为什么JDK8中HashMap依然会死循环
JDK8中HashMap依然会死循环!
是否你听说过JDK8之后HashMap已经解决的扩容死循环的问题,虽然HashMap依然说线程不安全,但是不会造成服务器load飙升的问题。
然而事实并非如此。少年可曾了解一种红黑树成环的场景,=v=
今日在查看监控时候发现,某一台机器load飙升
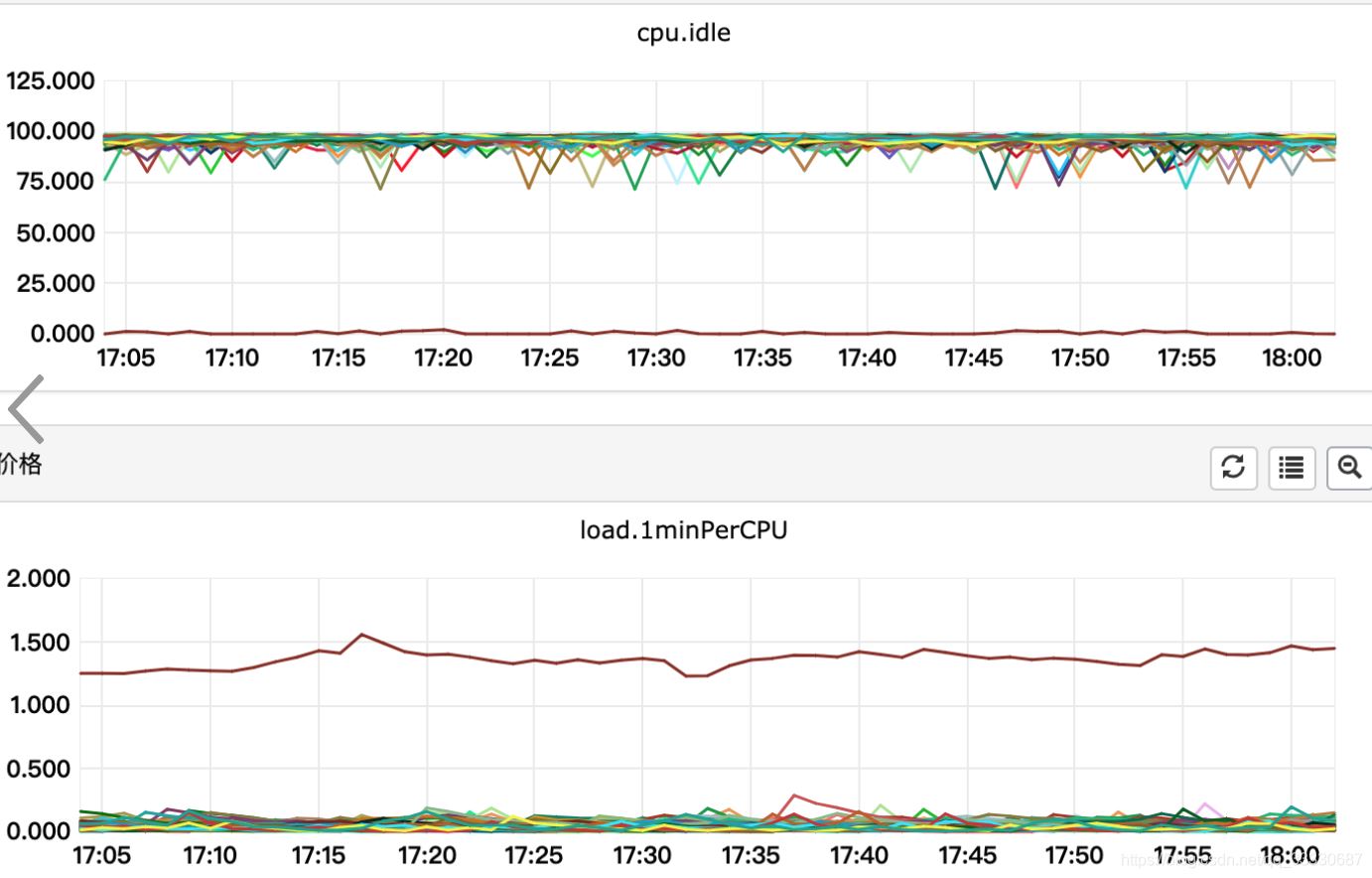
感觉问题不对劲,ssh大法登陆机器,top,top -Hp,jstack,jmap四连击保存下来堆栈,cpu使用最高的线程,内存信息准备分析。
首先查看使用最耗费cpu的线程堆栈信息
cat stack | grep -i 34670 -C10 --color

我勒个去,HashMap,猜测八成死循环了,但是我们使用的JDK8,在8中通过栈封闭的链表替换,解决了扩容死循环的问题。疑惑,继续往下看。
根据堆栈信息,root方法是问题所在,点开HashMap源码
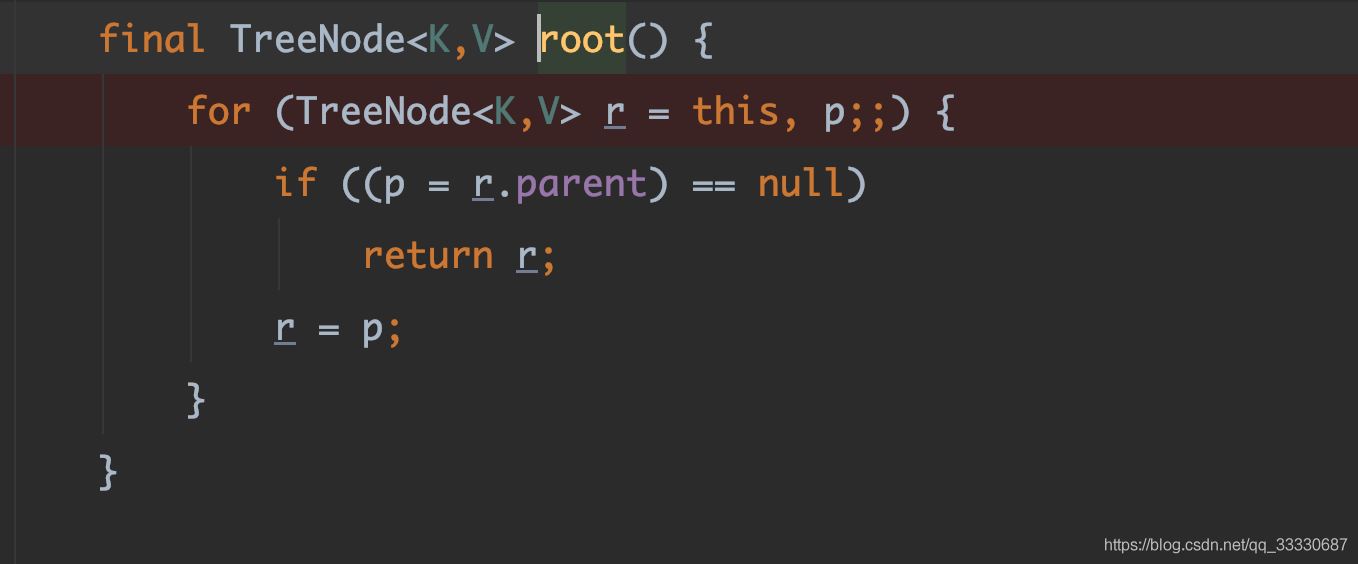
好嘛,load飙高,代码有个for语句,我觉得铁定死循环了,看代码情况只可能是两个红黑树节点的父亲节点相互引用才可以导致无法走出这个for语句。
然而这都是我的猜测,我没有证据。而且让我追红黑树的代码,也是需要耗费大量时间的事情,我需要快速验证我的猜测。
我之前dump下来了堆内存信息,我通过jhat 命令生成html的内存信息页面
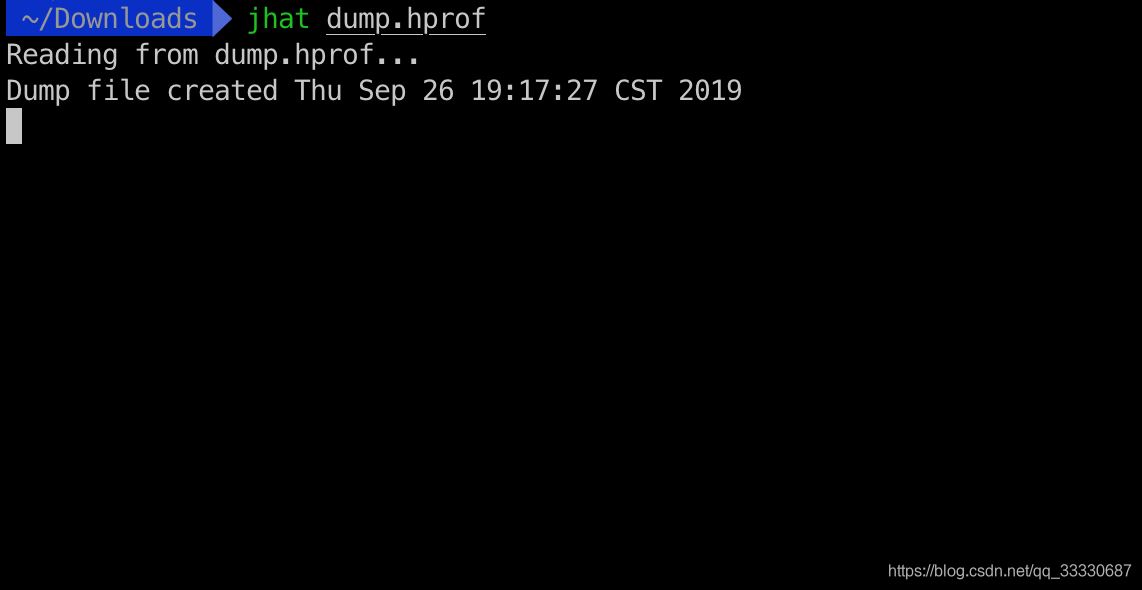
然后输入http://localhost:7000查看
我先找业务代码中持有这个HashMap的对象,然后点进去查询内部信息
