python+opencv实现车牌定位功能(实例代码)
写在前面
HIT大三上学期视听觉信号处理课程中视觉部分的实验三,经过和学长们实验的对比发现每一级实验要求都不一样,因此这里标明了是2019年秋季学期的视觉实验三。
由于时间紧张,代码没有进行任何优化,实验算法仅供参考。
实验要求
对给定的车牌进行车牌识别
实验代码
代码首先贴在这里,仅供参考
源代码
实验代码如下:
import cv2
import numpy as np
def lpr(filename):
img = cv2.imread(filename)
# 预处理,包括灰度处理,高斯滤波平滑处理,Sobel提取边界,图像二值化
# 对于高斯滤波函数的参数设置,第四个参数设为零,表示不计算y方向的梯度,原因是车牌上的数字在竖方向较长,重点在于得到竖方向的边界
# 对于二值化函数的参数设置,第二个参数设为127,是二值化的阈值,是一个经验值
gray_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
GaussianBlur_img = cv2.GaussianBlur(gray_img, (3, 3), 0)
Sobel_img = cv2.Sobel(GaussianBlur_img, -1, 1, 0, ksize=3)
ret, binary_img = cv2.threshold(Sobel_img, 127, 255, cv2.THRESH_BINARY)
# 形态学运算
kernel = np.ones((5, 15), np.uint8)
# 先闭运算将车牌数字部分连接,再开运算将不是块状的或是较小的部分去掉
close_img = cv2.morphologyEx(binary_img, cv2.MORPH_CLOSE, kernel)
open_img = cv2.morphologyEx(close_img, cv2.MORPH_OPEN, kernel)
# kernel2 = np.ones((10, 10), np.uint8)
# open_img2 = cv2.morphologyEx(open_img, cv2.MORPH_OPEN, kernel2)
# 由于部分图像得到的轮廓边缘不整齐,因此再进行一次膨胀操作
element = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
dilation_img = cv2.dilate(open_img, element, iterations=3)
# 获取轮廓
contours, hierarchy = cv2.findContours(dilation_img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 测试边框识别结果
# cv2.drawContours(img, contours, -1, (0, 0, 255), 3)
# cv2.imshow("lpr", img)
# cv2.waitKey(0)
# 将轮廓规整为长方形
rectangles = []
for c in contours:
x = []
y = []
for point in c:
y.append(point[0][0])
x.append(point[0][1])
r = [min(y), min(x), max(y), max(x)]
rectangles.append(r)
# 用颜色识别出车牌区域
# 需要注意的是这里设置颜色识别下限low时,可根据识别结果自行调整
dist_r = []
max_mean = 0
for r in rectangles:
block = img[r[1]:r[3], r[0]:r[2]]
hsv = cv2.cvtColor(block, cv2.COLOR_BGR2HSV)
low = np.array([100, 60, 60])
up = np.array([140, 255, 255])
result = cv2.inRange(hsv, low, up)
# 用计算均值的方式找蓝色最多的区块
mean = cv2.mean(result)
if mean[0] > max_mean:
max_mean = mean[0]
dist_r = r
# 画出识别结果,由于之前多做了一次膨胀操作,导致矩形框稍大了一些,因此这里对于框架+3-3可以使框架更贴合车牌
cv2.rectangle(img, (dist_r[0]+3, dist_r[1]), (dist_r[2]-3, dist_r[3]), (0, 255, 0), 2)
cv2.imshow("lpr", img)
cv2.waitKey(0)
# 主程序
for i in range(5):
lpr(str(i+1) + ".jpg")
参数调整
上述代码中,所有涉及到参数调整的函数,例如形态学操作,都需边调整边观察当前参数下的运行结果,待本步运行结果较好时,再继续写下一步。
该代码对具体图片要求较高,不同的图片可能无法成功识别车牌,此时可尝试依次调整预处理部分,形态学部分,hsv检测部分函数的参数
实验结果




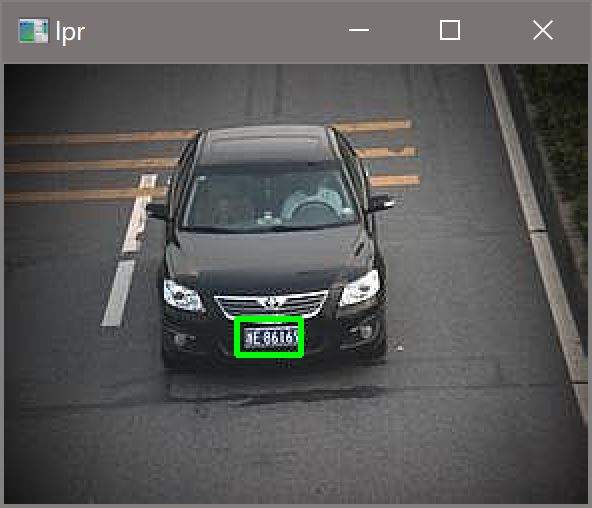
ps:图五是最难识别的图片,最后是通过调整hsv下限为[100, 60, 60]实现的
总结
以上所述是小编给大家介绍的python+opencv实现车牌定位功能,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
Python 实现字符串中指定位置插入一个字符
