Tensorflow轻松实现XOR运算的方式
对于“XOR”大家应该都不陌生,我们在各种课程中都会遇到,它是一个数学逻辑运算符号,在计算机中表示为“XOR”,在数学中表示为“ ”,学名为“异或”,其来源细节就不详细表明了,说白了就是两个a、b两个值做异或运算,若a=b则结果为0,反之为1,即“相同为0,不同为1”.
”,学名为“异或”,其来源细节就不详细表明了,说白了就是两个a、b两个值做异或运算,若a=b则结果为0,反之为1,即“相同为0,不同为1”.
在计算机早期发展中,逻辑运算广泛应用于电子管中,这一点如果大家学习过微机原理应该会比较熟悉,那么在神经网络中如何实现它呢,早先我们使用的是感知机,可理解为单层神经网络,只有输入层和输出层(在吴恩达老师的系列教程中曾提到过这一点,关于神经网络的层数,至今仍有异议,就是说神经网络的层数到底包不包括输入层,现今多数认定是不包括的,我们常说的N层神经网络指的是隐藏层+输出层),但是感知机是无法实现XOR运算的,简单来说就是XOR是线性不可分的,由于感知机是有输入输出层,无法线性划分XOR区域,于是后来就有了使用多层神经网络来解决这一问题的想法~~
关于多层神经网络实现XOR运算可大致这么理解:

两个输入均有两个取值0和1,那么组合起来就有四种可能,即[0,0]、[0,1]、[1,0]、[1,1],这样就可以通过中间的隐藏层进行异或运算了~
咱们直接步入正题吧,对于此次试验我们只需要一个隐藏层即可,关于神经网络 的基础知识建议大家去看一下吴恩达大佬的课程,真的很棒,百看不厌,真正的大佬是在认定学生是绝对小白的前提下去讲解的,所以一般人都能听懂~~接下来的图纯手工操作,可能不是那么准确,但中心思想是没有问题的,我们开始吧:
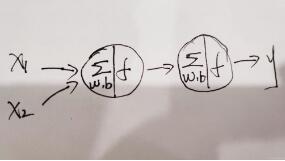
上图是最基本的神经网络示意图,有两个输入x1、x2,一个隐藏层,只有一个神经元,然后有个输出层,这就是最典型的“输入层+隐藏层+输出层”的架构,对于本题目,我们的输入和输出以及整体架构如下图所示:
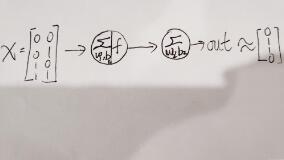
输入量为一个矩阵,0和0异或结果为0,0和1异或结果为1,依次类推,对应我们的目标值为[0,1,1,0],最后之所以用约等号是因为我们的预测值与目标值之间会有一定的偏差,如果训练的好那么这二者之间是无限接近的。
我们直接上全部代码吧,就不分步进行了,以为这个实验本身难度较低,且代码注释很清楚,每一步都很明确,如果大家有什么不理解的可以留言给我,看到必回:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import numpy as np
import tensorflow as tf
#定义输入值与目标值
X=np.array([[0,0],[0,1],[1,0],[1,1]])
Y=np.array([[0],[1],[1],[0]])
#定义占位符,从输入或目标中按行取数据
x=tf.placeholder(tf.float32,[None,2])
y=tf.placeholder(tf.float32,[None,1])
#初始化权重,使其满足正态分布,w1和w2分别为输入层到隐藏层和隐藏层到输出层的权重矩阵
w1=tf.Variable(tf.random_normal([2,2]))
w2=tf.Variable(tf.random_normal([2,1]))
#定义b1和b2,分别为隐藏层和输出层的偏移量
b1=tf.Variable([0.1,0.1])
b2=tf.Variable([0.1])
#使用Relu激活函数得到隐藏层的输出值
a=tf.nn.relu(tf.matmul(x,w1)+b1)
#输出层不用激活函数,直接获得其值
out=tf.matmul(a,w2)+b2
#定义损失函数MSE
loss=tf.reduce_mean(tf.square(out-y))
#优化器选择Adam
train=tf.train.AdamOptimizer(0.01).minimize(loss)
#开始训练,迭代1001次(方便后边的整数步数显示)
with tf.Session() as session:
session.run(tf.global_variables_initializer()) #初始化变量
for i in range(1001):
session.run(train,feed_dict={x:X,y:Y}) #训练模型
loss_final=session.run(loss,feed_dict={x:X,y:Y}) #获取损失
if i%100==0:
print("step:%d loss:%2f" % (i,loss_final))
print("X: %r" % X)
print("pred_out: %r" % session.run(out,feed_dict={x:X}))
