python数据预处理方式 :数据降维
数据为何要降维
数据降维可以降低模型的计算量并减少模型运行时间、降低噪音变量信息对于模型结果的影响、便于通过可视化方式展示归约后的维度信息并减少数据存储空间。因此,大多数情况下,当我们面临高维数据时,都需要对数据做降维处理。
数据降维有两种方式:特征选择,维度转换
特征选择
特征选择指根据一定的规则和经验,直接在原有的维度中挑选一部分参与到计算和建模过程,用选择的特征代替所有特征,不改变原有特征,也不产生新的特征值。
特征选择的降维方式好处是可以保留原有维度特征的基础上进行降维,既能满足后续数据处理和建模需求,又能保留维度原本的业务含义,以便于业务理解和应用。对于业务分析性的应用而言,模型的可理解性和可用性很多时候要有限于模型本身的准确率、效率等技术指标。例如,决策树得到的特征规则,可以作为选择用户样本的基础条件,而这些特征规则便是基于输入的维度产生。
维度转换
这个是按照一定数学变换方法,把给定的一组相关变量(维度)通过数学模型将高纬度空间的数据点映射到低纬度空间中,然后利用映射后变量的特征来表示原有变量的总体特征。这种方式是一种产生新维度的过程,转换后的维度并非原来特征,而是之前特征的转化后的表达式,新的特征丢失了原有数据的业务含义。 通过数据维度变换的降维方法是非常重要的降维方法,这种降维方法分为线性降维和非线性降维两种,其中常用的代表算法包括独立成分分析(ICA),主成分分析(PCA),因子分析(Factor Analysis,FA),线性判别分析(LDA),局部线性嵌入(LLE),核主成分分析(Kernel PCA)等。
使用python做降维处理
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.decomposition import PCA
# 数据导入
df = pd.read_csv('https://raw.githubusercontent.com/ffzs/dataset/master/glass.csv')
# 看一下数据是
df.head()
RI Na Mg Al Si K Ca Ba Fe Type
0 1.52101 13.64 4.49 1.10 71.78 0.06 8.75 0.0 0.0 1
1 1.51761 13.89 3.60 1.36 72.73 0.48 7.83 0.0 0.0 1
2 1.51618 13.53 3.55 1.54 72.99 0.39 7.78 0.0 0.0 1
3 1.51766 13.21 3.69 1.29 72.61 0.57 8.22 0.0 0.0 1
4 1.51742 13.27 3.62 1.24 73.08 0.55 8.07 0.0 0.0 1
# 有无缺失值
df.isna().values.any()
# False 没有缺失值
# 获取特征值
X = df.iloc[:, :-1].values
# 获取标签值
Y = df.iloc[:,[-1]].values
# 使用sklearn 的DecisionTreeClassifier判断变量重要性
# 建立分类决策树模型对象
dt_model = DecisionTreeClassifier(random_state=1)
# 将数据集的维度和目标变量输入模型
dt_model.fit(X, Y)
# 获取所有变量的重要性
feature_importance = dt_model.feature_importances_
feature_importance
# 结果如下
# array([0.20462132, 0.06426227, 0.16799114, 0.15372793, 0.07410088, 0.02786222, 0.09301948, 0.16519298, 0.04922178])
# 做可视化
import matplotlib.pyplot as plt
x = range(len(df.columns[:-1]))
plt.bar(left= x, height=feature_importance)
plt.xticks(x, df.columns[:-1])
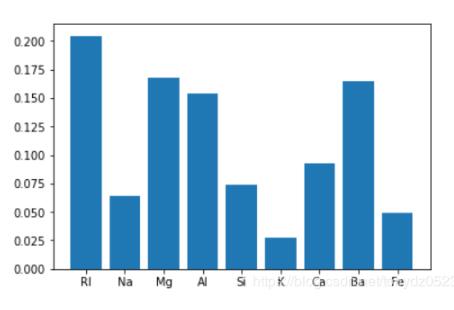
可见Rl、Mg、Al、Ba的重要性比较高,一般情况下变量重要性得分接近80%,基本上已经可以解释大部分的特征变化。
PCA降维
# 使用sklearn的PCA进行维度转换 # 建立PCA模型对象 n_components控制输出特征个数 pca_model = PCA(n_components=3) # 将数据集输入模型 pca_model.fit(X) # 对数据集进行转换映射 pca_model.transform(X) # 获得转换后的所有主成分 components = pca_model.components_ # 获得各主成分的方差 components_var = pca_model.explained_variance_ # 获取主成分的方差占比 components_var_ratio = pca_model.explained_variance_ratio_ # 打印方差 print(np.round(components_var,3)) # [3.002 1.659 0.68 ] # 打印方差占比 print(np.round(components_var_ratio,3)) # [0.476 0.263 0.108]
以上这篇python数据预处理方式 :数据降维就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python实现拉普拉斯特征图降维示例
这种方法假设样本点在光滑的流形上,这一方法的计算数据的低维表达,局部近邻信息被最优的保存.以这种方式,可以得到一个能反映流形的几何结构的解. 步骤一:构建一个图G=(V,E),其中V={vi,i=1,2,3-n}是顶点的集合,E={eij}是连接顶点的vi和vj边,图的每一个节点vi与样本集X中的一个点xi相关.如果xi,xj相距较近,我们就连接vi,vj.也就是说在各自节点插入一个边eij,如果Xj在xi的k领域中,k是定义参数. 步骤二:每个边都与一个权值Wij相对应,没有连接点之间的权值为
-
python 列表降维的实例讲解
列表降维(python:3.x) 之前遇到需要使用列表降维的情况, 如: 原列表 : [[12,34],[57,86,1],[43,22,7],[1,[2,3]],6] 转化为 : [12, 34, 57, 86, 1, 43, 22, 7, 1, 2, 3, 6] 思路: 把列表转化为字符串,直接去掉 "[" 和 "]" 最后由字符串转化为列表 a = [[12,34],[57,86,1],[43,22,7],[1,[2,3]],6] #把列表转为字符串 b =
-
python实现PCA降维的示例详解
概述 本文主要介绍一种降维方法,PCA(Principal Component Analysis,主成分分析).降维致力于解决三类问题. 1. 降维可以缓解维度灾难问题: 2. 降维可以在压缩数据的同时让信息损失最小化: 3. 理解几百个维度的数据结构很困难,两三个维度的数据通过可视化更容易理解. PCA简介 在理解特征提取与处理时,涉及高维特征向量的问题往往容易陷入维度灾难.随着数据集维度的增加,算法学习需要的样本数量呈指数级增加.有些应用中,遇到这样的大数据是非常不利的,而且从大数据集中学习
-

python数据预处理方式 :数据降维
数据为何要降维 数据降维可以降低模型的计算量并减少模型运行时间.降低噪音变量信息对于模型结果的影响.便于通过可视化方式展示归约后的维度信息并减少数据存储空间.因此,大多数情况下,当我们面临高维数据时,都需要对数据做降维处理. 数据降维有两种方式:特征选择,维度转换 特征选择 特征选择指根据一定的规则和经验,直接在原有的维度中挑选一部分参与到计算和建模过程,用选择的特征代替所有特征,不改变原有特征,也不产生新的特征值. 特征选择的降维方式好处是可以保留原有维度特征的基础上进行降维,既能满足后续数据
-
Python数据预处理之数据规范化(归一化)示例
本文实例讲述了Python数据预处理之数据规范化.分享给大家供大家参考,具体如下: 数据规范化 为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化(归一化)处理,将数据按照比例进行缩放,使之落入一个特定的区域,便于进行综合分析. 数据规范化方法主要有: - 最小-最大规范化 - 零-均值规范化 数据示例 代码实现 #-*- coding: utf-8 -*- #数据规范化 import pandas as pd import numpy as np datafile = 'normali
-
Pytorch 数据加载与数据预处理方式
数据加载分为加载torchvision.datasets中的数据集以及加载自己使用的数据集两种情况. torchvision.datasets中的数据集 torchvision.datasets中自带MNIST,Imagenet-12,CIFAR等数据集,所有的数据集都是torch.utils.data.Dataset的子类,都包含 _ _ len _ (获取数据集长度)和 _ getItem _ _ (获取数据集中每一项)两个子方法. Dataset源码如上,可以看到其中包含了两个没有实现的子
-
python数据预处理之数据标准化的几种处理方式
何为标准化: 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析.数据标准化也就是统计数据的指数化.数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面.数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果.数据无量纲化处理主要解决数据的可比性. 几种标准化方法: 归一化Max-Min min-max标准化方
-
Python机器学习入门(三)数据准备
目录 1.数据预处理 1.1调整数据尺度 1.2正态化数据 1.3标准化数据 1.4二值数据 2.数据特征选定 2.1单变量特征选定 2.2递归特征消除 2.3数据降维 2.4特征重要性 总结 特征选择时困难耗时的,也需要对需求的理解和专业知识的掌握.在机器学习的应用开发中,最基础的是特征工程. --吴恩达 1.数据预处理 数据预处理需要根据数据本身的特性进行,有缺失的要填补,有无效的要剔除,有冗余维的要删除,这些步骤都和数据本身的特性紧密相关. 1.1调整数据尺度 如果数据的各个属性按照不同的
-
python数据预处理之将类别数据转换为数值的方法
在进行python数据分析的时候,首先要进行数据预处理. 有时候不得不处理一些非数值类别的数据,嗯, 今天要说的就是面对这些数据该如何处理. 目前了解到的大概有三种方法: 1,通过LabelEncoder来进行快速的转换: 2,通过mapping方式,将类别映射为数值.不过这种方法适用范围有限: 3,通过get_dummies方法来转换. import pandas as pd from io import StringIO csv_data = '''A,B,C,D 1,2,3,4 5,6,,
-
python数据预处理 :样本分布不均的解决(过采样和欠采样)
何为样本分布不均: 样本分布不均衡就是指样本差异非常大,例如共1000条数据样本的数据集中,其中占有10条样本分类,其特征无论如何你和也无法实现完整特征值的覆盖,此时属于严重的样本分布不均衡. 为何要解决样本分布不均: 样本分部不均衡的数据集也是很常见的:比如恶意刷单.黄牛订单.信用卡欺诈.电力窃电.设备故障.大企业客户流失等. 样本不均衡将导致样本量少的分类所包含的特征过少,很难从中提取规律,即使得到分类模型,也容易产生过度依赖于有限的数量样本而导致过拟合问题,当模型应用到新的数据上时,模型的
-
使用Python制作一个数据预处理小工具(多种操作一键完成)
在我们平常使用Python进行数据处理与分析时,在import完一大堆库之后,就是对数据进行预览,查看数据是否出现了缺失值.重复值等异常情况,并进行处理. 本文将结合GUI工具PySimpleGUI,来讲解如何制作一款属于自己的数据预处理小工具,让这个过程也能够自动化!最终效果如下 本文将分为三部分讲解: 制作GUI界面 数据处理讲解 打包与测试 主要涉及将涉及以下模块: PySimpleGUI pandas matplotlib 一.GUI界面制作 思路 老规矩,先讲思路再上代码,首先还是说一
-
python机器学习算法与数据降维分析详解
目录 一.数据降维 1.特征选择 2.主成分分析(PCA) 3.降维方法使用流程 二.机器学习开发流程 1.机器学习算法分类 2.机器学习开发流程 三.转换器与估计器 1.转换器 2.估计器 一.数据降维 机器学习中的维度就是特征的数量,降维即减少特征数量.降维方式有:特征选择.主成分分析. 1.特征选择 当出现以下情况时,可选择该方式降维: ①冗余:部分特征的相关度高,容易消耗计算性能 ②噪声:部分特征对预测结果有影响 特征选择主要方法:过滤式(VarianceThreshold).嵌入式(正
-
python优化数据预处理方法Pandas pipe详解
我们知道现实中的数据通常是杂乱无章的,需要大量的预处理才能使用.Pandas 是应用最广泛的数据分析和处理库之一,它提供了多种对原始数据进行预处理的方法. import numpy as np import pandas as pd df = pd.DataFrame({ "id": [100, 100, 101, 102, 103, 104, 105, 106], "A": [1, 2, 3, 4, 5, 2, np.nan, 5], "B":