如下所示: str_1='wo shi yi zhi da da niu/n'str_list=list(str_1) nPos=str_list.index('/') str_list.insert(nPos,',') str_2="".join(str_list) print(str_2) 从文件中提取行,在行最末尾插入一个逗号. 以上这篇Python 实现字符串中指定位置插入一个字符就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章
-
python opencv将图片转为灰度图的方法示例
使用opencv将图片转为灰度图主要有两种方法,第一种是将彩色图转为灰度图,第二种是在使用OpenCV读取图片的时候直接读取为灰度图. 将彩色图转为灰度图 import cv2 import numpy as np if __name__ == "__main__": img_path = "timg.jpg" img = cv2.imread(img_path) #获取图片的宽和高 width,height = img.shape[:2][::-1] #将图片缩小
-
python使用正则表达式的search()函数实现指定位置搜索功能
前面学习过search()可以从任意一个文本里搜索匹配的字符串,也就是说可以从任何位置里搜索到匹配的字符串.但是现实世界很复杂多变的,比如限定你只能从第100个字符的位置开始匹配,100个字符之前的不要匹配,这样的需求怎么样实现呢?来看下面的例子,它就是指定位置开始搜索: #python 3.6 #蔡军生 #http://blog.csdn.net/caimouse/article/details/51749579 # import re text = 'This is some text --
-

Python基于Opencv来快速实现人脸识别过程详解(完整版)
前言 随着人工智能的日益火热,计算机视觉领域发展迅速,尤其在人脸识别或物体检测方向更为广泛,今天就为大家带来最基础的人脸识别基础,从一个个函数开始走进这个奥妙的世界. 首先看一下本实验需要的数据集,为了简便我们只进行两个人的识别,选取了beyond乐队的主唱黄家驹和贝斯手黄家强,这哥俩长得有几分神似,这也是对人脸识别的一个考验: 两个文件夹,一个为训练数据集,一个为测试数据集,训练数据集中有两个文件夹0和1,之前看一些资料有说这里要遵循"slabel"命名规则,但后面处理起来比较麻烦,
-
python numpy和list查询其中某个数的个数及定位方法
1. list 查询个数: 调用list.count(obj)函数,返回obj在list中的个数. 输入: list_a = [2 for x in range(5)] print(list_a) a_count = list_a.count(2) print(a_count) 输出: [2, 2, 2, 2, 2] 定位元素: 调用list.index(obj)函数,返回待查找对象第一个匹配项的位置. 输入: #!/usr/bin/python aList = [123, 'xyz', 'za
-
使用Python opencv实现视频与图片的相互转换
因为最近要经常转换数据集进行实验,因此记录一下. 1.视频转图片 即为将视频解析为一帧一帧的图片: import cv2 vc=cv2.VideoCapture("/home/hqd/PycharmProjects/1/1/19.MOV") c=1 if vc.isOpened(): rval,frame=vc.read() else: rval=False while rval: rval,frame=vc.read() cv2.imwrite('/home/hqd/PycharmP
-
使用Python向DataFrame中指定位置添加一列或多列的方法
对于这个问题,相信很多人都会很困惑,本篇文章将会给大家介绍一种非常简单的方式向DataFrame中任意指定的位置添加一列. 在此之前或许有不少读者已经了解了最普通的添加一列的方式,如下: import pandas as pd feature = pd.read_csv("C://Users//Machenike//Desktop//xzw//lr_train_data.txt", delimiter="\t", header=None, usecols=[0, 1
-
python-opencv获取二值图像轮廓及中心点坐标的代码
python-opencv获取二值图像轮廓及中心点坐标代码: groundtruth = cv2.imread(groundtruth_path)[:, :, 0] h1, w1 = groundtruth.shape contours, cnt = cv2.findContours(groundtruth.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) if len(contours) != 1:#轮廓总数 continue M = cv
-
python+opencv实现车牌定位功能(实例代码)
写在前面 HIT大三上学期视听觉信号处理课程中视觉部分的实验三,经过和学长们实验的对比发现每一级实验要求都不一样,因此这里标明了是2019年秋季学期的视觉实验三. 由于时间紧张,代码没有进行任何优化,实验算法仅供参考. 实验要求 对给定的车牌进行车牌识别 实验代码 代码首先贴在这里,仅供参考 源代码 实验代码如下: import cv2 import numpy as np def lpr(filename): img = cv2.imread(filename) # 预处理,包括灰度处理,高斯
-
python实现ssh及sftp功能(实例代码)