对照第三张图片理解代码更加直观,我们的隐藏层神经元功能就是将输入值和相应权重做矩阵乘法,然后加上偏移量,最后使用激活函数进行非线性转换;而输出层没有用到激活函数,因为本次我们不是进行分类或者其他操作,一般情况下隐藏层使用激活函数Relu,输出层若是分类则用sigmode,当然你也可以不用,本次实验只是单纯地做异或运算,那输出层就不劳驾激活函数了~
对于标准神经元内部的操作可理解为下图:
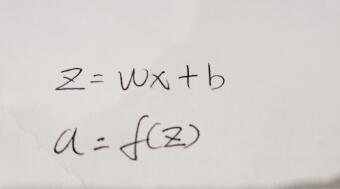
这里的x和w一般写成矩阵形式,因为大多数都是多个输入,而矩阵的乘积要满足一定的条件,这一点属于线代中最基础的部分,大家可以稍微了解一下,这里对设定权重的形状还是很重要的;
看下效果吧:

这是我们在学习率为0.1,迭代1001次的条件下得到的结果
然后我们学习率不变,迭代2001次,看效果:
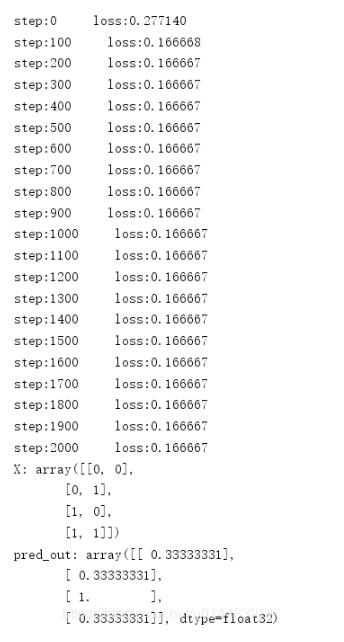
没有改进,这就说明不是迭代次数的问题,我们还是保持2001的迭代数,将学习率改为0.01,看效果:

完美~~~最后损失降为0了~~一般来说,神经网络中的超参中最重要的就是学习率了,如果损失一直降不下来,我们首先要想到修改学习率,其他的超参次之……
大家可以观察一下我们的预测值,四项分别对应[0,1,1,0],已经是相当接近了……
以上这篇Tensorflow轻松实现XOR运算的方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
tensorflow estimator 使用hook实现finetune方式
为了实现finetune有如下两种解决方案: model_fn里面定义好模型之后直接赋值 def model_fn(features, labels, mode, params): # ..... # finetune if params.checkpoint_path and (not tf.train.latest_checkpoint(params.model_dir)): checkpoint_path = None if tf.gfile.IsDirectory(params.chec
-
Tensorflow 实现修改张量特定元素的值方法
最近在做一个摘要生成的项目,过程中遇到了很多小问题,从网上查阅了许多别人解决不同问题的方法,自己也在旁边开了个jupyter notebook搞些小实验,这里总结一下遇到的一些问题. Tensorflow用起来不是很顺手,很大原因在于tensor这个玩意儿,并不像数组或者列表那么的直观,直接print的话只能看到 Tensor(-) 这样的提示.比如下面这个问题,我们想要修改张量特定位置上的某个数值,操作起来就相对麻烦一些.和array一样,张量也是可以分段读取的,比如 tensor[1:10]
-

详解Tensorflow数据读取有三种方式(next_batch)
Tensorflow数据读取有三种方式: Preloaded data: 预加载数据 Feeding: Python产生数据,再把数据喂给后端. Reading from file: 从文件中直接读取 这三种有读取方式有什么区别呢? 我们首先要知道TensorFlow(TF)是怎么样工作的. TF的核心是用C++写的,这样的好处是运行快,缺点是调用不灵活.而Python恰好相反,所以结合两种语言的优势.涉及计算的核心算子和运行框架是用C++写的,并提供API给Python.Python调用这些A
-
使用Tensorflow实现可视化中间层和卷积层
为了查看网络训练的效果或者便于调参.更改结构等,我们常常将训练网络过程中的loss.accurcy等参数. 除此之外,有时我们也想要查看训练好的网络中间层输出和卷积核上面表达了什么内容,这可以帮助我们思考CNN的内在机制.调整网络结构或者把这些可视化内容贴在论文当中辅助说明训练的效果等. 中间层和卷积核的可视化有多种方法,整理如下: 1. 以矩阵(matrix)格式手动输出图像: 用简单的LeNet网络训练MNIST数据集作为示例: x = tf.placeholder(tf.float32,
-
检测tensorflow是否使用gpu进行计算的方式
如下所示: import tensorflow as tf sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) 查看日志信息若包含gpu信息,就是使用了gpu. 其他方法:跑计算量大的代码,通过 nvidia-smi 命令查看gpu的内存使用量. 以上这篇检测tensorflow是否使用gpu进行计算的方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Tensorflow轻松实现XOR运算的方式
对于"XOR"大家应该都不陌生,我们在各种课程中都会遇到,它是一个数学逻辑运算符号,在计算机中表示为"XOR",在数学中表示为"",学名为"异或",其来源细节就不详细表明了,说白了就是两个a.b两个值做异或运算,若a=b则结果为0,反之为1,即"相同为0,不同为1". 在计算机早期发展中,逻辑运算广泛应用于电子管中,这一点如果大家学习过微机原理应该会比较熟悉,那么在神经网络中如何实现它呢,早先我们使用的是感
