python使用selenium打开chrome浏览器时带用户登录信息实现过程详解
导读
我们在使用selenium打开google浏览器的时候,默认打开的是一个新的浏览器窗口,而且里面不带有任何的浏览器缓存信息。当我们想要爬取某个网站信息或者做某些操作的时候就需要自己再去模拟登陆
selenium操作浏览器
这里我们就以CSDN为例,来展示如何让selenium在打开chrome浏览器的时候带上用户的登录信息
打开chrome浏览器
from selenium import webdriver from selenium.webdriver import ChromeOptions #设置操作的网站 web_url = "https://bbs.csdn.net" browser = webdriver.Chrome(executable_path=r"D:\chromedriver_win32\chromedriver\chromedriver.exe") #打开网页 browser.get(web_url)
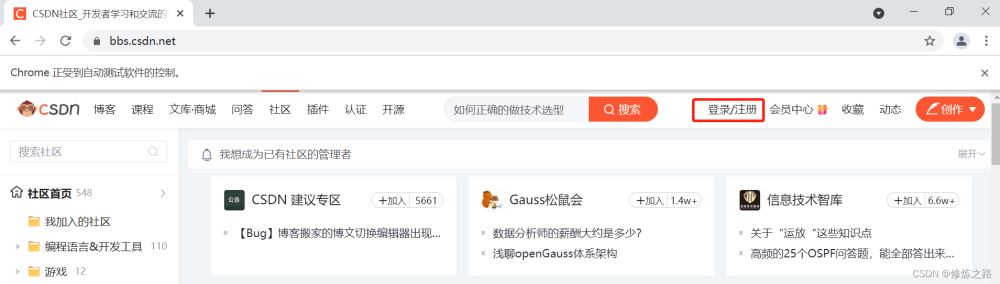
运行程序之后,打开浏览器的界面如上图所示,可以看出来默认是没有带用户的登录信息的
带用户登录信息打开chrome浏览器
1.打开带有用户信息的chrome窗口
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" -remote-debugging-port=9014 --user-data-dir="C:\\Users\\15053\AppData\Local\Google\Chrome\\User Data"
因为安装chrome的时候是采用的默认安装路径,所以路径就和上面一样。如果安装的时候自定义了路径,就注意修改一下chrome.exe的路径。
user-data目录是chrome缓存数据的目录,里面包含了用户的登录信息。如果你是在你自己的电脑上使用,需要将15053修改成你自己的用户名。
注意:在执行上面命令的时候建议关闭chrome浏览器,否则后面在执行python程序的时候,可能无法连接到chrome。
2.使用selenium打开网站
from selenium import webdriver
from selenium.webdriver import ChromeOptions
web_url = "https://bbs.csdn.net"
#加载cookies中已经保存的账号和密码
options = ChromeOptions()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9014")
browser = webdriver.Chrome(executable_path=r"D:\chromedriver_win32\chromedriver\chromedriver.exe",
chrome_options=options)
browser.get(web_url)
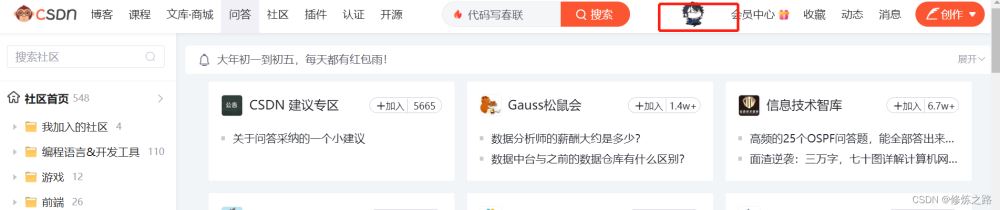
可以看到,此时打开的网站已经自带了用户的登录信息
到此这篇关于详解C语言fscanf函数读取文件教程及源码的文章就介绍到这了,更多相关C语言fscanf读取文件教程内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python用selenium打开chrome浏览器保持登录方式
目录 导读 selenium操作浏览器 打开chrome浏览器 使用selenium打开网站 总结 导读 我们在使用selenium打开google浏览器的时候,默认打开的是一个新的浏览器窗口,而且里面不带有任何的浏览器缓存信息.当我们想要爬取某个网站信息或者做某些操作的时候就需要自己再去模拟登陆 selenium操作浏览器 这里我们就以CSDN为例,来展示如何让selenium在打开chrome浏览器的时候带上用户的登录信息 打开chrome浏览器 from selenium import w
-
selenium+python配置chrome浏览器的选项的实现
1. 背景 在使用selenium浏览器渲染技术,爬取网站信息时,默认情况下就是一个普通的纯净的chrome浏览器,而我们平时在使用浏览器时,经常就添加一些插件,扩展,代理之类的应用.相对应的,当我们用chrome浏览器爬取网站时,可能需要对这个chrome做一些特殊的配置,以满足爬虫的行为. 常用的行为有: 禁止图片和视频的加载:提升网页加载速度. 添加代理:用于翻墙访问某些页面,或者应对IP访问频率限制的反爬技术. 使用移动头:访问移动端的站点,一般这种站点的反爬技术比较薄弱. 添加扩展:像
-
python使用selenium打开chrome浏览器时带用户登录信息实现过程详解
导读 我们在使用selenium打开google浏览器的时候,默认打开的是一个新的浏览器窗口,而且里面不带有任何的浏览器缓存信息.当我们想要爬取某个网站信息或者做某些操作的时候就需要自己再去模拟登陆 selenium操作浏览器 这里我们就以CSDN为例,来展示如何让selenium在打开chrome浏览器的时候带上用户的登录信息 打开chrome浏览器 from selenium import webdriver from selenium.webdriver import ChromeOpti
