springboot 整合canal实现示例解析
目录
- 前言
- 环境准备
- 一、快速搭建canal服务
- 搭建步骤
- 1、服务器使用docker快速安装一个mysql并开启binlog日志
- 2、上传canal安装包并解压
- 3、进入到第二步解压后的文件目录,并修改配置文件
- 4、启动canal服务
- 二、与springboot整合
- 1、Java中使用canal
- 2、编写一个demo
- 3、与springboot整合
- 4、application.yml 配置文件
- 5、核心工具类
- 6、提供一个配置类,在程序启动后监听数据变化
- 7、启动类
前言
在Mysql到Elasticsearch高效实时同步Debezium实现,分析并实战演示了如何利用debezium完成数据从mysql到es的准实时同步过程。
本篇将基于已经构建好的canal服务,演示在代码中如何利用canal完成一些业务场景的使用
环境准备
- 已经搭建好的canal服务
- 两个不同环境(IP)下的mysql服务
一、快速搭建canal服务
为方便后文的演示和学习,以便看到的同学能体验到完整的操作流程,在正式编写代码之前,先基于centos7环境快速搭建起一个canal服务
搭建步骤
1、服务器使用docker快速安装一个mysql并开启binlog日志
具体可参考:docker开启mysql的binlog日志解决数据卷问题
2、上传canal安装包并解压

tar -zxvf canal.deployer-1.1.2.tar.gz -C /opt/module/canal
3、进入到第二步解压后的文件目录,并修改配置文件
进入conf目录,需要的修改的配置文件为:canal.properties

################################################# ######### common argument ############# ################################################# canal.id = 1 canal.ip = canal.port = 11111 canal.metrics.pull.port = 11112 canal.zkServers = # flush data to zk canal.zookeeper.flush.period = 1000 canal.withoutNetty = false # tcp, kafka, RocketMQ canal.serverMode = tcp # flush meta cursor/parse position to file
说明:这个文件是 canal 的基本通用配置,canal 端口号默认就是 11111,修改 canal 的
输出 model,默认 tcp,改为输出到 kafka
重点关注上面的:canal.serverMode = tcp 这个配置,默认情况,如果是使用mysql,可以不做修改,如果需要将数据同步到kafka,或者rocketmq,可以分别修改即可,此处暂不做修改
进入example目录,需要的修改的配置文件为:instance.properties
################################################# ## mysql serverId , v1.0.26+ will autoGen canal.instance.mysql.slaveId=20 #只要和mysql的master的不一样即可 # enable gtid use true/false canal.instance.gtidon=false # position info canal.instance.master.address=127.0.0.1:3306
- canal.instance.mysql.slaveId=20 #只要和mysql的master的不一样即可
- canal.instance.master.address=127.0.0.1:3306 ,监听的mysql的master节点信息
配置连接 MySQL 的用户名和密码,默认就是我们前面授权的 canal
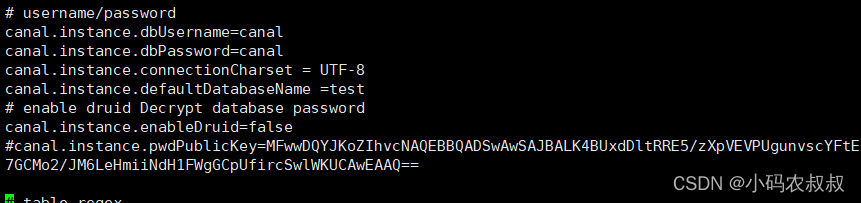
4、启动canal服务
返回到bin目录,直接: startup.sh

二、与springboot整合
搭建好了canal服务,如何在业务中使用呢?其实在很场景下,可以考虑借助canal实现一些诸如数据同步、灾备、同城双活等,比如来考虑这样一种场景,一些比较大的电商页面上,都有商品搜索服务,用户输入商品关键字可以快速检索到商品
基本上搜索服务都是采用了诸如es这样的搜索引擎,思考一下,网站的所有上架的商品数据开始肯定是存放在mysql这样的关系型数据库,但是搜索走mysql的话肯定不可能,所以需要定期或者准实时的将mysql的数据同步到es
