pandas数据的合并与拼接的实现
目录
- 1. Merge方法
- 1.1 内连接
- 1.2 外连接
- 1.3 左连接
- 1.4 右连接
- 1.5 基于多列的连接算法
- 1.6 基于index的连接方法
- 2. join方法
- 3. concat方法
- 3.1 series类型的拼接方法
- 3.2 dataframe类型的拼接方法
- 4. 小结
Pandas包的merge、join、concat方法可以完成数据的合并和拼接,merge方法主要基于两个dataframe的共同列进行合并,join方法主要基于两个dataframe的索引进行合并,concat方法是对series或dataframe进行行拼接或列拼接。
1. Merge方法
pandas的merge方法是基于共同列,将两个dataframe连接起来。merge方法的主要参数:
- left/right:左/右位置的dataframe。
- how:数据合并的方式。left:基于左dataframe列的数据合并;right:基于右dataframe列的数据合并;outer:基于列的数据外合并(取并集);inner:基于列的数据内合并(取交集);默认为'inner'。
- on:用来合并的列名,这个参数需要保证两个dataframe有相同的列名。
- left_on/right_on:左/右dataframe合并的列名,也可为索引,数组和列表。
- left_index/right_index:是否以index作为数据合并的列名,True表示是。
- sort:根据dataframe合并的keys排序,默认是。
- suffixes:若有相同列且该列没有作为合并的列,可通过suffixes设置该列的后缀名,一般为元组和列表类型。
merges通过设置how参数选择两个dataframe的连接方式,有内连接,外连接,左连接,右连接,下面通过例子介绍连接的含义。
1.1 内连接
how='inner',dataframe的链接方式为内连接,我们可以理解基于共同列的交集进行连接,参数on设置连接的共有列名。
# 单列的内连接
# 定义df1
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# print(df1)
# print(df2)
# 基于共同列alpha的内连接
df3 = pd.merge(df1,df2,how='inner',on='alpha')
df3
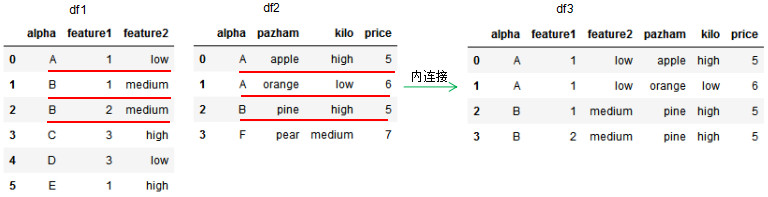
取共同列alpha值的交集进行连接。
1.2 外连接
how='outer',dataframe的链接方式为外连接,我们可以理解基于共同列的并集进行连接,参数on设置连接的共有列名。
# 单列的外连接
# 定义df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# 基于共同列alpha的内连接
df4 = pd.merge(df1,df2,how='outer',on='alpha')
df4
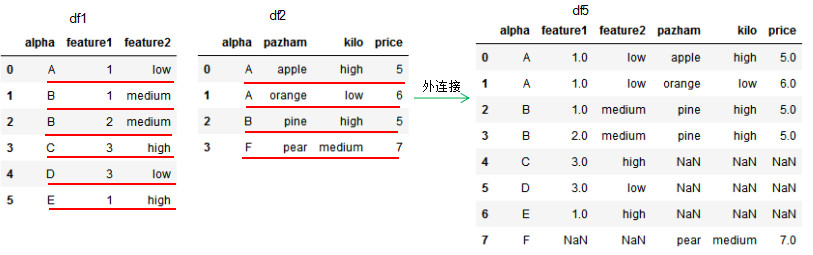
若两个dataframe间除了on设置的连接列外并无相同列,则该列的值置为NaN。
1.3 左连接
how='left',dataframe的链接方式为左连接,我们可以理解基于左边位置dataframe的列进行连接,参数on设置连接的共有列名。
# 单列的左连接
# 定义df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# 基于共同列alpha的左连接
df5 = pd.merge(df1,df2,how='left',on='alpha')
df5