-
Java解压和压缩带密码的zip文件过程详解
前言 JDK自带的ZIP操作接口(java.util.zip包,请参看文章末尾的博客链接)并不支持密码,甚至也不支持中文文件名. 为了解决ZIP压缩文件的密码问题,在网上搜索良久,终于找到了winzipaes开源项目. 该项目在google code下托管 ,仅支持AES压缩和解压zip文件( This library only supports Win-Zip's 256-Bit AES mode.).网站上下载的文件是源代码,最新版本为winzipaes_src_20120416.zip,本
-
OpenCV Python身份证信息识别过程详解
目录 前置环境 识别过程 身份证区域查找 原始图像 灰度处理 中值滤波 二值处理 边缘检测 边缘膨胀 轮廓检测 轮廓排序 透视变换 固定图像大小 检测身份证文本位置 极度膨胀 轮廓查找文本区域 筛选出文本区域 对文本区域进行排序 识别文本 结语 代码 本篇文章使用OpenCV-Python和CnOcr来实现身份证信息识别的案例.想要识别身份证中的文本信息,总共分为三大步骤:一.通过预处理身份证区域检测查找:二.身份证文本信息提取:三.身份证文本信息识别.下面来看一下识别的具体过程CnOcr官网.
-
Python使用Selenium模块模拟浏览器抓取斗鱼直播间信息示例
本文实例讲述了Python使用Selenium模块模拟浏览器抓取斗鱼直播间信息.分享给大家供大家参考,具体如下: import time from multiprocessing import Pool from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.web
-
对Python发送带header的http请求方法详解
简单的header import urllib2 request = urllib2.Request('http://example.com/') request.add_header('User-Agent', 'fake-client') response = urllib2.urlopen(request) print request.read() 包含较多元素的header import urllib,urllib2 url = 'http://example.com/' headers
-
Python 带星号(* 或 **)的函数参数详解
1. 带默认值的参数 在了解带星号(*)的参数之前,先看下带有默认值的参数,函数定义如下: >> def defaultValueArgs(common, defaultStr = "default", defaultNum = 0): print("Common args", common) print("Default String", defaultStr) print("Default Number", d
-
基于python中pygame模块的Linux下安装过程(详解)
一.使用pip安装Python包 大多数较新的Python版本都自带pip,因此首先可检查系统是否已经安装了pip.在Python3中,pip有时被称为pip3. 1.在Linux和OS X系统中检查是否安装了pip 打开一个终端窗口,并执行如下命令: Python2.7中: zhuzhu@zhuzhu-K53SJ:~$ pip --version pip 8.1.1 from /usr/lib/python2.7/dist-packages (python 2.7) Python3.X中: z
-
Python中使用pypdf2合并、分割、加密pdf文件的代码详解
朋友需要对一个pdf文件进行分割,在网上查了查发现这个pypdf2可以完成这些操作,所以就研究了下这个库,并做一些记录.首先pypdf2是python3版本的,在之前的2版本有一个对应pypdf库. 可以使用pip直接安装: pip install pypdf2 官方文档: pythonhosted.org/PyPDF2/ 里面主要有这几个类: PdfFileReader . 该类主要提供了对pdf文件的读操作,其构造方法为: PdfFileReader(stream, strict=True,
-
python初学之用户登录的实现过程(实例讲解)
要求编写登录接口: 1. 输入用户名和密码 2.认证成功后显示欢迎信息 3.用户名输错,提示用户不存在,重新输入(5次错误,提示尝试次数过多,退出程序) 4.用户名正确,密码错误,提示密码错误,重新输入.(密码错误3次,锁定用户名并提示,退出程序) readme 应用知识点: 一.文件的操作 基本操作 f = open('lyrics','r',) #打开文件 first_line = f.readline() print('first line:',first_line) #读一行 data