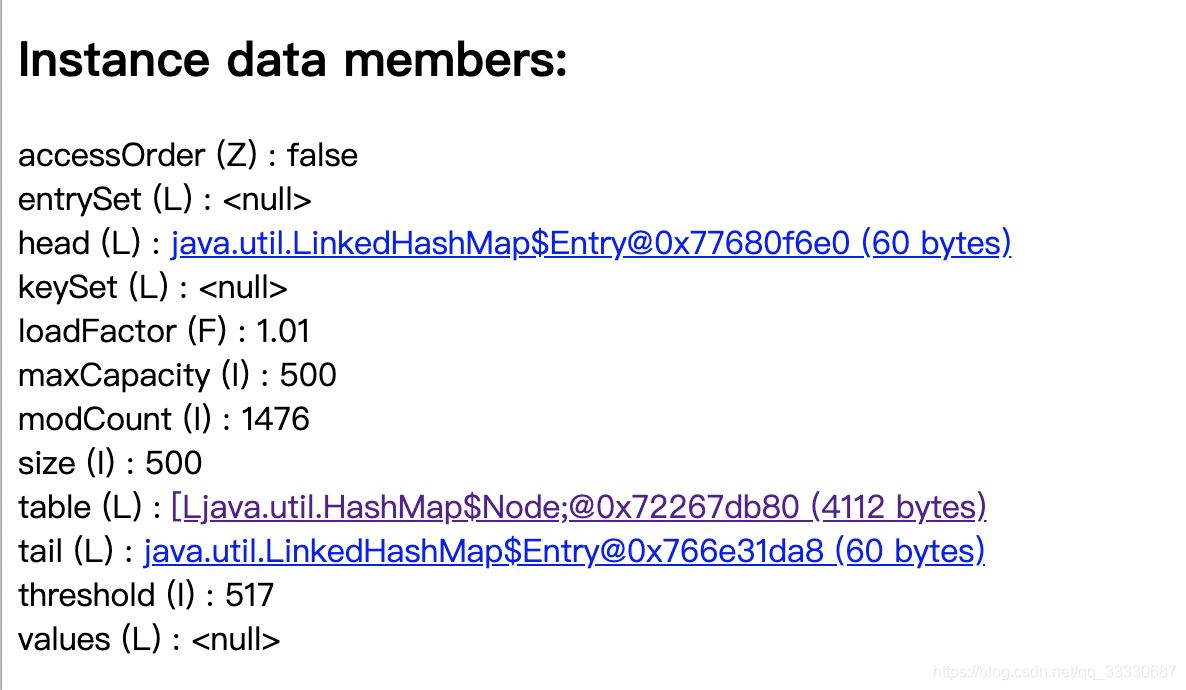
因为数据都放在table中,点击Table字段,查看其内容
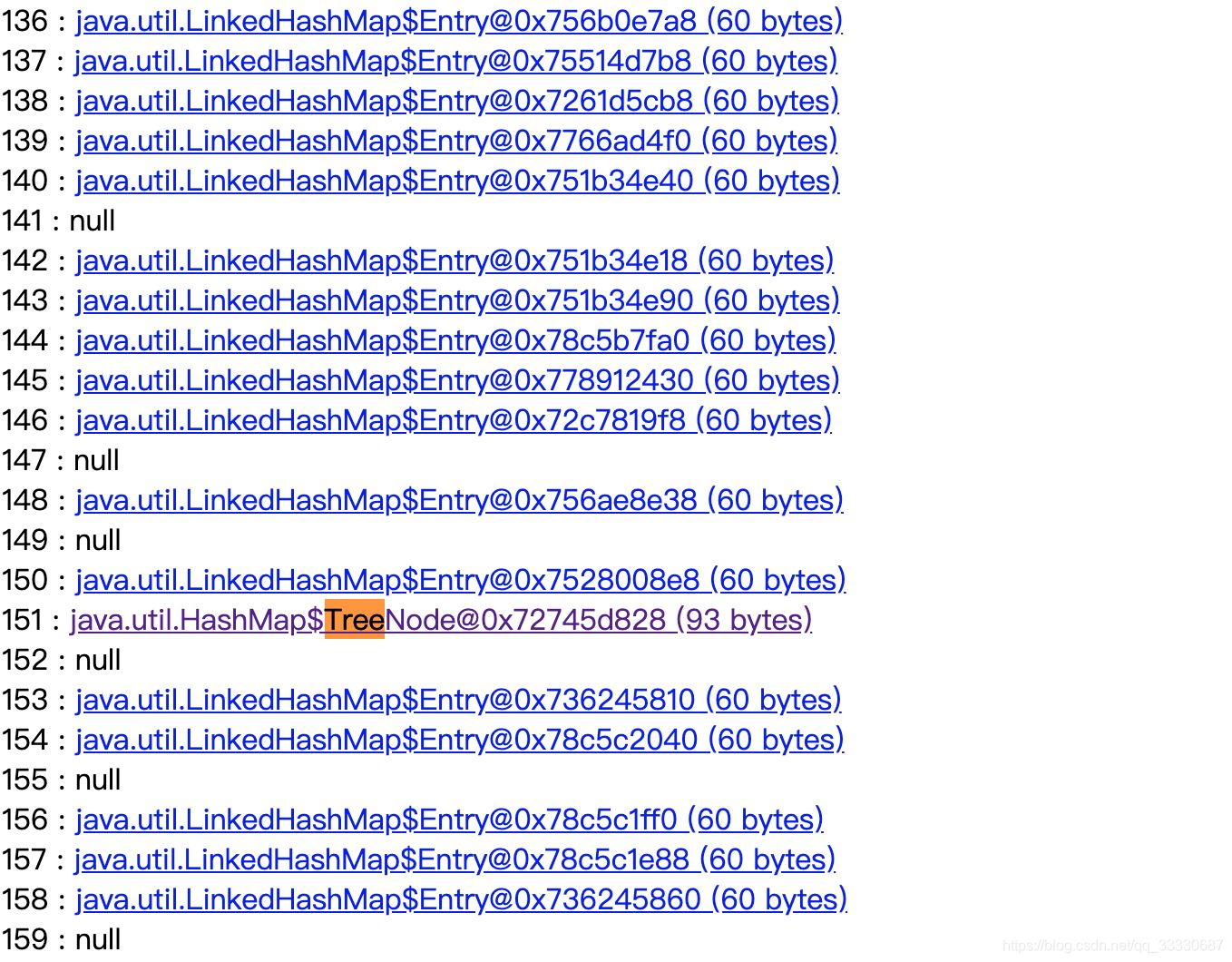
table中存在唯一的一个TreeNode节点,这肯定是已经变成了红黑树了
点进去查看

点击parent字段信息
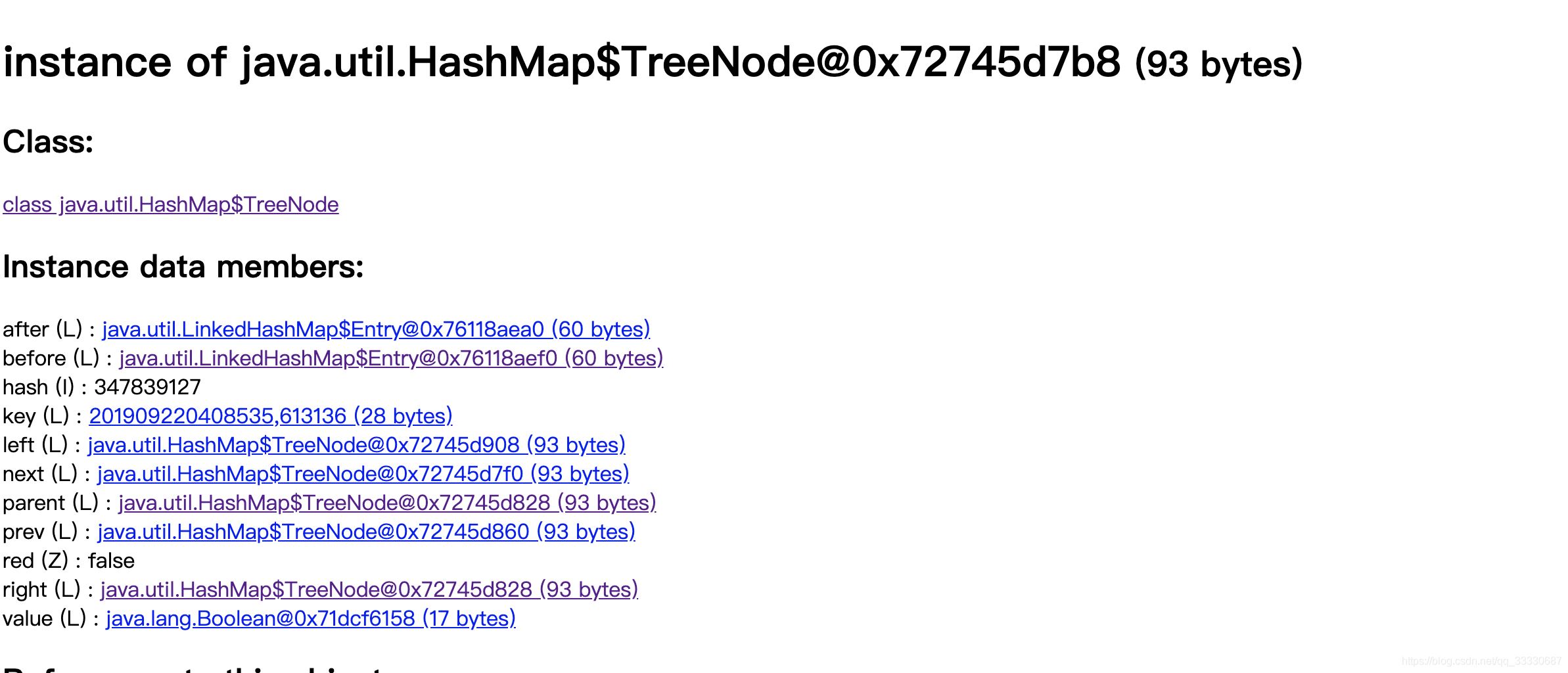
0x72745d828与0x72745d7b8两个TreeNode节点的Parent引用都是对方。
后续打算深入研究一下红黑树什么场景会造成这个原因。
最后,无论什么并发场景请别使用HashMap,ConcurrentHashmap大法好
到此这篇关于为什么JDK8中HashMap依然会死循环的文章就介绍到这了,更多相关JDK8 HashMap死循环内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
JDK1.8中ConcurrentHashMap中computeIfAbsent死循环bug问题
死循环问题的提出:https://bugs.openjdk.java.net/browse/JDK-8062841 map.computeIfAbsent("AaAa",key->map.computeIfAbsent("BBBB",key2->42)); computeIfAbsent在1.8中才有的方法 computeIfAbsent意思是:key不存在时候,调用mappingFunction函数结果作为value值 debug 两个key的hash
-

Jdk1.8 HashMap实现原理详细介绍