在之前的某一篇中,我们可以直接基于canal做配置,将mysql的数据同步到es中
但是考虑到数据并非所有的都同步,比如说要对同步到es的数据进行分类、筛选、过滤等操作,纯粹的配置就很难胜任了
于是,可以考虑在程序中,通过某种机制监听到mysql中的商品上架数据的变化然后触发程序,再通过程序将数据写入到es,实现准实时同步
在上面的这种业务场景下,canal就是一种很好的选择
1、Java中使用canal
导入基本的依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.2</version>
</dependency>
2、编写一个demo
通过客户端,连接canal的信息,可以在程序中监听到mysql的master节点数据变化
下面直接贴出核心代码:
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.ByteString;
import java.net.InetSocketAddress;
import java.util.List;
public class CanalClient {
public static void main(String[] args) throws Exception{
//1.获取 canal 连接对象
CanalConnector canalConnector =
CanalConnectors.newSingleConnector(new
InetSocketAddress("canal所在服务器IP", 11111), "example", "", "");
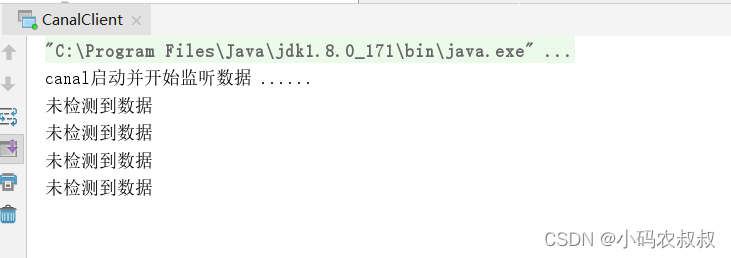
System.out.println("canal启动并开始监听数据 ...... ");
while (true){
canalConnector.connect();
//订阅表
canalConnector.subscribe("shop001.*");
//获取数据
Message message = canalConnector.get(100);
//解析message
List<CanalEntry.Entry> entries = message.getEntries();
if(entries.size() <=0){
System.out.println("未检测到数据");
Thread.sleep(1000);
}
for(CanalEntry.Entry entry : entries){
//1、获取表名
String tableName = entry.getHeader().getTableName();
//2、获取类型
CanalEntry.EntryType entryType = entry.getEntryType();
//3、获取序列化后的数据
ByteString storeValue = entry.getStoreValue();
//判断是否rowdata类型数据
if(CanalEntry.EntryType.ROWDATA.equals(entryType)){
//对第三步中的数据进行解析
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
//获取当前事件的操作类型
CanalEntry.EventType eventType = rowChange.getEventType();
//获取数据集
List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();
//便利数据
for(CanalEntry.RowData rowData : rowDatasList){
//数据变更之前的内容
JSONObject beforeData = new JSONObject();
List<CanalEntry.Column> beforeColumnsList = rowData.getAfterColumnsList();
for(CanalEntry.Column column : beforeColumnsList){
beforeData.put(column.getName(),column.getValue());
}
//数据变更之后的内容
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
JSONObject afterData = new JSONObject();
for(CanalEntry.Column column : afterColumnsList){
afterData.put(column.getName(),column.getValue());
}