因为df2的连接列alpha有两个'A'值,所以左连接的df5有两个'A'值,若两个dataframe间除了on设置的连接列外并无相同列,则该列的值置为NaN。
1.4 右连接
how='right',dataframe的链接方式为左连接,我们可以理解基于右边位置dataframe的列进行连接,参数on设置连接的共有列名。
# 单列的右连接
# 定义df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# 基于共同列alpha的右连接
df6 = pd.merge(df1,df2,how='right',on='alpha')
df6
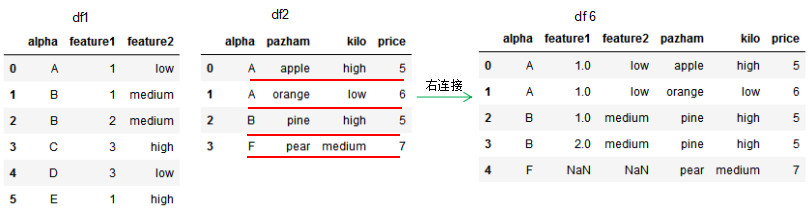
因为df1的连接列alpha有两个'B'值,所以右连接的df6有两个'B'值。若两个dataframe间除了on设置的连接列外并无相同列,则该列的值置为NaN。
1.5 基于多列的连接算法
多列连接的算法与单列连接一致,本节只介绍基于多列的内连接和右连接,读者可自己编码并按照本文给出的图解方式去理解外连接和左连接。
多列的内连接:
# 多列的内连接
# 定义df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'beta':['a','a','b','c','c','e'],
'feature1':[1,1,2,3,3,1],'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'beta':['d','d','b','f'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# 基于共同列alpha和beta的内连接
df7 = pd.merge(df1,df2,on=['alpha','beta'],how='inner')
df7
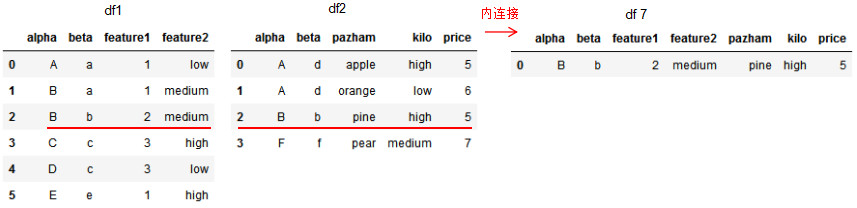
多列的右连接:
# 多列的右连接
# 定义df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'beta':['a','a','b','c','c','e'],
'feature1':[1,1,2,3,3,1],'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'beta':['d','d','b','f'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
print(df1)
print(df2)
# 基于共同列alpha和beta的右连接
df8 = pd.merge(df1,df2,on=['alpha','beta'],how='right')
df8
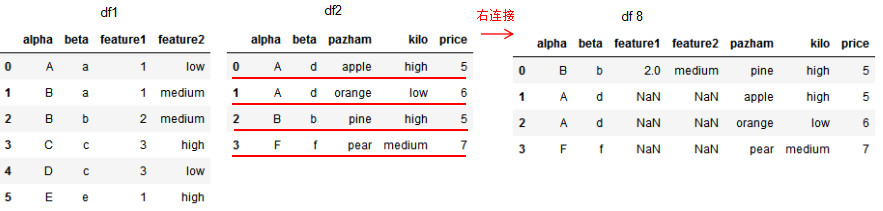
1.6 基于index的连接方法
前面介绍了基于column的连接方法,merge方法亦可基于index连接dataframe。
# 基于column和index的右连接
# 定义df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'beta':['a','a','b','c','c','e'],
'feature1':[1,1,2,3,3,1],'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])},index=['d','d','b','f'])
print(df1)
print(df2)
# 基于df1的beta列和df2的index连接
df9 = pd.merge(df1,df2,how='inner',left_on='beta',right_index=True)
df9
图解index和column的内连接方法:

设置参数suffixes以修改除连接列外相同列的后缀名。
# 基于df1的alpha列和df2的index内连接
df9 = pd.merge(df1,df2,how='inner',left_on='beta',right_index=True,suffixes=('_df1','_df2'))
df9

2. join方法
join方法是基于index连接dataframe,merge方法是基于column连接,连接方法有内连接,外连接,左连接和右连接,与merge一致。
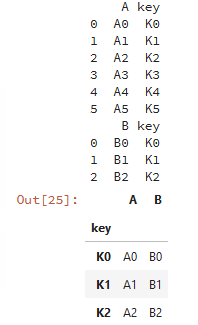
index与index的连接:
caller = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
other = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'B': ['B0', 'B1', 'B2']})
print(caller)print(other)# lsuffix和rsuffix设置连接的后缀名
caller.join(other,lsuffix='_caller', rsuffix='_other',how='inner')

join也可以基于列进行连接:
caller = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
other = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'B': ['B0', 'B1', 'B2']})
print(caller)
print(other)
# 基于key列进行连接
caller.set_index('key').join(other.set_index('key'),how='inner')
因此,join和merge的连接方法类似,这里就不展开join方法了,建议用merge方法。
3. concat方法
concat方法是拼接函数,有行拼接和列拼接,默认是行拼接,拼接方法默认是外拼接(并集),拼接的对象是pandas数据类型。
3.1 series类型的拼接方法
行拼接:
df1 = pd.Series([1.1,2.2,3.3],index=['i1','i2','i3']) df2 = pd.Series([4.4,5.5,6.6],index=['i2','i3','i4']) print(df1) print(df2) # 行拼接 pd.concat([df1,df2])
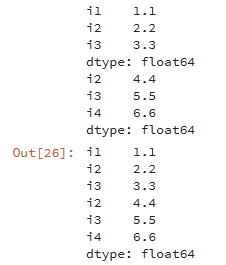
行拼接若有相同的索引,为了区分索引,我们在最外层定义了索引的分组情况。
# 对行拼接分组 pd.concat([df1,df2],keys=['fea1','fea2'])

列拼接:
默认以并集的方式拼接:
# 列拼接,默认是并集 pd.concat([df1,df2],axis=1)

以交集的方式拼接:
# 列拼接的内连接(交) pd.concat([df1,df2],axis=1,join='inner')

设置列拼接的列名:
# 列拼接的内连接(交) pd.concat([df1,df2],axis=1,join='inner',keys=['fea1','fea2'])

对指定的索引拼接:
# 指定索引[i1,i2,i3]的列拼接 pd.concat([df1,df2],axis=1,join_axes=[['i1','i2','i3']])

3.2 dataframe类型的拼接方法
行拼接:
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'B': ['B0', 'B1', 'B2']})
print(df1)
print(df2)
# 行拼接
pd.concat([df1,df2])

列拼接:
# 列拼接 pd.concat([df1,df2],axis=1)
若列拼接或行拼接有重复的列名和行名,则报错:
# 判断是否有重复的列名,若有则报错 pd.concat([df1,df2],axis=1,verify_integrity = True)
ValueError: Indexes have overlapping values: ['key']
4. 小结
merge和join方法基本上能实现相同的功能,建议用merge。
到此这篇关于pandas数据的合并与拼接的实现的文章就介绍到这了,更多相关pandas数据合并与拼接内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

一文搞懂Python中Pandas数据合并
目录 1.concat() 主要参数 示例 2.merge() 参数 示例 3.append() 参数 示例 4.join() 示例 数据合并是数据处理过程中的必经环节,pandas作为数据分析的利器,提供了四种常用的数据合并方式,让我们看看如何使用这些方法吧! 1.concat() concat() 可用于两个及多个 DataFrame 间行/列方向进行内联或外联拼接操作,默认对行(沿 y 轴)取并集. 使用方式 pd.concat( objs: Union[Iterable[~FrameOr
-
pandas中DataFrame数据合并连接(merge、join、concat)
pandas作者Wes McKinney 在[PYTHON FOR DATA ANALYSIS]中对pandas的方方面面都有了一个权威简明的入门级的介绍,但在实际使用过程中,我发现书中的内容还只是冰山一角.谈到pandas数据的行更新.表合并等操作,一般用到的方法有concat.join.merge.但这三种方法对于很多新手来说,都不太好分清使用的场合与用途.今天就pandas官网中关于数据合并和重述的章节做个使用方法的总结. 文中代码块主要有pandas官网教程提供. 1 concat co
-
pandas进行数据的交集与并集方式的数据合并方法
数据合并有多种方式,其中最常见的应该就是交集和并集的求取.之前通过分析总结过pandas数据merge功能默认的行为,其实默认下求取的就是两个数据的"交集". 有如下数据定义: In [26]: df1 Out[26]: data1 key 0 0 b 1 1 b 2 2 a 3 3 c 4 4 a 5 5 a 6 6 b In [27]: df2 Out[27]: data2 key 0 0 a 1 1 b 2 2 d 3 3 b 进行merge的结果: In [28]: pd.me
-
Python基础之pandas数据合并
一.concat concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合 pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False) axis: 需要合并链接的轴,0是行,1是列join:连接的方式 inner,或者outer 二.相同字段的表首尾相接 #现将表构成l
-
Pandas 按索引合并数据集的方法
如下所示: import numpy as np import pandas as pd from pandas import Series,DataFrame 一.merge函数 left1 = DataFrame({'水果':['苹果','梨','草莓'], '价格':[3,4,5], '数量':[9,8,7]}).set_index('水果') right1 = DataFrame({'水果':['苹果','草莓'], '产地':['美国','中国']}) print(left1) pri
-
在Pandas中DataFrame数据合并,连接(concat,merge,join)的实例
最近在工作中,遇到了数据合并.连接的问题,故整理如下,供需要者参考~ 一.concat:沿着一条轴,将多个对象堆叠到一起 concat方法相当于数据库中的全连接(union all),它不仅可以指定连接的方式(outer join或inner join)还可以指定按照某个轴进行连接.与数据库不同的是,它不会去重,但是可以使用drop_duplicates方法达到去重的效果. concat(objs, axis=0, join='outer', join_axes=None, ignore_ind
-
详解PANDAS 数据合并与重塑(join/merge篇)
在上一篇文章中,我整理了pandas在数据合并和重塑中常用到的concat方法的使用说明.在这里,将接着介绍pandas中也常常用到的join 和merge方法 merge pandas的merge方法提供了一种类似于SQL的内存链接操作,官网文档提到它的性能会比其他开源语言的数据操作(例如R)要高效. 和SQL语句的对比可以看这里 merge的参数 on:列名,join用来对齐的那一列的名字,用到这个参数的时候一定要保证左表和右表用来对齐的那一列都有相同的列名. left_on:左表对齐的列,
-
pandas数据的合并与拼接的实现
目录 1. Merge方法 1.1 内连接 1.2 外连接 1.3 左连接 1.4 右连接 1.5 基于多列的连接算法 1.6 基于index的连接方法 2. join方法 3. concat方法 3.1 series类型的拼接方法 3.2 dataframe类型的拼接方法 4. 小结 Pandas包的merge.join.concat方法可以完成数据的合并和拼接,merge方法主要基于两个dataframe的共同列进行合并,join方法主要基于两个dataframe的索引进行合并,concat
-
pandas数据拼接的实现示例
一 前言 pandas数据拼接有可能会用到,比如出现重复数据,需要合并两份数据的交集,并集就是个不错的选择,知识追寻者本着技多不压身的态度蛮学习了一下下: 二 数据拼接 在进行学习数据转换之前,先学习一些数拼接相关的知识 2.1 join()联结 有关merge操作知识追寻者这边不提及,有空可能后面会专门出一篇相关文章,因为其学习方式根SQL的表联结类似,不是几行能说清楚的知识点: join操作能将 2 个DataFrame 合并为一块,前提是DataFrame 之间的列没有重复: # -*-
-
python pandas数据处理教程之合并与拼接
目录 前言 一.join 1.leftjoin 2.rightjoin 3.innerjoin 4.outjoin 二.merge 三.concat 1.纵向合并 2.横向合并 四.append 1.同结构数据追加 2.不同结构数据追加 3.追加合并多个数据集 五.combine_first 六.update 总结 前言 在许多应用中,数据可能来自不同的渠道,在数据处理的过程中常常需要将这些数据集进行组合合并拼接,形成更加丰富的数据集.pandas提供了多种方法完全可以满足数据处理的常用需求.具
-
pandas数据合并之pd.concat()用法详解
目录 一.简介 二 .代码 例1:上下堆叠拼接 例2:axis=1 左右拼接 一.简介 pd.concat()函数可以沿着指定的轴将多个dataframe或者series拼接到一起. 基本语法: pd.concat( objs, axis=0, join=‘outer’, join_axes=None,ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=Tr
-
python Pandas中数据的合并与分组聚合
目录 一.字符串离散化示例 二.数据合并 2.1 join 2.2 merge 三.数据的分组和聚合 四.索引 总结 一.字符串离散化示例 对于一组电影数据,我们希望统计电影分类情况,应该如何处理数据?(每一个电影都有很多个分类) 思路:首先构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1 代码: # coding=utf-8 import pandas as pd from matplotlib import pyplot as plt import numpy as
-
Python必备技巧之Pandas数据合并函数
目录 1. concat 2. append 3. merge 4. join 5. combine 总结 1. concat concat是pandas中专门用于数据连接合并的函数,功能非常强大,支持纵向合并和横向合并,默认情况下是纵向合并,具体可以通过参数进行设置. pd.concat( objs: 'Iterable[NDFrame] | Mapping[Hashable, NDFrame]', axis=0, join='outer', ignore_index: 'bool' = Fa
-
Python Pandas数据合并pd.merge用法详解
目录 前言 语法 参数 1.连接键 2.索引连接 3.多连接键 4.连接方法 5.连接指示 总结 前言 实现类似SQL的join操作,通过pd.merge()方法可以自由灵活地操作各种逻辑的数据连接.合并等操作 可以将两个DataFrame或Series合并,最终返回一个合并后的DataFrame 语法 pd.merge(left, right, how = 'inner', on = None, left_on = None, right_on = None, left_index = Fal
-
使用pandas忽略行列索引,纵向拼接多个dataframe
从wind上面搞到一批股票数据后发现:本来是一个类型的数据,但是由于季度不同,列名也不同,导致使用pandas合并多个报表的时候总是出现一大堆NaN,所以这里我写了一个函数,专门针对这样的表 它的思路是: 生成一堆单词,然后把这些表的列索引全部替换为这些单词,然后调用 pd.concat() 把这些dataframe全部合并后再把列索引改回来,当然,这里也可以手动指定列索引. 使用方法见代码的最后一行,传入一个dataframe的list就可以了. import pandas as pd fro