Python爬虫抓取论坛关键字过程解析
前言:
之前学习了用python爬虫的基本知识,现在计划用爬虫去做一些实际的数据统计功能。由于前段时间演员的诞生带火了几个年轻的实力派演员,想用爬虫程序搜索某论坛中对于某些演员的讨论热度,并按照日期统计每天的讨论量。
这个项目总共分为两步:
1.获取所有帖子的链接:
将最近一个月内的帖子链接保存到数组中
2.从回帖中搜索演员名字:
从数组中打开链接,翻出该链接的所有回帖,在回帖中查找演员的名字
获取所有帖子的链接:
搜索的范围依然是以虎扑影视区为界限。虎扑影视区一天约5000个回帖,一月下来超过15万回帖,作为样本来说也不算小,有一定的参考价值。
完成这一步骤,主要分为以下几步:
1.获取当前日期
2.获取30天前的日期
3.记录从第一页往后翻的所有发帖链接
1.获取当前日期
这里我们用到了datetime模块。使用datetime.datetime.now(),可以获取当前的日期信息以及时间信息。在这个项目中,只需要用到日期信息就好。
2.获取30天前的日期
用datetime模块的优点在于,它还有一个很好用的函数叫做timedelta,可以自行计算时间差。当给定参数days=30时,就会生成30天的时间差,再用当前日期减去delta,可以得到30天前的日期,将该日期保存为startday,即开始进行统计的日期。不然计算时间差需要自行考虑跨年闰年等因素,要通过一个较为复杂的函数才可以完成。
today = datetime.datetime.now()
delta = datetime.timedelta(days=30)
i = "%s" %(today - delta)
startday = i.split(' ')[0]
today = "%s" %today
today = today.split(' ')[0]
在获得开始日期与结束日期后,由于依然需要记录每一天每个人的讨论数,根据这两个日期生成两个字典,分别为actor1_dict与actor2_dict。字典以日期为key,以当日讨论数目作为value,便于每次新增查找记录时更新对应的value值。
strptime, strftime = datetime.datetime.strptime, datetime.datetime.strftime
days = (strptime(today, "%Y-%m-%d") - strptime(startday, "%Y-%m-%d")).days
for i in range(days+1):
temp = strftime(strptime(startday, "%Y-%m-%d") + datetime.timedelta(i), "%Y-%m-%d")
actor1_dict[temp] = 0
actor2_dict[temp] = 0
3.记录从第一页往后翻的所有发帖链接
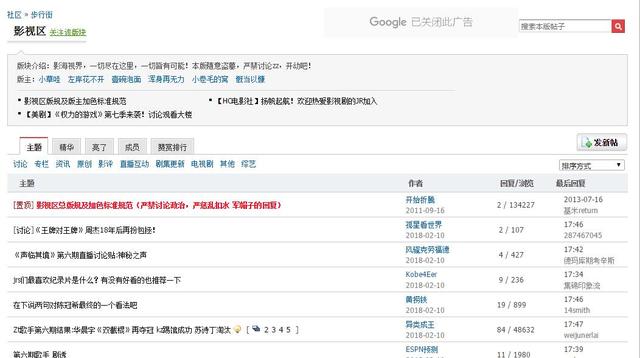

如图1所示,采用发帖顺序排列,可以得到所有的发帖时间(精确到分钟)。右键并点击查看网页源代码,可以发现当前帖子的链接页面,用正则表达式的方式抓取链接。
首先依然是获取30天前的日期,再抓取第i页的源代码,用正则表达式去匹配,获取网页链接和发帖时间。如图2所示:
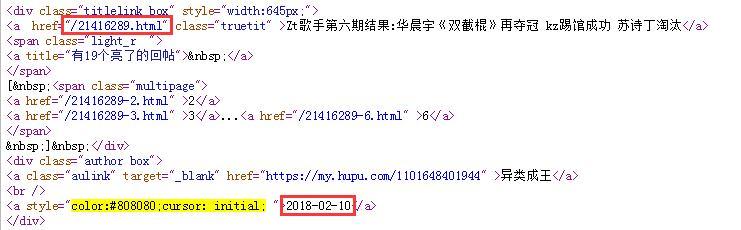
比较发帖时间,如果小于30天前的日期,则获取发帖链接结束,返回当前拿到的链接数组,代码如下
def all_movie_post(ori_url):
i = datetime.datetime.now()
delta = datetime.timedelta(days=30)
i = "%s" %(i - delta)
day = i.split(' ')[0] # 获得30天前的日子
print day
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
post_list = []
for i in range(1,100):
request = urllib2.Request(ori_url + '-{}'.format(i),headers = headers)
response = urllib2.urlopen(request)
content = response.read().decode('utf-8')
pattern = re.compile('<a href="(.*?)" rel="external nofollow" class="truetit" >.*?<a style="color:#808080;cursor: initial; ">(.*?)</a>', re.S)