System.out.println("Table :" + tableName +
",eventType :" + eventType +
",beforeData :" + beforeData +
",afterData : " + afterData);
}
}else {
System.out.println("当前操作类型为:" + entryType);
}
}
}
}
}
关于API的使用,可以参考官方的demo示例代码,核心的代码处理步骤大概如下:
- 建立连接
- 订阅指定数据库(或者所有数据库,或某个库下的表)
- 检测到数据变更
- 提取binlog中的元数据,解析变更数据类型,解析元数据中的信息
- 基于变更数据做自身的业务逻辑或其他业务
下面运行上面的代码,这时候我们去数据库中修改一下本次订阅的数据库下的某个表的数据
接下来去 shop001数据库中给 user_info表新增一条数据


执行sql,然后观察控制台日志输出
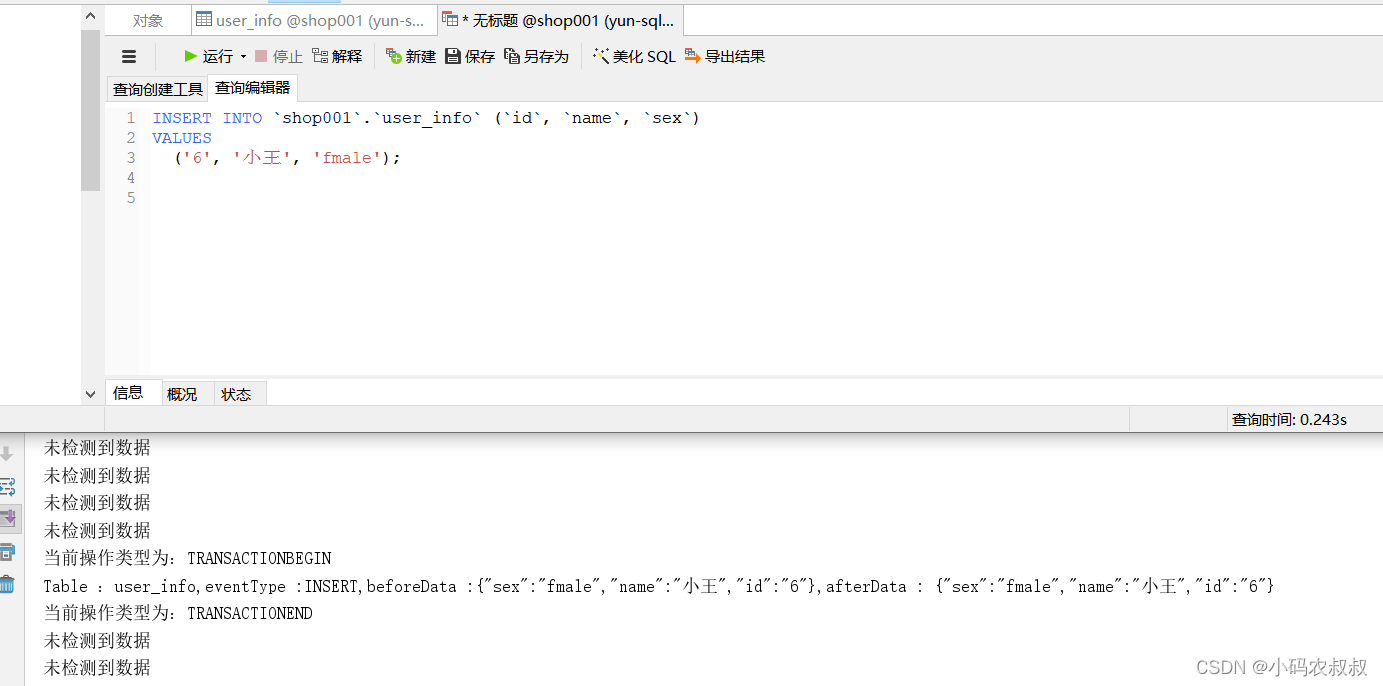
我们再次修改其中一条数据,很快控制台上输出了数据更改前和修改后的数据信息日志

由此我们得知,基于上面解析出来的信息,可以检测到数据库中某些表的变化情况,从而将变化后的数据做同步或者接入其他的中间件进行消息通知等
3、与springboot整合
接下来,我们仍然以一个具体的业务场景为例
需求描述:将从canal中读取到的数据同步变更到另一个数据库下相同的表中
导入下面依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.4</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba.otter/canal.client -->
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.14</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-dbutils/commons-dbutils -->
<dependency>
<groupId>commons-dbutils</groupId>
<artifactId>commons-dbutils</artifactId>
<version>1.7</version>
</dependency>
<!--canal客户端连接-->
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
</dependencies>
4、application.yml 配置文件
注意,这里连接的数据库地址是目标数据库,即从canal中读取并解析后的数据即将写入的服务器地址
server:
port: 8083
logging:
config: classpath:logback-spring.xml #日志
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://IP:3306/bank1?autoReconnect=true&useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false
username: root
password: root
druid:
max-active: 100
initial-size: 10
max-wait: 60000
min-idle: 5
5、核心工具类
其实我们可以直接拿上面的演示代码,在里面做业务逻辑的处理也可以,不过在实际项目中,这样做不便于代码的维护性和可阅读性,因此需要根据功能封装一些方法形成可复用的工具类
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.ByteString;
import com.google.protobuf.InvalidProtocolBufferException;
import org.apache.commons.dbutils.DbUtils;
import org.apache.commons.dbutils.QueryRunner;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import javax.sql.DataSource;
import java.net.InetSocketAddress;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
@Component
public class CanalClient {
private Queue<String> SQL_QUEUE = new ConcurrentLinkedQueue<>();
@Resource