HashMap概述 HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射操作,并允许使用null值和null键.此类不保证映射的顺序,特别是它不保证该顺序恒久不变. HashMap的数据结构 在Java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外.HashMap实际上是一个"链表散列"的数据结构,即数组和链表的结构,但是在jdk1.8里 加入了红黑树的实现,当链表的
-
jdk7 中HashMap的知识点总结
HashMap中的几个重要变量 默认初始容量,必须是2的n次方 static final int DEFAULT_INITIAL_CAPACITY = 16; 最大容量,当通过构造方法传入的容量比它还大时,就用这个最大容量,必须是2的n次方 static final int MAXIMUM_CAPACITY = 1 << 30; 默认负载因子 static final float DEFAULT_LOAD_FACTOR = 0.75f; 用来存储键值对,可以看到键值对都是存储在Entry中的
-
为什么JDK8中HashMap依然会死循环
JDK8中HashMap依然会死循环! 是否你听说过JDK8之后HashMap已经解决的扩容死循环的问题,虽然HashMap依然说线程不安全,但是不会造成服务器load飙升的问题. 然而事实并非如此.少年可曾了解一种红黑树成环的场景,=v= 今日在查看监控时候发现,某一台机器load飙升 感觉问题不对劲,ssh大法登陆机器,top,top -Hp,jstack,jmap四连击保存下来堆栈,cpu使用最高的线程,内存信息准备分析. 首先查看使用最耗费cpu的线程堆栈信息 cat stack | g