-
PHP MySQL应用中使用XOR运算加密算法分享
XOR算法原理 从加密的主要方法看,换位法过于简单,特别是对于数据量少的情况很容易由密文猜出明文,而替换法不失为一种行之有效的简易算法. 从各种替换法运算的特点看,异或运算最适合用于简易加解密运算,这种方法的原理是:当一个数A和另一个数B进行异或运算会生成另一个数C,如果再将C和B进行异或运算则C又会还原为A. 相对于其他的简易加密算法,XOR算法的优点如下. (1)算法简单,对于高级语言很容易能实现. (2)速度快,可以在任何时候.任何地方使用. (3)对任何字符都是有效的,不像有些简易加密算
-
利用Tensorflow的队列多线程读取数据方式
在tensorflow中,有三种方式输入数据 1. 利用feed_dict送入numpy数组 2. 利用队列从文件中直接读取数据 3. 预加载数据 其中第一种方式很常用,在tensorflow的MNIST训练源码中可以看到,通过feed_dict={},可以将任意数据送入tensor中. 第二种方式相比于第一种,速度更快,可以利用多线程的优势把数据送入队列,再以batch的方式出队,并且在这个过程中可以很方便地对图像进行随机裁剪.翻转.改变对比度等预处理,同时可以选择是否对数据随机打乱,可以说是
-
基于Tensorflow批量数据的输入实现方式
基于Tensorflow下的批量数据的输入处理: 1.Tensor TFrecords格式 2.h5py的库的数组方法 在tensorflow的框架下写CNN代码,我在书写过程中,感觉不是框架内容难写, 更多的是我在对图像的预处理和输入这部分花了很多精神. 使用了两种方法: 方法一: Tensor 以Tfrecords的格式存储数据,如果对数据进行标签,可以同时做到数据打标签. ①创建TFrecords文件 orig_image = '/home/images/train_image/' gen
-
使用TensorFlow直接获取处理MNIST数据方式
MNIST是一个非常有名的手写体数字识别数据集,TensorFlow对MNIST数据集做了封装,可以直接调用.MNIST数据集包含了60000张图片作为训练数据,10000张图片作为测试数据,每一张图片都代表了0-9中的一个数字,图片大小都是28*28.虽然这个数据集只提供了训练和测试数据,但是为了验证训练网络的效果,一般从训练数据中划分出一部分数据作为验证数据,测试神经网络模型在不同参数下的效果.TensorFlow提供了一个类来处理MNIST数据. 代码如下: from tensorflow
-
详解tensorflow载入数据的三种方式
Tensorflow数据读取有三种方式: Preloaded data: 预加载数据 Feeding: Python产生数据,再把数据喂给后端. Reading from file: 从文件中直接读取 这三种有读取方式有什么区别呢? 我们首先要知道TensorFlow(TF)是怎么样工作的. TF的核心是用C++写的,这样的好处是运行快,缺点是调用不灵活.而Python恰好相反,所以结合两种语言的优势.涉及计算的核心算子和运行框架是用C++写的,并提供API给Python.Python调用这些A
-
JS中如何轻松遍历对象属性的方式总结
自身可枚举属性 Object.keys() 方法会返回一个由一个给定对象的自身可枚举属性组成的数组,数组中属性名的排列顺序和使用 for...in 循环遍历该对象时返回的顺序一致 .如果对象的键-值都不可枚举,那么将返回由键组成的数组. 这是合理的,因为大多数时候只需要关注对象自身的属性. 来看看一个对象拥有自身和继承属性的例子,Object.keys()只返回自己的属性键: let simpleColors = { colorA: 'white', colorB: 'black' }; let
-
初探TensorFLow从文件读取图片的四种方式
本文记录一下TensorFLow的几种图片读取方法,官方文档有较为全面的介绍. 1.使用gfile读图片,decode输出是Tensor,eval后是ndarray import matplotlib.pyplot as plt import tensorflow as tf import numpy as np print(tf.__version__) image_raw = tf.gfile.FastGFile('test/a.jpg','rb').read() #bytes img =
-
TensorFLow 数学运算的示例代码
一.Tensor 之间的运算规则 相同大小 Tensor 之间的任何算术运算都会将运算应用到元素级 不同大小 Tensor(要求dimension 0 必须相同) 之间的运算叫做广播(broadcasting) Tensor 与 Scalar(0维 tensor) 间的算术运算会将那个标量值传播到各个元素 Note: TensorFLow 在进行数学运算时,一定要求各个 Tensor 数据类型一致 二.常用操作符和基本数学函数 大多数运算符都进行了重载操作,使我们可以快速使用 (+ - * /)