1.在Linux上我们通过scp命令实现主机间的文件传送,通过ssh实现远程登录 ,比如 我们经常使用的xshell远程登录工具,就是基础ssh协议实现window主机远程登录Linux主机 下面简单的在python实现这几个功能 下面使用到paramiko模块,这个不是python的内置模块,我直接通过pycharm下载这个模块, 第一步实现一个简单的ssh登录命令 代码如下: import paramiko # 创建SSH对象 ssh = paramiko.SSHClient() # 允
-
python django 实现验证码的功能实例代码
我也是刚学Python Django不久很多都不懂,所以我现在想一边学习一边记录下来然后大家一起讨论! 验证码功能一开始我在网上找了很多的demo但是我在模仿他们写的时候,发现在我的版本上根本就不能运行起来在前端页面显示的时候是图裂,有可能是我用的Python3.5的版本和django是1.10的版本的原因,我看了晚上很多的版本都是2.7的,所以我问了很多前辈和大神,终于发现了原因的所在,好了代码我就在下面帖粗来了. 这是我的项目目录. 验证码要成功显示就必须要有一个验证码生成器,所以就要写一
-
python+selenium实现自动抢票功能实例代码
简介 什么是Selenium? Selenium是ThoughtWorks公司的一个强大的开源Web功能测试工具系列,采用Javascript来管理整个测试过程,包括读入测试套件.执行测试和记录测试结果.它采用Javascript单元测试工具JSUnit为核心,模拟真实用户操作,包括浏览页面.点击链接.输入文字.提交表单.触发鼠标事件等等,并且能够对页面结果进行种种验证.也就是说,只要在测试用例中把预期的用户行为与结果都描述出来,我们就得到了一个可以自动化运行的功能测试套件.(Selenium的
-
用python做一个搜索引擎(Pylucene)的实例代码
1.什么是搜索引擎? 搜索引擎是"对网络信息资源进行搜集整理并提供信息查询服务的系统,包括信息搜集.信息整理和用户查询三部分".如图1是搜索引擎的一般结构,信息搜集模块从网络采集信息到网络信息库之中(一般使用爬虫):然后信息整理模块对采集的信息进行分词.去停用词.赋权重等操作后建立索引表(一般是倒排索引)构成索引库:最后用户查询模块就可以识别用户的检索需求并提供检索服务啦. 图1 搜索引擎的一般结构 2. 使用python实现一个简单搜索引擎 2.1 问题分析 从图1看,一个完整的搜索
-
Android 百度地图POI搜索功能实例代码
在没介绍正文之前先给大家说下poi是什么意思. 由于工作的关系,经常在文件中会看到POI这三个字母的缩写,但是一直对POI的概念和含义没有很详细的去研究其背后代表的意思.今天下班之前,又看到了POI这三个字母,决定认认真真的搜索一些POI具体的含义. POI是英文的缩写,原来的单词是point of interest, 直译成中文就是兴趣点的意思.兴趣点这个词最早来自于导航地图厂商.地图厂商为了提供尽可能多的位置信息,花费了很大的精力去寻找诸如加油站,餐馆,酒店,景点等目的地,这些目的地其实都可
-
python+matplotlib实现动态绘制图片实例代码(交互式绘图)
本文研究的主要是python+matplotlib实现动态绘制图片(交互式绘图)的相关内容,具体介绍和实现代码如下所示. 最近在研究动态障碍物避障算法,在Python语言进行算法仿真时需要实时显示障碍物和运动物的当前位置和轨迹,利用Anaconda的Python打包集合,在Spyder中使用Python3.5语言和matplotlib实现路径的动态显示和交互式绘图(和Matlab功能类似). Anaconda是一个用于科学计算的Python发行版,支持 Linux, Mac, Windows系统
-
Python实现Pig Latin小游戏实例代码
前言: 本文研究的主要是Python实现pig Latin小游戏的简单代码,具体介绍如下. Pig Latin是一个语言游戏. 步骤: 1.让用户输入一个英文单词 2.确保用户输入一个有效单词 3.将单词转换成Pig Latin 4.显示转换结果 一.Input 函数:raw_input()用于输出一个字符串并等待键盘输入某字符串,最后以Enter(或Return)结束输入 original = raw_input("Enter a word:") print original 上述中
-
Python使用requests发送POST请求实例代码
本文研究的主要是Python使用requests发送POST请求的相关内容,具体介绍如下. 一个http请求包括三个部分,为别为请求行,请求报头,消息主体,类似以下这样: 请求行 请求报头 消息主体 HTTP协议规定post提交的数据必须放在消息主体中,但是协议并没有规定必须使用什么编码方式.服务端通过是根据请求头中的Content-Type字段来获知请求中的消息主体是用何种方式进行编码,再对消息主体进行解析.具体的编码方式包括: application/x-www-form-urlencode
-
Python编程scoketServer实现多线程同步实例代码
本文研究的主要是Python编程scoketServer实现多线程同步的相关内容,具体介绍如下. 开发过程中,为了实现不同的客户端同一时刻只能有一个使用共同数据. 虽说用Python编写简单的网络程序很方便,但复杂一点的网络程序还是用现成的框架比较好.这样就可以专心事务逻辑,而不是套接字的各种细节.SocketServer模块简化了编写网络服务程序的任务.同时SocketServer模块也是Python标准库中很多服务器框架的基础. 网络服务类: SocketServer提供了4个基本的服务类: