详解C语言编程之thread多线程
目录
- 线程创建与结束
- 线程的创建方式:
- 线程的结束方式:
- join()
- detach()
- 互斥锁
- <mutex> 头文件介绍
- std::mutex 介绍
- std::lock_guard
- std::unique_lock
- 示例:
- 原子变量
- 线程同步通信
- 线程死锁
- 死锁概述
- 死锁产生的条件
- 示例:
- 总结
线程创建与结束
C++11 新标准中引入了四个头文件来支持多线程编程,他们分别是<atomic> ,<thread>,<mutex>,<condition_variable>和<future>。
<atomic>:该头文主要声明了两个类, std::atomic 和 std::atomic_flag,另外还声明了一套 C 风格的原子类型和与 C 兼容的原子操作的函数。<thread>:该头文件主要声明了 std::thread 类,另外 std::this_thread 命名空间也在该头文件中。<mutex>:该头文件主要声明了与互斥量(mutex)相关的类,包括 std::mutex 系列类,std::lock_guard, std::unique_lock, 以及其他的类型和函数。<condition_variable>:该头文件主要声明了与条件变量相关的类,包括 std::condition_variable 和 std::condition_variable_any。<future>:该头文件主要声明了 std::promise, std::package_task 两个 Provider 类,以及 std::future 和 std::shared_future 两个 Future 类,另外还有一些与之相关的类型和函数,std::async() 函数就声明在此头文件中。
#include <iostream>
#include <utility>
#include <thread>
#include <chrono>
#include <functional>
#include <atomic>
void f1(int n)
{
for (int i = 0; i < 5; ++i) {
std::cout << "Thread " << n << " executing\n";
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
}
}
void f2(int& n)
{
std::cout << "thread-id:" << std::this_thread::get_id() << "\n";
for (int i = 0; i < 5; ++i) {
std::cout << "Thread 2 executing:" << n << "\n";
++n;
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
}
}
int main()
{
int n = 0;
std::thread t1; // t1 is not a thread t1 不是一个线程
std::thread t2(f1, n + 1); // pass by value 传值
std::thread t3(f2, std::ref(n)); // pass by reference 传引用
std::this_thread::sleep_for(std::chrono::milliseconds(2000));
std::cout << "\nThread 4 create :\n";
std::thread t4(std::move(t3)); // t4 is now running f2(). t3 is no longer a thread 这时候t3将不是线程,t4接替t3继续运行f2
t2.join();
t4.join();
std::cout << "Final value of n is " << n << '\n';
}
线程的创建方式:
(1). 默认构造函数,创建一个空的 thread 执行对象。
(2). 初始化构造函数,创建一个 thread对象,该 thread对象可被 joinable,新产生的线程会调用 fn 函数,该函数的参数由 args 给出。
(3). 拷贝构造函数(被禁用),意味着 thread 不可被拷贝构造。
(4). move 构造函数,move 构造函数,调用成功之后 x 不代表任何 thread 执行对象。
注意:可被 joinable 的 thread 对象必须在他们销毁之前被主线程 join 或者将其设置为 detached.
std::thread定义一个线程对象,传入线程所需要的线程函数和参数,线程自动开启
线程的结束方式:
join()
创建线程执行线程函数,调用该函数会阻塞当前线程,直到线程执行完join才返回;等待t线程结束,当前线程继续往下运行
detach()
detach调用之后,目标线程就成为了守护线程,驻留后台运行,与之关联的std::thread对象失去对目标线程的关联,无法再通过std::thread对象取得该线程的控制权,由操作系统负责回收资源;主线程结束,整个进程结束,所有子线程都自动结束了!