private DataSource dataSource;
/**
* canal入库方法
*/
public void handleMessages() {
CanalConnector connector = CanalConnectors.newSingleConnector(new
InetSocketAddress("canal所在的服务IP",
11111), "example", "", "");
int batchSize = 1000;
System.out.println("canal启动并开始监听数据 ...... ");
try {
connector.connect();
connector.subscribe("shop001.*");
connector.rollback();
try {
while (true) {
//尝试从master那边拉去数据batchSize条记录,有多少取多少
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
System.out.println("未检测到任何数据变化......");
Thread.sleep(2000);
} else {
dataHandle(message.getEntries());
}
connector.ack(batchId);
//当队列里面堆积的sql大于一定数值的时候就模拟执行
if (SQL_QUEUE.size() >= 1) {
executeQueueSql();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
} finally {
connector.disconnect();
}
}
/**
* 模拟执行队列里面的sql语句
*/
public void executeQueueSql() {
int size = SQL_QUEUE.size();
for (int i = 0; i < size; i++) {
String sql = SQL_QUEUE.poll();
System.out.println("[sql]----> " + sql);
this.execute(sql.toString());
}
}
/**
* 数据处理
* @param entrys
*/
private void dataHandle(List<Entry> entrys) throws InvalidProtocolBufferException {
for (Entry entry : entrys) {
if (EntryType.ROWDATA == entry.getEntryType()) {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
EventType eventType = rowChange.getEventType();
if (eventType == EventType.DELETE) {
saveDeleteSql(entry);
} else if (eventType == EventType.UPDATE) {
saveUpdateSql(entry);
} else if (eventType == EventType.INSERT) {
saveInsertSql(entry);
}
}
}
}
/**
* 保存更新语句
* @param entry
*/
private void saveUpdateSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> newColumnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("update " + entry.getHeader().getTableName() + " set ");
for (int i = 0; i < newColumnList.size(); i++) {
sql.append(" " + newColumnList.get(i).getName() + " = '" + newColumnList.get(i).getValue() + "'");
if (i != newColumnList.size() - 1) {
sql.append(",");
}
}
sql.append(" where ");
List<Column> oldColumnList = rowData.getBeforeColumnsList();
for (Column column : oldColumnList) {
if (column.getIsKey()) {
//暂时只支持单一主键
sql.append(column.getName() + "=" + column.getValue());
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* 保存删除语句
*
* @param entry
*/
private void saveDeleteSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> columnList = rowData.getBeforeColumnsList();
StringBuffer sql = new StringBuffer("delete from " + entry.getHeader().getTableName() + " where ");
for (Column column : columnList) {
if (column.getIsKey()) {
//暂时只支持单一主键
sql.append(column.getName() + "=" + column.getValue());
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* 保存插入语句
*
* @param entry
*/
private void saveInsertSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> columnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("insert into "+ entry.getHeader().getTableName() + " (");
for (int i = 0; i < columnList.size(); i++) {
sql.append(columnList.get(i).getName());
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(") VALUES (");
for (int i = 0; i < columnList.size(); i++) {
sql.append("'" + columnList.get(i).getValue() + "'");
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(")");
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* 入库
* @param sql
*/
public void execute(String sql) {
Connection con = null;
try {
if(null == sql) return;
con = dataSource.getConnection();
QueryRunner qr = new QueryRunner();
int row = qr.execute(con, sql);
System.out.println("update: "+ row);
} catch (SQLException e) {
e.printStackTrace();
} finally {
DbUtils.closeQuietly(con);
}
}
}
6、提供一个配置类,在程序启动后监听数据变化
@Configuration
public class InitConfig implements CommandLineRunner {
@Resource
private CanalClient canalClient;
@Override
public void run(String... args) throws Exception {
canalClient.handleMessages();
}
}
7、启动类
@SpringBootApplication
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class,args);
}
}
提前在目标写入的数据库中准备一张相同的表
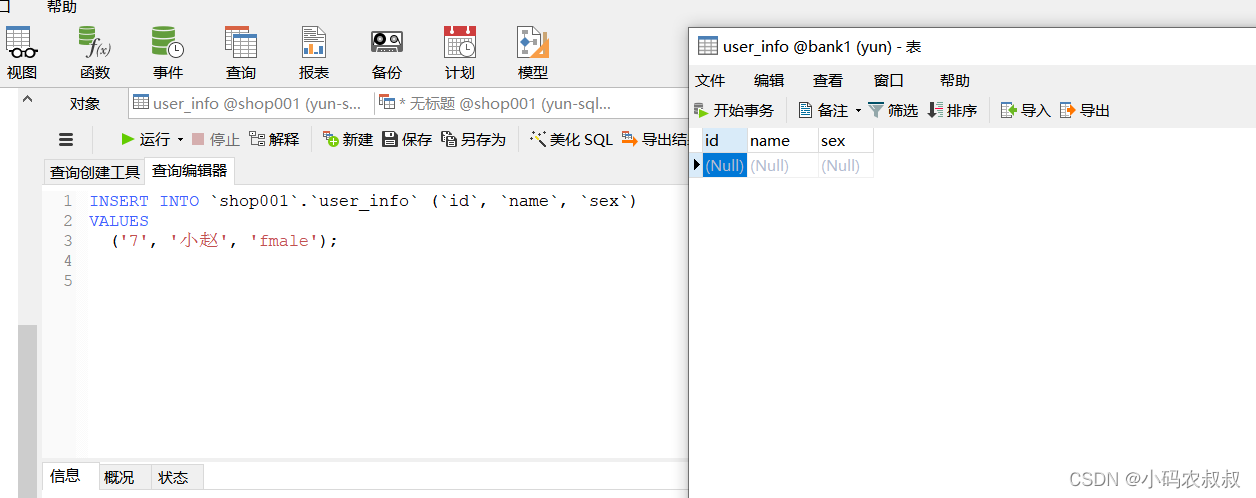
启动程序后,往canal服务监听的mysql服务数据库的user_info表中插入上面的一条新数据,然后观察控制台输出日志信息,

执行数据插入,这时候控制台检测到了数据变化

同时目标数据表中也新增了一条数据,
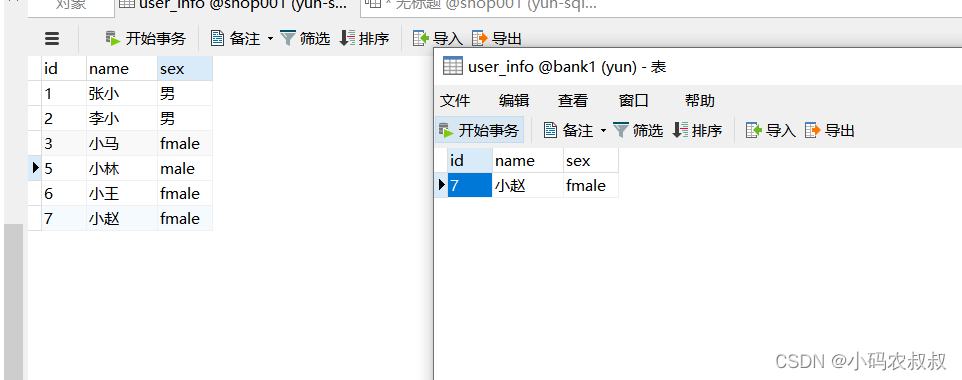
通过上面的操作,就完成了预期的需求,当然基于此业务逻辑,还可以衍生出更多的需求场景,比如只监听变化的数据,然后通知下游的其他应用等。
以上就是springboot 整合canal实现示例解析的详细内容,更多关于springboot整合canal的资料请关注我们其它相关文章!
