Python爬虫urllib和requests的区别详解
我们讲了requests的用法以及利用requests简单爬取、保存网页的方法,这节课我们主要讲urllib和requests的区别。
1、获取网页数据
第一步,引入模块。
两者引入的模块是不一样的,这一点显而易见。

第二步,简单网页发起的请求。
urllib是通过urlopen方法获取数据。
requests需要通过网页的响应类型获取数据。

第三步,数据封装。
对于复杂的数据请求,我们只是简单的通过urlopen方法肯定是不行的。最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃苦,建议你可以联系维:762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
urllib中,我们知道对于有反爬虫机制的网站,我们需要对URL进行封装,以获取到数据。我们可以回顾下前几节课的内容:
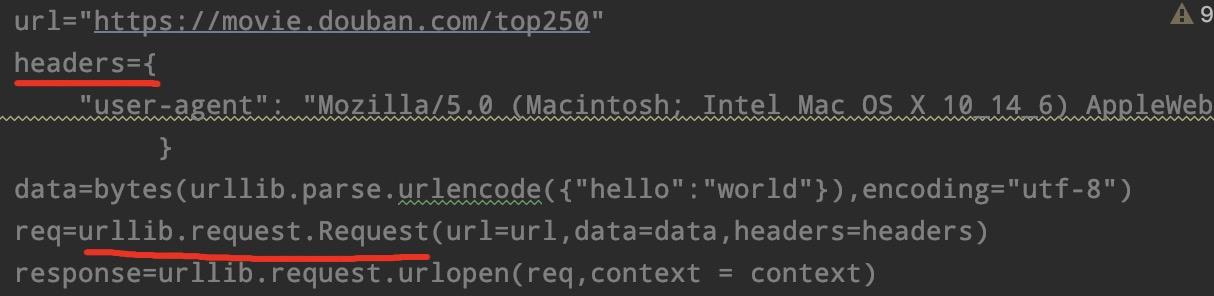
requests模块中,就不需要这么复杂的操作,直接在第二步中,加入参数headers即可:

2、解析网页数据
urllib和requests都可以通过bs4和re进行数据的解析,requests还可以通过xpath进行解析。具体解析方法之后会详解
3.保存数据
urllib需要引入xlwt模块进行新建表格、sheet表格写入数据.最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃苦,建议你可以联系维:762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~

requests通过with…as直接虚入数据:

到此这篇关于Python爬虫urllib和requests的区别详解的文章就介绍到这了,更多相关Python爬虫urllib和requests的区别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python接口自动化之浅析requests模块get请求
一.requests模块说明 介绍 Requests是Python语言的第三方的库,专门用于发送HTTP请求. 特点 1.Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动响应内容的编码,支持国际化的URL和POST数据自动编码. 2.在python内置模块的基础上进行了高度的封装,从而使得python进行网络请求时,变得人性化,使用Requests可以轻而易举的完成浏览器可有的任何操作. 3.Requests会自动实现持久连接keep-alive
-
python爬虫开发之使用python爬虫库requests,urllib与今日头条搜索功能爬取搜索内容实例
使用python爬虫库requests,urllib爬取今日头条街拍美图 代码均有注释 import re,json,requests,os from hashlib import md5 from urllib.parse import urlencode from requests.exceptions import RequestException from bs4 import BeautifulSoup from multiprocessing import Pool #请求索引页 d
-
python中urllib.request和requests的使用及区别详解
urllib.request 我们都知道,urlopen()方法能发起最基本对的请求发起,但仅仅这些在我们的实际应用中一般都是不够的,可能我们需要加入headers之类的参数,那需要用功能更为强大的Request类来构建了 在不需要任何其他参数配置的时候,可直接通过urlopen()方法来发起一个简单的web请求 发起一个简单的请求 import urllib.request url='https://www.douban.com' webPage=urllib.request.urlopen(
-
详解Python requests模块
前言 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 "HTTP for Humans",说明使用更简洁方便. Requests 继承了urllib2的所有特性.Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码. 开源地址:https://github.com/ke
-
Python爬虫urllib和requests的区别详解
我们讲了requests的用法以及利用requests简单爬取.保存网页的方法,这节课我们主要讲urllib和requests的区别. 1.获取网页数据 第一步,引入模块. 两者引入的模块是不一样的,这一点显而易见. 第二步,简单网页发起的请求. urllib是通过urlopen方法获取数据. requests需要通过网页的响应类型获取数据. 第三步,数据封装. 对于复杂的数据请求,我们只是简单的通过urlopen方法肯定是不行的.最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕
-
python爬虫 urllib模块url编码处理详解
案例:爬取使用搜狗根据指定词条搜索到的页面数据(例如爬取词条为'周杰伦'的页面数据) import urllib.request # 1.指定url url = 'https://www.sogou.com/web?query=周杰伦' ''' 2.发起请求:使用urlopen函数对指定的url发起请求, 该函数返回一个响应对象,urlopen代表打开url ''' response = urllib.request.urlopen(url=url) # 3.获取响应对象中的页面数据:read函
-
Python3网络爬虫中的requests高级用法详解
本节我们再来了解下 Requests 的一些高级用法,如文件上传,代理设置,Cookies 设置等等. 1. 文件上传 我们知道 Reqeuests 可以模拟提交一些数据,假如有的网站需要我们上传文件,我们同样可以利用它来上传,实现非常简单,实例如下: import requests files = {'file': open('favicon.ico', 'rb')} r = requests.post('http://httpbin.org/post', files=files) print
-
基于python中staticmethod和classmethod的区别(详解)
例子 class A(object): def foo(self,x): print "executing foo(%s,%s)"%(self,x) @classmethod def class_foo(cls,x): print "executing class_foo(%s,%s)"%(cls,x) @staticmethod def static_foo(x): print "executing static_foo(%s)"%x a=A(
-
python爬虫之BeautifulSoup 使用select方法详解
本文介绍了python爬虫之BeautifulSoup 使用select方法详解 ,分享给大家.具体如下: <html><head><title>The Dormouse's story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse's story</b></
-
python中import reload __import__的区别详解
import 作用:导入/引入一个python标准模块,其中包括.py文件.带有__init__.py文件的目录(自定义模块). import module_name[,module1,...] from module import *|child[,child1,...] 注意:多次重复使用import语句时,不会重新加载被指定的模块,只是把对该模块的内存地址给引用到本地变量环境. 实例: pythontab.py #!/usr/bin/env python #encoding: utf-8
-
基于Python中capitalize()与title()的区别详解
capitalize()与title()都可以实现字符串首字母大写. 主要区别在于: capitalize(): 字符串第一个字母大写 title(): 字符串内的所有单词的首字母大写 例如: >>> str='huang bi quan' >>> str.capitalize() 'Huang bi quan' #第一个字母大写 >>> str.title() 'Huang Bi Quan' #所有单词的首字母大写 非字母开头的情况: >>
-
对Python协程之异步同步的区别详解
一下代码通过协程.多线程.多进程的方式,运行代码展示异步与同步的区别. import gevent import threading import multiprocessing # 这里展示同步和异步的性能区别,可以看到异步直接同时执行并完成, # 而同步,需要等待第一个完成后再次执行下一个,是有顺序的执行,而异步不需要 import time def task(pid): gevent.sleep(0.5) print('Task %s done' % pid) def task2(pid)
-
对Python中Iterator和Iterable的区别详解
Python中 list,truple,str,dict这些都可以被迭代,但他们并不是迭代器.为什么? 因为和迭代器相比有一个很大的不同,list/truple/map/dict这些数据的大小是确定的,也就是说有多少事可知的.但迭代器不是,迭代器不知道要执行多少次,所以可以理解为不知道有多少个元素,每调用一次next(),就会往下走一步,是惰性的. 判断是不是可以迭代,用Iterable from collections import Iterable isinstance({}, Iterab
-
Python中生成器和迭代器的区别详解
Python中生成器和迭代器的区别(代码在Python3.5下测试): Num01–>迭代器 定义: 对于list.string.tuple.dict等这些容器对象,使用for循环遍历是很方便的.在后台for语句对容器对象调用iter()函数.iter()是python内置函数. iter()函数会返回一个定义了next()方法的迭代器对象,它在容器中逐个访问容器内的元素.next()也是python内置函数.在没有后续元素时,next()会抛出一个StopIteration异常,通知for语句