#include <iostream>
#include <thread>
using namespace std;
void threadHandle1(int time)
{
//让子线程睡眠time秒
std::this_thread::sleep_for(std::chrono::seconds(time));
cout << "hello thread1!" << endl;
}
void threadHandle2(int time)
{
//让子线程睡眠time秒ace this_thread是namespace
std::this_thread::sleep_for(std::chrono::seconds(time));
cout << "hello thread2!" << endl;
}
int main()
{
//创建了一个线程对象,传入一个线程函数(作为线程入口函数),
//新线程就开始运行了,没有先后顺序,随着CPU的调度算法执行
std::thread t1(threadHandle1, 2);
std::thread t2(threadHandle2, 3);
//主线程(main)运行到这里,等待子线程结束,主线程才继续往下运行
t1.join();
t2.join();
//把子线程设置为分离线程,子线程和主线程就毫无关系了
//主线程结束的时候查看其他线程
//但是这个子线程运行完还是没运行完都和这个主线程没关系了
//这个子线程就从这个main分离出去了
//运行程序时也看不到这个子线程的任何输出打印了
//t1.detach();
cout << "main thread done!" << endl;
//主线程运行完成,查看如果当前进程还有未运行完成的子线程
//进程就会异常终止
return 0;
}
互斥锁
Mutex 又称互斥量,C++ 11中与 Mutex 相关的类(包括锁类型)和函数都声明在 <mutex> 头文件中,所以如果你需要使用 std::mutex,就必须包含 <mutex> 头文件。
<mutex> 头文件介绍
Mutex 系列类(四种)
std::mutex,最基本的 Mutex 类。std::recursive_mutex,递归 Mutex 类。std::time_mutex,定时 Mutex 类。std::recursive_timed_mutex,定时递归 Mutex 类。
Lock 类(两种)
std::lock_guard,与 Mutex RAII 相关,方便线程对互斥量上锁。
std::unique_lock,与 Mutex RAII 相关,方便线程对互斥量上锁,但提供了更好的上锁和解锁控制。
其他类型
std::once_flagstd::adopt_lock_tstd::defer_lock_tstd::try_to_lock_t
函数
std::try_lock,尝试同时对多个互斥量上锁。std::lock,可以同时对多个互斥量上锁。std::call_once,如果多个线程需要同时调用某个函数,call_once 可以保证多个线程对该函数只调用一次。
std::mutex 介绍
下面以 std::mutex 为例介绍 C++11 中的互斥量用法。
std::mutex 是C++11 中最基本的互斥量,std::mutex 对象提供了独占所有权的特性——即不支持递归地对 std::mutex 对象上锁,而 std::recursive_lock 则可以递归地对互斥量对象上锁。
std::mutex 的成员函数
- 构造函数,std::mutex不允许拷贝构造,也不允许 move 拷贝,最初产生的 mutex 对象是处于 unlocked 状态的。
- lock(),调用线程将锁住该互斥量。线程调用该函数会发生下面 3 种情况:
(1). 如果该互斥量当前没有被锁住,则调用线程将该互斥量锁住,直到调用 unlock之前,该线程一直拥有该锁。
(2). 如果当前互斥量被其他线程锁住,则当前的调用线程被阻塞住。
(3). 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)。
- unlock(), 解锁,释放对互斥量的所有权。
- try_lock(),尝试锁住互斥量,如果互斥量被其他线程占有,则当前线程也不会被阻塞。线程调用该函数也会出现下面 3 种情况
(1). 如果当前互斥量没有被其他线程占有,则该线程锁住互斥量,直到该线程调用 unlock 释放互斥量。
(2). 如果当前互斥量被其他线程锁住,则当前调用线程返回 false,而并不会被阻塞掉。
(3). 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)
为了保证lock()和unlock()对应使用,一般不直接使用mutex,而是和lock_guard、unique_lock一起使用;
std::lock_guard
std::lock_guard是RAII模板类的简单实现,功能简单。
1.std::lock_guard 在构造函数中进行加锁,析构函数中进行解锁。
// CLASS TEMPLATE lock_guard
template<class _Mutex>
class lock_guard
{ // class with destructor that unlocks a mutex
public:
using mutex_type = _Mutex;
explicit lock_guard(_Mutex& _Mtx)
: _MyMutex(_Mtx)
{ // construct and lock
_MyMutex.lock();
}
lock_guard(_Mutex& _Mtx, adopt_lock_t)
: _MyMutex(_Mtx)