items = re.findall(pattern,content)
for item in items:
if item[1] == '2011-09-16':
continue
if item[1] > day: #如果是30天内的帖子,保存
post_list.append('https://bbs.hupu.com' + item[0])
else: #如果已经超过30天了,就直接返回
return post_list
return post_list
函数的传参是链接首页,在函数中修改页码,并继续搜索。
从回帖中搜索演员名字:
接下来的步骤也是通过一个函数来解决。函数的传参包括上一步中得到的链接数组,已经想要查询的演员名字(这个功能可以进一步扩展,将演员名字也用列表的形式传输,同时上一步生成的字典也可以多一些)。
由于虎扑论坛会将一些得到认可的回帖摆在前端,即重复出现。如图3所示:
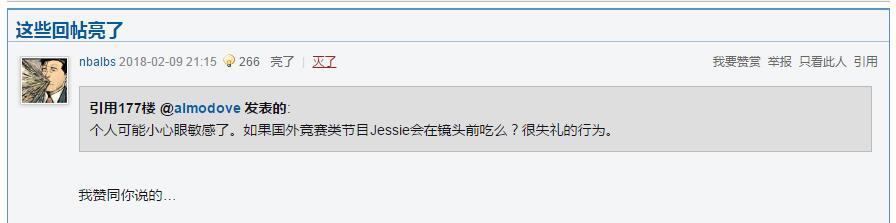
为了避免重复统计,将这些重复先去除,代码如下:
if i == 0:
index = content.find('更多亮了的回帖')
if index >= 0:
content = content[index:]
else:
index = content.find('我要推荐')
content = content[index:]
去除的规则其实并不重要,因为每个论坛都有自己的格式,只要能搞清楚源代码中是怎么写的,剩下的操作就可以自己根据规则进行。
每个回帖格式大致如图4,

用对应的正则表达式再去匹配,找到每个帖子每一个回帖的内容,在内容中搜索演员名字,即一开始的actor_1与actor_2,如果搜到,则在对应回帖日期下+1。
最终将两位演员名字出现频率返回,按日期记录的字典由于是全局变量,不需要返回。
web_str = '<span class="stime">(.*?) .*?</span>.*?<tbody>[\s]*<tr>[\s]*<td>(.*?)<br />' #找到回帖内容的正则
pattern = re.compile(web_str, re.S)
items = re.findall(pattern,content)
for item in items:
#if '<b>引用' in item: #如果引用别人的回帖,则去除引用部分
#try:
#item = item.split('</blockquote>')[1]
#except:
#print item
#print item.decode('utf-8')
if actor_1 in item[1]:
actor1_dict[item[0]] += 1
actor_1_freq += 1
if actor_2 in item[1]:
actor2_dict[item[0]] += 1
actor_2_freq += 1
至此,我们就利用爬虫知识,成功完成对论坛关键字的频率搜索了。
这只是一个例子,关键字可以任意,这也不只是一个针对演员的诞生而写的程序。将演员名字换成其他词,就可以做到类似“您的年度关键字”这样的结果,根据频率大小来显示文字大小。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python爬虫---requests库的用法详解
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多 因为是第三方库,所以使用前需要cmd安装 pip install requests 安装完成后import一下,正常则说明可以开始使用了. 基本用法: requests.get()用于请求目标网站,类型是一个HTTPresponse类型 import requests response = requests.get('http://www.baidu.com')print(response.status_c
-
Python爬取微信小程序通用方法代码实例详解
背景介绍 最近遇到一个需求,大致就是要获取某个小程序上的数据.心想小程序本质上就是移动端加壳的浏览器,所以想到用Python去获取数据.在网上学习了一下如何实现后,记录一下我的实现过程以及所踩过的小坑.本文关键词:Python,小程序,Charles抓包 目标小程序: 公众号"同城商圈网"左下角"找商家"->汽车维修->小车维修->所有的商家信息,如下图所示: 环境 PC端:Windows 10 移动端:iPhone 软件:Charles Char
-
python使用bs4爬取boss直聘静态页面
