquery.AutoComplete.js中文修正版(支持firefox)
复制代码 代码如下: jQuery.autocomplete = function(input, options) { // Create a link to self var me = this; // Create jQuery object for input element var $input = $(input).attr("autocomplete", "off"); // Apply inputClass if necessary if (optio
-
基于Python和Scikit-Learn的机器学习探索
你好,%用户名%! 我叫Alex,我在机器学习和网络图分析(主要是理论)有所涉猎.我同时在为一家俄罗斯移动运营商开发大数据产品.这是我第一次在网上写文章,不喜勿喷. 现在,很多人想开发高效的算法以及参加机器学习的竞赛.所以他们过来问我:"该如何开始?".一段时间以前,我在一个俄罗斯联邦政府的下属机构中领导了媒体和社交网络大数据分析工具的开发.我仍然有一些我团队使用过的文档,我乐意与你们分享.前提是读者已经有很好的数学和机器学习方面的知识(我的团队主要由MIPT(莫斯科物理与技术大学)和
-
python机器学习基础K近邻算法详解KNN
目录 一.k-近邻算法原理及API 1.k-近邻算法原理 2.k-近邻算法API 3.k-近邻算法特点 二.k-近邻算法案例分析案例信息概述 第一部分:处理数据 1.数据量缩小 2.处理时间 3.进一步处理时间 4.提取并构造时间特征 5.删除无用特征 6.签到数量少于3次的地点,删除 7.提取目标值y 8.数据分割 第二部分:特征工程 标准化 第三部分:进行算法流程 1.算法执行 2.预测结果 3.检验效果 一.k-近邻算法原理及API 1.k-近邻算法原理 如果一个样本在特征空间中的k个最相
-
python机器学习朴素贝叶斯算法及模型的选择和调优详解
目录 一.概率知识基础 1.概率 2.联合概率 3.条件概率 二.朴素贝叶斯 1.朴素贝叶斯计算方式 2.拉普拉斯平滑 3.朴素贝叶斯API 三.朴素贝叶斯算法案例 1.案例概述 2.数据获取 3.数据处理 4.算法流程 5.注意事项 四.分类模型的评估 1.混淆矩阵 2.评估模型API 3.模型选择与调优 ①交叉验证 ②网格搜索 五.以knn为例的模型调优使用方法 1.对超参数进行构造 2.进行网格搜索 3.结果查看 一.概率知识基础 1.概率 概率就是某件事情发生的可能性. 2.联合概率 包
-
python机器学习基础特征工程算法详解
目录 一.机器学习概述 二.数据集的构成 1.数据集存储 2.可用的数据集 3.常用数据集的结构 三.特征工程 1.字典数据特征抽取 2.文本特征抽取 3.文本特征抽取:tf-idf 4.特征预处理:归一化 5.特征预处理:标准化 6.特征预处理:缺失值处理 一.机器学习概述 机器学习是从数据中,自动分析获得规律(模型),并利用规律对未知数据进行预测. 二.数据集的构成 1.数据集存储 机器学习的历史数据通常使用csv文件存储. 不用mysql的原因: 1.文件大的话读取速度慢: 2.格式不符合
-
Python机器学习之PCA降维算法详解
一.算法概述 主成分分析 (Principal ComponentAnalysis,PCA)是一种掌握事物主要矛盾的统计分析方法,它可以从多元事物中解析出主要影响因素,揭示事物的本质,简化复杂的问题. PCA 是最常用的一种降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的方差最大,以此使用较少的维度,同时保留较多原数据的维度. PCA 算法目标是求出样本数据协方差矩阵的特征值和特征向量,而协方差矩阵的特征向量的方向就是PCA需要投影的方向.使样本
-
python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat
-
Python集成学习之Blending算法详解
一.前言 普通机器学习:从训练数据中学习一个假设. 集成方法:试图构建一组假设并将它们组合起来,集成学习是一种机器学习范式,多个学习器被训练来解决同一个问题. 集成方法分类为: Bagging(并行训练):随机森林 Boosting(串行训练):Adaboost; GBDT; XgBoost Stacking: Blending: 或者分类为串行集成方法和并行集成方法 1.串行模型:通过基础模型之间的依赖,给错误分类样本一个较大的权重来提升模型的性能. 2.并行模型的原理:利用基础模型的独立性,
-
Python机器学习之K-Means聚类实现详解
本文为大家分享了Python机器学习之K-Means聚类的实现代码,供大家参考,具体内容如下 1.K-Means聚类原理 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.其基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果.各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开. 算法大致流程为:(1)随机选取k个点作为种子点(这k个点不一定属于数据集)
-
python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚
-
Python编程实现蚁群算法详解
简介 蚁群算法(ant colony optimization, ACO),又称蚂蚁算法,是一种用来在图中寻找优化路径的机率型算法.它由Marco Dorigo于1992年在他的博士论文中提出,其灵感来源于蚂蚁在寻找食物过程中发现路径的行为.蚁群算法是一种模拟进化算法,初步的研究表明该算法具有许多优良的性质.针对PID控制器参数优化设计问题,将蚁群算法设计的结果与遗传算法设计的结果进行了比较,数值仿真结果表明,蚁群算法具有一种新的模拟进化优化方法的有效性和应用价值. 定义 各个蚂蚁在没有事先告诉
-
Python自然语言处理之切分算法详解
一.前言 我们需要分析某句话,就必须检测该条语句中的词语. 一般来说,一句话肯定包含多个词语,它们互相重叠,具体输出哪一个由自然语言的切分算法决定.常用的切分算法有完全切分.正向最长匹配.逆向最长匹配以及双向最长匹配. 本篇博文将一一介绍这些常用的切分算法. 二.完全切分 完全切分是指,找出一段文本中的所有单词. 不考虑效率的话,完全切分算法其实非常简单.只要遍历文本中的连续序列,查询该序列是否在词典中即可.上一篇我们获取了词典的所有词语dic,这里我们直接用代码遍历某段文本,完全切分出所有的词
-
Python机器学习之决策树算法实例详解
本文实例讲述了Python机器学习之决策树算法.分享给大家供大家参考,具体如下: 决策树学习是应用最广泛的归纳推理算法之一,是一种逼近离散值目标函数的方法,在这种方法中学习到的函数被表示为一棵决策树.决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,机器学习算法最终将使用这些从数据集中创造的规则.决策树的优点为:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据.缺点为:可能产生过度匹配的问题.决策树适于处理离散型和连续型的数据. 在决策树中最重要的就是如何选取