{ // construct but don't lock
}
~lock_guard() noexcept
{ // unlock
_MyMutex.unlock();
}
lock_guard(const lock_guard&) = delete;
lock_guard& operator=(const lock_guard&) = delete;
private:
_Mutex& _MyMutex;
};
从lock_guard源码可以看出,它在构造时进行上锁,在出作用域执行析构函数释放锁;同时不允许拷贝构造和赋值运算符;比较简单,不能用在函数参数传递或者返回过程中,因为它的拷贝构造和赋值运算符被禁用了;只能用在简单的临界区代码的互斥操作
std::unique_lock
类 unique_lock 是通用互斥包装器,允许延迟锁定、锁定的有时限尝试、递归锁定、所有权转移和与条件变量一同使用。
unique_lock比lock_guard使用更加灵活,功能更加强大。
使用unique_lock需要付出更多的时间、性能成本。
template<class _Mutex>
class unique_lock
{ // whizzy class with destructor that unlocks mutex
public:
typedef _Mutex mutex_type;
// CONSTRUCT, ASSIGN, AND DESTROY
unique_lock() noexcept
: _Pmtx(nullptr), _Owns(false)
{ // default construct
}
explicit unique_lock(_Mutex& _Mtx)
: _Pmtx(_STD addressof(_Mtx)), _Owns(false)
{ // construct and lock
_Pmtx->lock();
_Owns = true;
}
unique_lock(_Mutex& _Mtx, adopt_lock_t)
: _Pmtx(_STD addressof(_Mtx)), _Owns(true)
{ // construct and assume already locked
}
unique_lock(_Mutex& _Mtx, defer_lock_t) noexcept
: _Pmtx(_STD addressof(_Mtx)), _Owns(false)
{ // construct but don't lock
}
unique_lock(_Mutex& _Mtx, try_to_lock_t)
: _Pmtx(_STD addressof(_Mtx)), _Owns(_Pmtx->try_lock())
{ // construct and try to lock
}
template<class _Rep,
class _Period>
unique_lock(_Mutex& _Mtx,
const chrono::duration<_Rep, _Period>& _Rel_time)
: _Pmtx(_STD addressof(_Mtx)), _Owns(_Pmtx->try_lock_for(_Rel_time))
{ // construct and lock with timeout
}
template<class _Clock,
class _Duration>
unique_lock(_Mutex& _Mtx,
const chrono::time_point<_Clock, _Duration>& _Abs_time)
: _Pmtx(_STD addressof(_Mtx)), _Owns(_Pmtx->try_lock_until(_Abs_time))
{ // construct and lock with timeout
}
unique_lock(_Mutex& _Mtx, const xtime *_Abs_time)
: _Pmtx(_STD addressof(_Mtx)), _Owns(false)
{ // try to lock until _Abs_time
_Owns = _Pmtx->try_lock_until(_Abs_time);
}
unique_lock(unique_lock&& _Other) noexcept
: _Pmtx(_Other._Pmtx), _Owns(_Other._Owns)
{ // destructive copy
_Other._Pmtx = nullptr;
_Other._Owns = false;
}
unique_lock& operator=(unique_lock&& _Other)
{ // destructive copy
if (this != _STD addressof(_Other))
{ // different, move contents
if (_Owns)
_Pmtx->unlock();
_Pmtx = _Other._Pmtx;
_Owns = _Other._Owns;
_Other._Pmtx = nullptr;
_Other._Owns = false;
}
return (*this);
}
~unique_lock() noexcept
{ // clean up
if (_Owns)
_Pmtx->unlock();
}
unique_lock(const unique_lock&) = delete;
unique_lock& operator=(const unique_lock&) = delete;
void lock()
{ // lock the mutex
_Validate();
_Pmtx->lock();
_Owns = true;
}
_NODISCARD bool try_lock()
{ // try to lock the mutex
_Validate();
_Owns = _Pmtx->try_lock();
return (_Owns);
}
template<class _Rep,
class _Period>
_NODISCARD bool try_lock_for(const chrono::duration<_Rep, _Period>& _Rel_time)
{ // try to lock mutex for _Rel_time
_Validate();
_Owns = _Pmtx->try_lock_for(_Rel_time);
return (_Owns);
}
template<class _Clock,
class _Duration>
_NODISCARD bool try_lock_until(const chrono::time_point<_Clock, _Duration>& _Abs_time)
{ // try to lock mutex until _Abs_time
_Validate();
_Owns = _Pmtx->try_lock_until(_Abs_time);
return (_Owns);
}
_NODISCARD bool try_lock_until(const xtime *_Abs_time)
{ // try to lock the mutex until _Abs_time
_Validate();
_Owns = _Pmtx->try_lock_until(_Abs_time);
return (_Owns);
}
void unlock()
{ // try to unlock the mutex
if (!_Pmtx || !_Owns)
_THROW(system_error(
_STD make_error_code(errc::operation_not_permitted)));
_Pmtx->unlock();
_Owns = false;
}
void swap(unique_lock& _Other) noexcept
{ // swap with _Other
_STD swap(_Pmtx, _Other._Pmtx);
_STD swap(_Owns, _Other._Owns);
}
_Mutex *release() noexcept
{ // disconnect
_Mutex *_Res = _Pmtx;
_Pmtx = nullptr;
_Owns = false;
return (_Res);
}
_NODISCARD bool owns_lock() const noexcept
{ // return true if this object owns the lock
return (_Owns);
}
explicit operator bool() const noexcept
{ // return true if this object owns the lock
return (_Owns);
}
_NODISCARD _Mutex *mutex() const noexcept
{ // return pointer to managed mutex
return (_Pmtx);
}
private:
_Mutex *_Pmtx;
bool _Owns;
void _Validate() const
{ // check if the mutex can be locked
if (!_Pmtx)
_THROW(system_error(
_STD make_error_code(errc::operation_not_permitted)));
if (_Owns)
_THROW(system_error(
_STD make_error_code(errc::resource_deadlock_would_occur)));
}
};
其中,有_Mutex *_Pmtx; 指向一把锁的指针;不允许使用左值拷贝构造和赋值,但是可以使用右值拷贝构造和赋值,可以在函数调用过程中使用。因此可以和条件变量一起使用:cv.wait(lock);//可以作为函数参数传入;
示例:
在多线程环境中运行的代码段,需要考虑是否存在竞态条件,如果存在竞态条件,我们就说该代码段不是线程安全的,不能直接运行在多线程环境当中,对于这样的代码段,我们经常称之为临界区资源,对于临界区资源,多线程环境下需要保证它以原子操作执行,要保证临界区的原子操作,就需要用到线程间的互斥操作-锁机制,thread类库还提供了更轻量级的基于CAS操作的原子操作类。
无锁时:
#include <iostream>
#include <atomic>//C++11线程库提供的原子类
#include <thread>//C++线程类库的头文件
#include <vector>
int count = 0;
//线程函数
void sumTask()
{
//每个线程给count加10次
for (int i = 0; i < 10; ++i)
{
count++;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
}
int main()
{
//创建10个线程放在容器当中
std::vector<std::thread> vec;
for (int i = 0; i < 10; ++i)
{
vec.push_back(std::thread(sumTask));
}
//等待线程执行完成
for (unsigned int i = 0; i < vec.size(); ++i)
{
vec[i].join();
}
//所有子线程运行结束
std::cout << "count : " << count << std::endl;
return 0;
}
多线程同时对count进行操作,并不能保证同时只有一个线程对count执行++操作,最后的的结果不一定是100;
使用lock_guard:
#include <iostream>
#include <atomic>//C++11线程库提供的原子类
#include <thread>//C++线程类库的头文件
#include <mutex>
#include <vector>
int count = 0;
std::mutex mutex;
//线程函数
void sumTask()
{
//每个线程给count加10次
for (int i = 0; i < 10; ++i)
{
{
std::lock_guard<std::mutex> lock(mutex);
count++;
}
;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
}
int main()
{
//创建10个线程放在容器当中
std::vector<std::thread> vec;
for (int i = 0; i < 10; ++i)
{
vec.push_back(std::thread(sumTask));
}
//等待线程执行完成
for (unsigned int i = 0; i < vec.size(); ++i)
{
vec[i].join();
}
//所有子线程运行结束,count的结果每次运行应该都是10000
std::cout << "count : " << count << std::endl;
return 0;
}
对count++ 操作上锁,保证一次只有一个线程能对其操作,结果是100
原子变量
上面的保证原子操作需要在多线程环境下添加互斥操作,但是mutex互斥锁毕竟比较重,对于系统消耗有些大,C++11的thread类库提供了针对简单类型的原子操作类,如std::atomic_int,atomic_long,atomic_bool等,它们值的增减都是基于CAS操作的,既保证了线程安全,效率还非常高。
#include <iostream>
#include <atomic>//C++11线程库提供的原子类
#include <thread>//C++线程类库的头文件
#include <vector>
//原子整型,CAS操作保证给count自增自减的原子操作
std::atomic_int count = 0;
//线程函数
void sumTask()
{
//每个线程给count加10次
for (int i = 0; i < 10; ++i)
{
count++;
}
}
int main()
{
//创建10个线程放在容器当中
std::vector<std::thread> vec;
for (int i = 0; i < 10; ++i)
{
vec.push_back(std::thread(sumTask));
}
//等待线程执行完成
for (unsigned int i = 0; i < vec.size(); ++i)
{
vec[i].join();
}
//所有子线程运行结束,count的结果每次运行应该都是10000
std::cout << "count : " << count << std::endl;
return 0;
}
线程同步通信
多线程在运行过程中,各个线程都是随着OS的调度算法,占用CPU时间片来执行指令做事情,每个线程的运行完全没有顺序可言。但是在某些应用场景下,一个线程需要等待另外一个线程的运行结果,才能继续往下执行,这就需要涉及线程之间的同步通信机制。
线程间同步通信最典型的例子就是生产者-消费者模型,生产者线程生产出产品以后,会通知消费者线程去消费产品;如果消费者线程去消费产品,发现还没有产品生产出来,它需要通知生产者线程赶快生产产品,等生产者线程生产出产品以后,消费者线程才能继续往下执行。
C++11 线程库提供的条件变量condition_variable,就是Linux平台下的Condition Variable机制,用于解决线程间的同步通信问题,下面通过代码演示一个生产者-消费者线程模型:
#include <iostream> //std::cout
#include <thread> //std::thread
#include <mutex> //std::mutex, std::unique_lock
#include <condition_variable> //std::condition_variable
#include <vector>
//定义互斥锁(条件变量需要和互斥锁一起使用)
std::mutex mtx;
//定义条件变量(用来做线程间的同步通信)
std::condition_variable cv;
//定义vector容器,作为生产者和消费者共享的容器
std::vector<int> vec;
//生产者线程函数
void producer()
{
//生产者每生产一个,就通知消费者消费一个
for (int i = 1; i <= 10; ++i)
{
//获取mtx互斥锁资源
std::unique_lock<std::mutex> lock(mtx);
//如果容器不为空,代表还有产品未消费,等待消费者线程消费完,再生产
while (!vec.empty())
{
//判断容器不为空,进入等待条件变量的状态,释放mtx锁,
//让消费者线程抢到锁能够去消费产品
cv.wait(lock);
}
vec.push_back(i); // 表示生产者生产的产品序号i
std::cout << "producer生产产品:" << i << std::endl;
/*
生产者线程生产完产品,通知等待在cv条件变量上的消费者线程,
可以开始消费产品了,然后释放锁mtx
*/
cv.notify_all();
//生产一个产品,睡眠100ms
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
//消费者线程函数
void consumer()
{
//消费者每消费一个,就通知生产者生产一个
for (int i = 1; i <= 10; ++i)
{
//获取mtx互斥锁资源
std::unique_lock<std::mutex> lock(mtx);
//如果容器为空,代表还有没有产品可消费,等待生产者生产,再消费
while (vec.empty())
{
//判断容器为空,进入等待条件变量的状态,释放mtx锁,
//让生产者线程抢到锁能够去生产产品
cv.wait(lock);
}
int data = vec.back(); // 表示消费者消费的产品序号i
vec.pop_back();
std::cout << "consumer消费产品:" << data << std::endl;
/*
消费者消费完产品,通知等待在cv条件变量上的生产者线程,
可以开始生产产品了,然后释放锁mtx
*/
cv.notify_all();
//消费一个产品,睡眠100ms
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
int main()
{
//创建生产者和消费者线程
std::thread t1(producer);
std::thread t2(consumer);
//main主线程等待所有子线程执行完
t1.join();
t2.join();
return 0;
}
线程死锁
死锁概述
线程死锁是指两个或两个以上的线程互相持有对方所需要的资源,由于synchronized的特性,一个线程持有一个资源,或者说获得一个锁,在该线程释放这个锁之前,其它线程是获取不到这个锁的,而且会一直死等下去,因此这便造成了死锁。
死锁产生的条件
- 互斥条件:一个资源,或者说一个锁只能被一个线程所占用,当一个线程首先获取到这个锁之后,在该线程释放这个锁之前,其它线程均是无法获取到这个锁的。
- 占有且等待:一个线程已经获取到一个锁,再获取另一个锁的过程中,即使获取不到也不会释放已经获得的锁。
- 不可剥夺条件:任何一个线程都无法强制获取别的线程已经占有的锁
- 循环等待条件:线程A拿着线程B的锁,线程B拿着线程A的锁。
示例:
当一个程序的多个线程获取多个互斥锁资源的时候,就有可能发生死锁问题,比如线程A先获取了锁1,线程B获取了锁2,进而线程A还需要获取锁2才能继续执行,但是由于锁2被线程B持有还没有释放,线程A为了等待锁2资源就阻塞了;线程B这时候需要获取锁1才能往下执行,但是由于锁1被线程A持有,导致A也进入阻塞。
线程A和线程B都在等待对方释放锁资源,但是它们又不肯释放原来的锁资源,导致线程A和B一直互相等待,进程死锁了。下面代码示例演示这个问题:
#include <iostream> //std::cout
#include <thread> //std::thread
#include <mutex> //std::mutex, std::unique_lock
#include <condition_variable> //std::condition_variable
#include <vector>
//锁资源1
std::mutex mtx1;
//锁资源2
std::mutex mtx2;
//线程A的函数
void taskA()
{
//保证线程A先获取锁1
std::lock_guard<std::mutex> lockA(mtx1);
std::cout << "线程A获取锁1" << std::endl;
//线程A睡眠2s再获取锁2,保证锁2先被线程B获取,模拟死锁问题的发生
std::this_thread::sleep_for(std::chrono::seconds(2));
//线程A先获取锁2
std::lock_guard<std::mutex> lockB(mtx2);
std::cout << "线程A获取锁2" << std::endl;
std::cout << "线程A释放所有锁资源,结束运行!" << std::endl;
}
//线程B的函数
void taskB()
{
//线程B先睡眠1s保证线程A先获取锁1
std::this_thread::sleep_for(std::chrono::seconds(1));
std::lock_guard<std::mutex> lockB(mtx2);
std::cout << "线程B获取锁2" << std::endl;
//线程B尝试获取锁1
std::lock_guard<std::mutex> lockA(mtx1);
std::cout << "线程B获取锁1" << std::endl;
std::cout << "线程B释放所有锁资源,结束运行!" << std::endl;
}
int main()
{
//创建生产者和消费者线程
std::thread t1(taskA);
std::thread t2(taskB);
//main主线程等待所有子线程执行完
t1.join();
t2.join();
return 0;
}
输出:

可以看到,线程A获取锁1、线程B获取锁2以后,进程就不往下继续执行了,一直等待在这里,如果这是我们碰到的一个问题场景,我们如何判断出这是由于线程间死锁引起的呢?
打开process Explorer.找到该进程,查看线程状态,发现线程的cpu利用率为0,那么应该不是死循环,应该是死锁了:

点击vs 的全部中断:查看每一个线程的函数执行的位置

发现当前线程正在申请锁的位置,判断出应该是锁了。
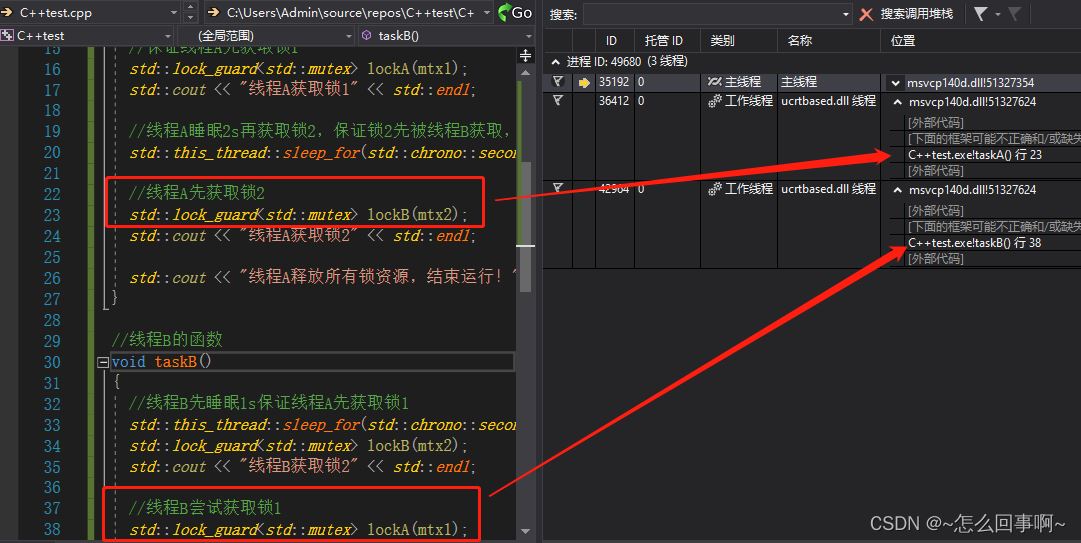
同时主线程走了等待子线程结束;

那如果是死循环的情况呢?,如将线程2加一个死循环:
#include <iostream> //std::cout
#include <thread> //std::thread
#include <mutex> //std::mutex, std::unique_lock
#include <condition_variable> //std::condition_variable
#include <vector>
//锁资源1
std::mutex mtx1;
//锁资源2
std::mutex mtx2;
//线程A的函数
void taskA()
{
//保证线程A先获取锁1
std::lock_guard<std::mutex> lockA(mtx1);
std::cout << "线程A获取锁1" << std::endl;
//线程A睡眠2s再获取锁2,保证锁2先被线程B获取,模拟死锁问题的发生
std::this_thread::sleep_for(std::chrono::seconds(2));
//线程A先获取锁2
std::lock_guard<std::mutex> lockB(mtx2);
std::cout << "线程A获取锁2" << std::endl;
std::cout << "线程A释放所有锁资源,结束运行!" << std::endl;
}
//线程B的函数
void taskB()
{
while (true)
{
}
}
int main()
{
//创建生产者和消费者线程
std::thread t1(taskA);
std::thread t2(taskB);
//main主线程等待所有子线程执行完
t1.join();
t2.join();
return 0;
}
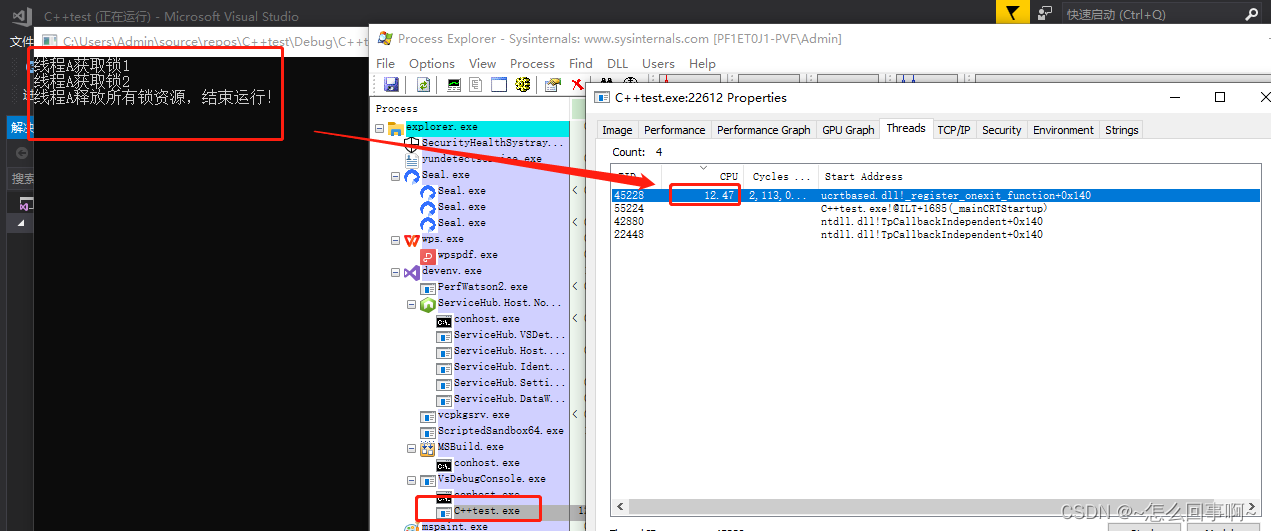
这时候工作线程占满了CPU,我的电脑是8核,因此占满一个cpu是12.5%
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
C语言编程中借助pthreads库进行多线程编程的示例
运行之前需要做一些配置: 1.下载PTHREAD的WINDOWS开发包 pthreads-w32-2-4-0-release.exe(任何一个版本均可) http://sourceware.org/pthreads-win32/ ,解压到一个目录. 2.找到include和lib文件夹,下面分别把它们添加到VC++6.0的头文件路径和静态链接库路径下面: a).Tools->Options,选择Directory页面,然后在Show directories for:中选择Includ
-