相关推荐
-

springboot整合多数据源配置方式
目录 简介 一.表结构 二.多数据源整合 1. springboot+mybatis使用分包方式整合 1.1 主要依赖包 1.2 application.yml 配置文件 1.3 建立连接数据源的配置文件 1.4 具体实现 2. springboot+druid+mybatisplus使用注解整合 2.1 主要依赖包 2.2 application.yml 配置文件 2.3 给使用非默认数据源添加注解@DS 简介 主要介绍两种整合方式,分别是 springboot+mybatis 使用分包方式整
-
SpringBoot整合ElasticSearch的示例代码
ElasticSearch作为基于Lucene的搜索服务器,既可以作为一个独立的服务部署,也可以签入Web应用中.SpringBoot作为Spring家族的全新框架,使得使用SpringBoot开发Spring应用变得非常简单.本文要介绍如何整合ElasticSearch与SpringBoot. 实体设计: 每一本书(Book)都属于一个分类(Classify),都有一个作者(Author). 生成这个三个实体类,并实现其get和set方法. SpringBoot配置修改: 1.修改pom.xm
-
springboot整合token的实现代码
写在前面 在前后端交互过程中,为了保证信息安全,我们往往需要加点用户验证.本文介绍了用springboot简单整合token. springboot版本2.2.0.另外主要用到了jjwt,redis.阅读本文,你大概需要花费7-10分钟时间 整合token 1. 导入相关依赖 pom.xml文件中 <!-- jwt 加密解密工具类--> <dependency> <groupId>io.jsonwebtoken</groupId> <artifactI
-
springboot与mybatis整合实例详解(完美融合)
简介 从 Spring Boot 项目名称中的 Boot 可以看出来,Spring Boot 的作用在于创建和启动新的基于 Spring 框架的项目.它的目的是帮助开发人员很容易的创建出独立运行和产品级别的基于 Spring 框架的应用.Spring Boot 会选择最适合的 Spring 子项目和第三方开源库进行整合.大部分 Spring Boot 应用只需要非常少的配置就可以快速运行起来. Spring Boot 包含的特性如下: 创建可以独立运行的 Spring 应用. 直接嵌入 Tomc
-
SpringBoot整合JPA的实例代码
JPA全称Java Persistence API.JPA通过JDK 5.0注解或XML描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中. JPA 的目标之一是制定一个可以由很多供应商实现的API,并且开发人员可以编码来实现该API,而不是使用私有供应商特有的API. JPA是需要Provider来实现其功能的,hibernate就是JPA Provider中很强的一个,应该说无人能出其右.从功能上来说,JPA就是Hibernate功能的一个子集. 添加相关依赖 添加spring
-
SpringBoot整合OpenCV的实现示例
简介 接下来会讲解怎么用SpringBoot整合OpenCV 初始化SpringBoot项目 这里正常初始一个SpringBoot项目 依赖文件 在安装目录下找到以下两个文件,如果不知道怎么安装OpenCV,可查看这篇文章,Windows下安装OpenCV opencv\build\java\opencv-420.jar opencv\build\java\x64\opencv_java420.dll 在resource目录下新建一个lib文件夹,然后将两个文件复制到resource\lib下
-
springboot 整合canal实现示例解析
目录 前言 环境准备 一.快速搭建canal服务 搭建步骤 1.服务器使用docker快速安装一个mysql并开启binlog日志 2.上传canal安装包并解压 3.进入到第二步解压后的文件目录,并修改配置文件 4.启动canal服务 二.与springboot整合 1.Java中使用canal 2.编写一个demo 3.与springboot整合 4.application.yml 配置文件 5.核心工具类 6.提供一个配置类,在程序启动后监听数据变化 7.启动类 前言 在Mysql到Ela
-
SpringBoot整合canal实现数据同步的示例代码
目录 一.前言 二.docker-compose部署canal 三.canal-admin可视化管理 四.springboot整合canal实现数据同步 五.canal-spring-boot-starter 一.前言 canal:阿里巴巴 MySQL binlog 增量订阅&消费组件https://github.com/alibaba/canal tips: 环境要求和配置参考 https://github.com/alibaba/canal/wiki/AdminGuide 这里额外提下Red