思路: 1.将需要查询城市列表,通过城市接口转换成相应的code码 2.遍历城市.职位生成url 3.通过url获取列表页面信息,遍历列表页面信息 4.再根据列表页面信息的job_link获取详情页面信息,将需要的信息以字典data的形式存在列表datas里 5.判断列表页面是否有下一页,重复步骤3.4:同时将列表datas一直传递下去 6.一个城市.职位url爬取完后,将列表datas接在列表datas_list后面,重复3.4.5 7.最后将列表datas_list的数据,遍历写在Excel
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
Python爬虫代理池搭建的方法步骤
一.为什么要搭建爬虫代理池 在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制,即在某一时间段内,当某个ip的访问次数达到一定的阀值时,该ip就会被拉黑.在一段时间内禁止访问. 应对的方法有两种: 1. 降低爬虫的爬取频率,避免IP被限制访问,缺点显而易见:会大大降低爬取的效率. 2. 搭建一个IP代理池,使用不同的IP轮流进行爬取. 二.搭建思路 1.从代理网站(如:西刺代理.快代理.云代理.无忧代理)爬取代理IP: 2.验证代理IP的可用性(使用代理IP去请求指定URL,根据响应验证
-
python爬取代理IP并进行有效的IP测试实现
爬取代理IP及测试是否可用 很多人在爬虫时为了防止被封IP,所以就会去各大网站上查找免费的代理IP,由于不是每个IP地址都是有效的,如果要进去一个一个比对的话效率太低了,我也遇到了这种情况,所以就直接尝试了一下去网站爬取免费的代理IP,并且逐一的测试,最后将有效的IP进行返回. 在这里我选择的是89免费代理IP网站进行爬取,并且每一个IP都进行比对测试,最后会将可用的IP进行另存放为一个列表 https://www.89ip.cn/ 一.准备工作 导入包并且设置头标签 import reques
-
Python爬取微信小程序Charles实现过程图解
一.前言 最近需要获取微信小程序上的数据进行分析处理,第一时间想到的方式就是采用python爬虫爬取数据,尝试后发现诸多问题,比如无法获取目标网址.解析网址中存在指定参数的不确定性.加密问题等等,经过一番尝试,终于使用 Charles 抓取到指定微信小程序中的数据,本文进行记录并总结. 环境配置: 电脑:Windows10,连接有线网 手机:iPhone Xr,连接无线网 注:有线网与无线网最好位于同一网段下. 本文有线网网址:192.168.131.24,无线网网址:192.168.210.2
-
python爬取”顶点小说网“《纯阳剑尊》的示例代码
爬取"顶点小说网"<纯阳剑尊> 代码 import requests from bs4 import BeautifulSoup # 反爬 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, \ like Gecko) Chrome/70.0.3538.102 Safari/537.36' } # 获得请求 def open_url(url):
-
Python爬虫抓取论坛关键字过程解析
前言: 之前学习了用python爬虫的基本知识,现在计划用爬虫去做一些实际的数据统计功能.由于前段时间演员的诞生带火了几个年轻的实力派演员,想用爬虫程序搜索某论坛中对于某些演员的讨论热度,并按照日期统计每天的讨论量. 这个项目总共分为两步: 1.获取所有帖子的链接: 将最近一个月内的帖子链接保存到数组中 2.从回帖中搜索演员名字: 从数组中打开链接,翻出该链接的所有回帖,在回帖中查找演员的名字 获取所有帖子的链接: 搜索的范围依然是以虎扑影视区为界限.虎扑影视区一天约5000个回帖,一月下来超过
-

Python爬虫爬取Bilibili弹幕过程解析
先来思考一个问题,B站一个视频的弹幕最多会有多少? 比较多的会有2000条吧,这么多数据,B站肯定是不会直接把弹幕和这个视频绑在一起的. 也就是说,有一个视频地址为https://www.bilibili.com/video/av67946325,你如果直接去requests.get这个地址,里面是不会有弹幕的,回想第一篇说到的携程异步加载数据的方式,B站的弹幕也一定是先加载当前视频的界面,然后再异步填充弹幕的. 接下来我们就可以打开火狐浏览器(平常可以火狐谷歌控制台都使用,因为谷歌里面因为插件
-
python爬虫抓取时常见的小问题总结
