利用Python+Selenium破解春秋航空网滑块验证码的实战过程
目录
- 前言
- 开发工具
- 环境搭建
- 实战记录
- 一. 验证码简介
- 二.破解滑块验证码
- 2.1 计算滑块到缺口的距离
- 2.2 将滑块拖到缺口位置
前言
记录一次利用Python+Selenium破解滑块验证码的实战过程。
让我们愉快地开始吧~

开发工具
Python版本: 3.6.4
相关模块:
pillow模块;
selenium模块;
numpy模块;
以及一些Python自带的模块。
其他:
chromedriver
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
实战记录
本文将记录一次春秋航空的会员注册页面所使用的滑块验证码破译过程,地址为:
https://account.ch.com/NonRegistrations-Regist
一. 验证码简介
验证码,即CAPTCHA,全自动区分计算机和人类的公开图灵测试,换而言之,验证码是一种用于区分人类与计算机的测试,只有通过了CAPTCHA,当前用户才被认为是人类。
二.破解滑块验证码
滑块验证码,即用户使用鼠标将滑块从某个位置拖动到另一个位置,服务器通过用户拖动滑块的轨迹来判断当前用户是否为人类。本文将尝试破解的是一种拼图式的滑块验证码:
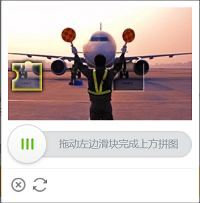
首先,我手动完成了一次滑块验证码的验证,想看看需要向服务器端发送什么请求才算是通过了验证,随便点开了一个,发现请求需要的参数是这样的:

搞清楚每个参数当然是可以的,简单想了一下,感觉应该是这样的:
首先,利用图像处理技术计算滑块到缺口的距离。然后,利用机器以与人类行为相似的方式将滑块拖到缺口位置,完成验证。
2.1 计算滑块到缺口的距离
首先,我们利用Selenium进入滑块验证码界面:

也就是这个界面:

那么滑块到缺口的距离该如何计算呢?
之前看到很多人是这么算的:
出现滑块验证码界面时对屏幕进行截图(此时背景图是完整的),然后模拟点击滑动圆球,使滑块和缺口出现(此时背景图是有缺口的),此时再次截图,通过对比两次截图即可轻松地找到缺口位置。
但是,此方案的前提是在点击滑动圆球之后才出现滑块和缺口,点击之前是完整的背景图。这个方案在不久前还是可行的,但是魔高一尺道高一丈,数天前滑块验证码版本升级了!!!滑块验证码直接显示滑块和缺口了!!!也就是不给你看原图了。
既然准备用机器学习,算法先不考虑,总得先有训练数据吧,于是我手动刷新了几次,想研究一下验证码图片该如何获取,实在不行就手动保存个几百张。可一刷新,发现了一件了不起的事情,这网站滑块验证码的背景图只有四张!
根本不需要爬验证码,手工标注,然后训练了。或许有人会问,为什么呢?
因为就四张背景图啊!!!你完全可以这样:
对当前的滑块验证码界面进行截图,与对应的完整背景图进行对比,找到缺口位置,即可计算出滑块到缺口的距离了(滑块初始位置的横坐标是固定的)。
上述方案有如下两个问题:
(1)如何获取完整的背景图?
答案:当你完成滑块验证码的验证时,还是会出现对应的完整背景图的,通过截屏软件截下图就好了。
结果如下:

(2)怎么找到当前滑块验证码对应的完整背景图?
答案:因为只有四张图,没必要用一些高大上的图像匹配算法,看了下四张图左上角顶点处的像素值,其中R值分别为:255,217,227,100,显然,通过对比背景图左上角顶点处的像素值即可找到当前滑块验证码对应的完整背景图了,代码实现如下:

注意,因为截图是这样子的:
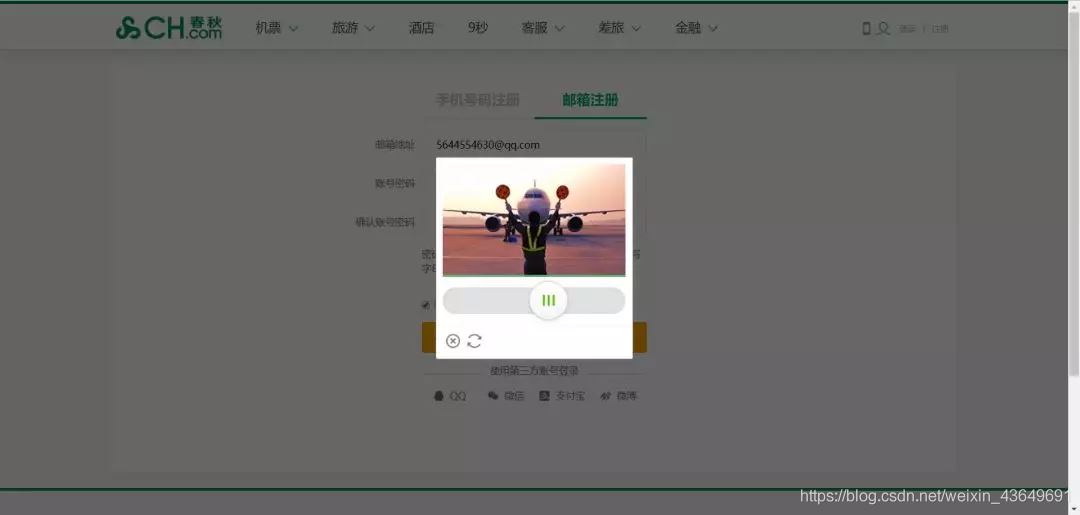
所以验证码背景图左上角顶点处的坐标会随着电脑和截屏方式的改变而改变(具体而言,Selenium和我电脑上的截屏软件截出来的图,验证码背景图的位置坐标是不一样的,需要通过画图软件确定具体位置)。
所以如果你无法用我的代码完成滑块验证码破解的话,请自行修改(787, 282)和(787, 293)为适合你自己电脑实际情况的坐标值。
接下来,我们就可以计算滑块到缺口的距离了!
先截取当前滑块验证码界面,代码实现如下:

这里我们把滑块先移动到最右端再截图,否则滑块将影响当前验证码界面与对应的完整背景图之间的像素对比(即第一次找到的像素差异较大点在滑块上而不是在期望的缺口上)。
然后通过与对应的完整背景图进行像素值对比,找到缺口位置,即可计算出滑块到缺口的距离了(因为滑块初始位置的横坐标是固定的):

2.2 将滑块拖到缺口位置
接下来,我们需要利用机器以与人类行为相似的方式将滑块拖到缺口位置,完成验证。
一般而言,人手工拖动滑块的轨迹是这样的:

即:先快速向右拖动,快到缺口时,再减速慢调。那么这样的轨迹该如何生成呢?
我想了两种方案:
方案一是根据物理学中的加速度减速度来模拟拖动滑块的轨迹,代码实现如下:

方案二是直接构造一些函数来模拟拖动滑块的轨迹,函数代码实现如下:

最后,使用Selenium按照设定的轨迹将滑块移动到缺口处即可:

文章到这里就结束了,感谢你的观看,Python24个小游戏系列,下篇文章分享Python+Selenium破译B站滑块验证码
到此这篇关于利用Python+Selenium破解春秋航空网滑块验证码的实战过程的文章就介绍到这了,更多相关Python Selenium滑块验证码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python Selenium破解滑块验证码最新版(GEETEST95%以上通过率)
一.滑块验证码简述 有爬虫,自然就有反爬虫,就像病毒和杀毒软件一样,有攻就有防,两者彼此推进发展.而目前最流行的反爬技术验证码,为了防止爬虫自动注册,批量生成垃圾账号,几乎所有网站的注册页面都会用到验证码技术.其实验证码的英文为 CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart),翻译成中文就是全自动区分计算机和人类的公开图灵测试,它是一种可以区分用户是计算机还是人的测试,只要能通
-
Python使用selenium实现网页用户名 密码 验证码自动登录功能
好久没有学python了,反正各种理由吧(懒惰总会有千千万万的理由),最近网上学习了一下selenium,实现了一个简单的自动登录网页,具体如下. 1.安装selenium: 如果你已经安装好anaconda3,直接在windows的dos窗口输入命令安装selenium: python -m pip install --upgrade pip 查看版本pip show selenium 2.接着去http://chromedriver.storage.googleapis.com/index.
-
Python + selenium + requests实现12306全自动抢票及验证码破解加自动点击功能
测试结果: 整个买票流程可以再快一点,不过为了稳定起见,有些地方等待了一些时间 完整程序,拿去可用 整个程序分了三个模块:购票模块(主体).验证码识别模块.余票查询模块 购票模块: from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.commo
-
selenium+python实现1688网站验证码图片的截取功能
1. 背景 •在1688网站爬取数据时,如果访问过于频繁,无论用户是否已经登录,就会弹出如下所示的验证码登录框. 一般的验证码是类似于如下的元素(通过链接单独加载进页面,而不是嵌入图片元素): <img id="J_CheckCodeImg1" width="100" height="30" onmousedown="return false;" src="//pin.aliyun.com/get_img?id
-
Selenium+Python 自动化操控登录界面实例(有简单验证码图片校验)
从最简单的Web浏览器的登录界面开始,登录界面如下: 进行Web页面自动化测试,对页面上的元素进行定位和操作是核心.而操作又是以定位为前提的,因此,对页面元素的定位是进行自动化测试的基础. 页面上的元素就像人一样,有各种属性,比如元素名字,元素id,元素属性(class属性,name属性)等等.webdriver就是利用元素的这些属性来进行定位的. 可以用于定位的常用的元素属性: id name class name tag name link text partial link text xp
-
Python Selenium Cookie 绕过验证码实现登录示例代码
之前介绍过通过cookie 绕过验证码实现登录的方法.这里并不多余,会增加分析和另外一种方法实现登录. 1.思路介绍 1.1.直接看代码,内有详细注释说明 # FileName : Wm_Cookie_Login.py # Author : Adil # DateTime : 2018/3/20 19:47 # SoftWare : PyCharm from selenium import webdriver import time url = 'https://system.address'
-
python selenium UI自动化解决验证码的4种方法
本文介绍了python selenium UI自动化解决验证码的4种方法,分享给大家,具体如下: 测试环境 windows7+ firefox50+ geckodriver # firefox浏览器驱动 python3 selenium3 selenium UI自动化解决验证码的4种方法:去掉验证码.设置万能码.验证码识别技术-tesseract.添加cookie登录,本次主要讲解验证码识别技术-tesseract和添加cookie登录. 1. 去掉验证码 去掉验证码,直接通过用户名和密码登陆网
-
Python +Selenium解决图片验证码登录或注册问题(推荐)
1. 解决思路 首先要获得这张验证码的图片,但是该图片一般都是用的js写的,不能够通过url进行下载. 解决方案:截图然后根据该图片的定位和长高,使用工具进行裁剪 裁剪完毕之后,使用工具解析该图片. 2. 代码实现 2.1 裁剪出验证码图片 裁剪图片需要使用 Pillow 库,进入pip包路径后输入安装命令pip install Pillow: 之前安装的时候忘记了截图,只能够截一张安装后的图片了 ╰(:з╰∠)_ 安装完成后,代码实现方式如下: #coding=utf-8 from selen
-
利用Python+Selenium破解春秋航空网滑块验证码的实战过程
目录 前言 开发工具 环境搭建 实战记录 一. 验证码简介 二.破解滑块验证码 2.1 计算滑块到缺口的距离 2.2 将滑块拖到缺口位置 前言 记录一次利用Python+Selenium破解滑块验证码的实战过程. 让我们愉快地开始吧~ 开发工具 Python版本: 3.6.4 相关模块: pillow模块: selenium模块: numpy模块: 以及一些Python自带的模块. 其他: chromedriver 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 实战
-
Python+selenium破解拼图验证码的脚本
目录 实现思路 核心代码 实现思路 很多网站都有拼图验证码 1.首先要了解拼图验证码的生成原理 2.制定破解计划,考虑其可能性和成功率. 3.编写脚本 很多网站的拼图验证码都是直接借助第三方插件,也就是一类一种解法. 笔者遇到的这种拼图验证码实际上是多个小碎片经过重新组合成的一张整体,首先要在网站上抓取这种小碎片图片并下载到本地 我们先捋一捋大体思路: 获取所有碎片图片----找出他们的排列顺序逻辑-----找出他们中含有颜色深的真正位置的那个小碎块的序号-----根据每块碎片的宽度和上下和这个
-
详解python selenium 爬取网易云音乐歌单名
目标网站: 首先获取第一页的数据,这里关键要切换到iframe里 打印一下 获取剩下的页数,这里在点击下一页之前需要设置一个延迟,不然会报错. 结果: 一共37页,爬取完毕后关闭浏览器 完整代码: url = 'https://music.163.com/#/discover/playlist/' from selenium import webdriver import time # 创建浏览器对象 window = webdriver.Chrome('./chromedriver') win
-
利用python Selenium实现自动登陆京东签到领金币功能
如何自动登陆京东? 我们先来看一下京东的登陆页面,如下图所示: [插入图片,登陆页面] 登陆框就是右面这一个框框了,但是目前我们遇到一个困呐,默认的登陆方式是扫码登陆,如果我们想要以用户民个.密码的形式登陆,就要切换一下. 我们看一下这两种登陆方式是如何切换的,通过浏览器的元素检查,我们看一下两个标签. [插入图片,两种登陆方式] 扫码登陆和用户登陆分别在一个div标签里面,我们可以通过css选择器选定用户登陆,使其下面的a标签的class为checked,接下来的一切就比较简单了. 我们要获取
-
Python+Selenium实现读取网易邮箱验证码
前面写到了一些关于python+Selenium的基础操作 的教程,这篇文章将讲解一些实战内容. 在自动化工作中,有可能会遇到一些发送邮箱验证码类似的功能,如下 我们一般的解决思路就是 : 发送邮件—>打开邮箱—>输入邮箱账户密码—>登录邮箱—>打开未读邮件—>获取验证码—>保存验证码—>读取验证码 以下是一个实现打开网易邮箱读取未读邮件获取验证码的代码 def wangyi(self,username, password, name): dr = webdriv
-
利用python爬取散文网的文章实例教程
本文主要给大家介绍的是关于python爬取散文网文章的相关内容,分享出来供大家参考学习,下面一起来看看详细的介绍: 效果图如下: 配置python 2.7 bs4 requests 安装 用pip进行安装 sudo pip install bs4 sudo pip install requests 简要说明一下bs4的使用因为是爬取网页 所以就介绍find 跟find_all find跟find_all的不同在于返回的东西不同 find返回的是匹配到的第一个标签及标签里的内容 find_all返
-
利用Python将图片批量转化成素描图的过程记录
目录 前言 程序 Method 1 Method 2 完整代码 结果 总结 前言 正常图片转化成素描图片无非对图片像素的处理,矩阵变化而已.目前很多拍照修图App都有这一功能,核心代码不超30行.如下利用 Python 实现读取一张图片并将其转化成素描图片.至于批处理也简单,循环读取文件夹里的图片处理即可.具体代码可以去我的 GitHub下载. 程序 Method 1 def plot_sketch(origin_picture, out_picture) : a = np.asarray(Im
-
Python+selenium 自动化快手短视频发布的实现过程
第一章:效果展示 ① 效果展示 ② 素材展示 一个为视频,另一个为像素大小不小于视频的封面. 第二章:实现过程 ① 调用已启用的浏览器 通过调用已启用的浏览器,可以实现直接跳过每次的登录过程. from selenium import webdriver options = webdriver.ChromeOptions() options.add_experimental_option("debuggerAddress", "127.0.0.1:5003") dr
-
利用Python暴力破解zip文件口令的方法详解
前言 通过Python内置的zipfile模块实现对zip文件的解压,加点料完成口令破解 zipfile模块用来做zip格式编码的压缩和解压缩的,zipfile里有两个非常重要的class, 分别是ZipFile和ZipInfo, 在绝大多数的情况下,我们只需要使用这两个class就可以了.ZipFile是主要的类,用来创建和读取zip文件而ZipInfo是存储的zip文件的每个文件的信息的. 比如要读取一个Python zipfile 模块,这里假设filename是一个文件的路径: impo