-
HashMap在JDK7与JDK8中的实现过程解析
HashMap的实现原理 首先有一个每个元素都是链表(可能表述不准确)的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值的元素的后面,他们在数组的同一位置,但是形成了链表,同一各链表上的Hash值是相同的,所以说数组存放的是链表.而当链表长度太长时,链表就转换为红黑树,这样大大提高了查找的效率. 当链表数组的容量超过初始容量的0.75时,再散列将链表数组扩
-
在Java8与Java7中HashMap源码实现的对比
一.HashMap的原理介绍 此乃老生常谈,不作仔细解说. 一句话概括之:HashMap是一个散列表,它存储的内容是键值对(key-value)映射. 二.Java 7 中HashMap的源码分析 首先是HashMap的构造函数代码块1中,根据初始化的Capacity与loadFactor(加载因子)初始化HashMap. //代码块1 public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0)
-
JDK8中的HashMap初始化和扩容机制详解
一.HashMap初始化方法 HashMap() 不带参数,默认初始化大小为16,加载因子为0.75: HashMap(int initialCapacity) 指定初始化大小: HashMap(int initialCapacity, float loadFactor) 指定初始化大小和加载因子大小: HashMap(Map<? extends K,? extends V> m) 用现有的一个map来构造HashMap. 二.分析初始化过程 1.初始化代码测试用例 Map<String
-
剖析Java中HashMap数据结构的源码及其性能优化
存储结构 首先,HashMap是基于哈希表存储的.它内部有一个数组,当元素要存储的时候,先计算其key的哈希值,根据哈希值找到元素在数组中对应的下标.如果这个位置没有元素,就直接把当前元素放进去,如果有元素了(这里记为A),就把当前元素链接到元素A的前面,然后把当前元素放入数组中.所以在Hashmap中,数组其实保存的是链表的首节点.下面是百度百科的一张图: 如上图,每个元素是一个Entry对象,在其中保存了元素的key和value,还有一个指针可用于指向下一个对象.所有哈希值相同的key(也就
-
java中hashmap容量的初始化实现
HashMap使用HashMap(int initialCapacity)对集合进行初始化. 在默认的情况下,HashMap的容量是16.但是如果用户通过构造函数指定了一个数字作为容量,那么Hash会选择大于该数字的第一个2的幂作为容量.比如如果指定了3,则容量是4:如果指定了7,则容量是8:如果指定了9,则容量是16. 为什么要设置HashMap的初始化容量 在<阿里巴巴Java开发手册>中,有一条开发建议是建议我们设置HashMap的初始化容量. 下面我们通过具体的代码来了解下为什么会这么
-
深入理解JDK8中Stream使用
概述 Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找.过滤和映射数据等操作.使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询.也可以使用 Stream API 来并行执行操作.简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式. 特点: 不是数据结构,不会保存数据. 不会修改原来的数据源,它会将操作后的数据保存到另外一个对象中.(保留意见:毕竟peek方法可以修改流中元素)
-
java 中HashMap、HashSet、TreeMap、TreeSet判断元素相同的几种方法比较
java 中HashMap.HashSet.TreeMap.TreeSet判断元素相同的几种方法比较 1.1 HashMap 先来看一下HashMap里面是怎么存放元素的.Map里面存放的每一个元素都是key-value这样的键值对,而且都是通过put方法进行添加的,而且相同的key在Map中只会有一个与之关联的value存在.put方法在Map中的定义如下. V put(K key, V value); 它用来存放key-value这样的一个键值对,返回值是key在Map中存放的旧va
-
java 中HashMap实现原理深入理解
1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端. 数组 数组存储区间是连续的,占用内存严重,故空间复杂的很大.但数组的二分查找时间复杂度小,为O(1):数组的特点是:寻址容易,插入和删除困难: 链表 链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N).链表的特点是:寻址困难,插入和删除容易. 哈希表 那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提