目录 01 无法正常显示中文? 解决方法 02 加密问题 03 获取不到网页的全部代码? 04 点击下一页时网页网页不变 05 文本节点问题 06 如何快速找到提取数据? 07 获取标签中的数据 08 去除指定内容 09 转化为字符串类型 10 滥用遍历文档树 11 数据库保存问题 12 爬虫采集遇到的墙问题 逃避IP识别 变换请求内容 降低访问频率 慢速攻击判别 13 验证码问题 正向破解 逆向破解 前言: 现在写爬虫,入门已经不是一件门槛很高的事情了,网上教程一大把,但很多爬虫新手在爬取数据
-
python爬虫爬取网页数据并解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 只要浏览器能够做的事情,原则上,爬虫都能够做到. 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等. 有时,我们比较喜欢的新闻网站可能有几个,每次都要分别
-
Python爬虫抓取代理IP并检验可用性的实例
经常写爬虫,难免会遇到ip被目标网站屏蔽的情况,银次一个ip肯定不够用,作为节约的程序猿,能不花钱就不花钱,那就自己去找吧,这次就写了下抓取 西刺代理上的ip,但是这个网站也反爬!!! 至于如何应对,我觉得可以通过增加延时试试,可能是我抓取的太频繁了,所以被封IP了. 但是,还是可以去IP巴士试试的,条条大路通罗马嘛,不能吊死在一棵树上. 不废话,上代码. #!/usr/bin/env python # -*- coding:utf8 -*- import urllib2 import time
-
python爬虫模拟浏览器访问-User-Agent过程解析
这篇文章主要介绍了python爬虫模拟浏览器访问-User-Agent过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 模拟浏览器访问-User-Agent: import urllib2 #User-Agent 模拟浏览器访问 headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, li
-
Python爬虫抓取技术的一些经验
前言 web是一个开放的平台,这也奠定了web从90年代初诞生直至今日将近30年来蓬勃的发展.然而,正所谓成也萧何败也萧何,开放的特性.搜索引擎以及简单易学的html.css技术使得web成为了互联网领域里最为流行和成熟的信息传播媒介:但如今作为商业化软件,web这个平台上的内容信息的版权却毫无保证,因为相比软件客户端而言,你的网页中的内容可以被很低成本.很低的技术门槛实现出的一些抓取程序获取到,这也就是这一系列文章将要探讨的话题-- 网络爬虫 . 有很多人认为web应当始终遵循开放的精神,呈现
-
编写Python爬虫抓取暴走漫画上gif图片的实例分享
本文要介绍的爬虫是抓取暴走漫画上的GIF趣图,方便离线观看.爬虫用的是python3.3开发的,主要用到了urllib.request和BeautifulSoup模块. urllib模块提供了从万维网中获取数据的高层接口,当我们用urlopen()打开一个URL时,就相当于我们用Python内建的open()打开一个文件.但不同的是,前者接收一个URL作为参数,并且没有办法对打开的文件流进行seek操作(从底层的角度看,因为实际上操作的是socket,所以理所当然地没办法进行seek操作),而后
-
Python爬虫抓取指定网页图片代码实例
想要爬取指定网页中的图片主要需要以下三个步骤: (1)指定网站链接,抓取该网站的源代码(如果使用google浏览器就是按下鼠标右键 -> Inspect-> Elements 中的 html 内容) (2)根据你要抓取的内容设置正则表达式以匹配要抓取的内容 (3)设置循环列表,重复抓取和保存内容 以下介绍了两种方法实现抓取指定网页中图片 (1)方法一:使用正则表达式过滤抓到的 html 内容字符串 # 第一个简单的爬取图片的程序 import urllib.request # python自带
-
Python爬虫抓取手机APP的传输数据
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 .这里以超级课程表APP为例,抓取超级课程表里用户发的话题. 1.抓取APP数据包 方法详细可以参考这篇博文:Fiddler如何抓取手机APP数据包 得到超级课程表登录的地址:http://120.55.151.61/V2/StudentSkip/loginCheckV4.action 表单: 表单中包括了用户名和密码,当然都是加密过了的,还有一个设备信息,直接post过去就是. 另外必须加header,一开始我没有加header得