-
SpringBoot整合Canal与RabbitMQ监听数据变更记录
目录 需求 步骤 环境搭建 canal.properties instance.properties 修改canal配置文件 整合SpringBoot Canal实现客户端 Canal整合RabbitMQ SpringBoot整合RabbitMQ 需求 我想要在SpringBoot中采用一种与业务代码解耦合的方式,来实现数据的变更记录,记录的内容是新数据,如果是更新操作还得有旧数据内容. 经过调研发现,使用Canal来监听MySQL的binlog变化可以实现这个需求,可是在监听到变化后需要马上保
-
SpringBoot整合Junit实例过程解析
这篇文章主要介绍了SpringBoot整合Junit实例过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 前提条件:SpringBoot已经整合了Mybatis,至于SpringBoot如何整合Mybatis可参考SpringBoot整合mybatis简单案例过程解析 SpringBoot为什么要整合Juni? SpringBoot整合了Junit后,在写了Mapper接口后,可直接通过Junit进行测试,不用再写Controller层,
-
Springboot整合通用mapper过程解析
这篇文章主要介绍了springboot整合通用mapper过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 找到springboot工程下的pom.xml文件,导入如下的依赖jar包 <!--配置通用Mapper start--> <dependency> <groupId>tk.mybatis</groupId> <artifactId>mapper-spring-boot-starte
-
SpringBoot整合Dubbo zookeeper过程解析
这篇文章主要介绍了SpringBoot整合Dubbo zookeeper过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 docker pull zookeeper docker run --name zk01 -p 2181:2181 --restart always -d 2e30cac00aca 表明zookeeper已成功启动 Zookeeper和Dubbo• ZooKeeperZooKeeper 是一个分布式的,开放源码的分布式
-
Springboot整合GuavaCache缓存过程解析
这篇文章主要介绍了springboot整合GuavaCache缓存过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Guava Cache是一种本地缓存机制,之所以叫本地缓存,是因为它不会把缓存数据放到外部文件或者其他服务器上,而是存放到了应用内存中. Guava Cache的优点是:简单.强大.轻量级. GuavaCache适用场景: 1.某些接口或者键值会被查询多次以上: 2.愿意使用或牺牲一些内存空间来提升访问或者计算速度: 3.缓
-
关于SpringBoot整合Canal数据同步的问题
目录 1.CentOS7编译安装MySQL5.7.24 2.Mysql设置binLog配置 3.Linux下载安装Canal服务 4.Boot项目中引入依赖 5.修改properties配置文件 6.修改Application启动类 7.创建Canal配置类自动监听 1.CentOS7编译安装MySQL5.7.24 CentOS7编译安装MySQL5.7.24的教程详解 链接地址:https://www.jb51.net/article/152246.htm 2.Mysql设置binLog配置
-
springboot 整合hbase的示例代码
目录 前言 HBase 定义 HBase 数据模型 物理存储结构 数据模型 1.Name Space 2.Region 3.Row 4.Column 5.Time Stamp 6.Cell 搭建步骤 1.官网下载安装包: 2.配置hadoop环境变量 3.修改 hbase-env.cmd配置文件 4.修改hbase-site.xml 文件 5.启动hbase服务 6.hbase客户端测试 Java API详细使用 1.导入客户端依赖 2.DDL相关操作 3.DML相关操作 插入数据与查询数据 H
-
SpringBoot 整合 JMSTemplate的示例代码
1.1 添加依赖 可以手动在 SpringBoot 项目添加依赖,也可以在项目创建时选择使用 ActiveMQ 5 自动添加依赖.高版本 SpringBoot (2.0 以上) 在添加 activemq 连接池依赖启动时会报 Error creating bean with name 'xxx': Unsatisfied dependency expressed through field 'jmsTemplate'; 可以将 activemq 连接池换成 jms 连接池解决. <depen