C++11并发编程:多线程std::thread
一:概述 C++11引入了thread类,大大降低了多线程使用的复杂度,原先使用多线程只能用系统的API,无法解决跨平台问题,一套代码平台移植,对应多线程代码也必须要修改.现在在C++11中只需使用语言层面的thread可以解决这个问题. 所需头文件<thread> 二:构造函数 1.默认构造函数 thread() noexcept 一个空的std::thread执行对象 2.初始化构造函数 template<class Fn, class... Args> explicit th
-
Python threading多线程编程实例
Python 的多线程有两种实现方法: 函数,线程类 1.函数 调用 thread 模块中的 start_new_thread() 函数来创建线程,以线程函数的形式告诉线程该做什么 复制代码 代码如下: # -*- coding: utf-8 -*- import thread def f(name): #定义线程函数 print "this is " + name if __name__ == '__main__': thread.start_new_thread(f
-
Python多线程编程(三):threading.Thread类的重要函数和方法
这篇文章主要介绍threading模块中的主类Thread的一些主要方法,实例代码如下: 复制代码 代码如下: ''' Created on 2012-9-7 @author: walfred @module: thread.ThreadTest3 @description: ''' import threading class MyThread(threading.Thread): def __init__(self): threading.
-
Java多线程编程中ThreadLocal类的用法及深入
ThreadLocal,直译为"线程本地"或"本地线程",如果你真的这么认为,那就错了!其实,它就是一个容器,用于存放线程的局部变量,我认为应该叫做 ThreadLocalVariable(线程局部变量)才对,真不理解为什么当初 Sun 公司的工程师这样命名. 早在 JDK 1.2 的时代,java.lang.ThreadLocal 就诞生了,它是为了解决多线程并发问题而设计的,只不过设计得有些难用,所以至今没有得到广泛使用.其实它还是挺有用的,不相信的话,我们一起
-

Python多线程编程之threading模块详解
一.介绍 线程是什么?线程有啥用?线程和进程的区别是什么? 线程是操作系统能够进行运算调度的最小单位.被包含在进程中,是进程中的实际运作单位.一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务. 二.Python如何创建线程 2.1 方法一: 创建Thread对象 步骤: 1.目标函数 2.实例化Thread对象 3.调用start()方法 import threading # 目标函数1 def fun1(num): for i in range(
-
详解C语言编程之thread多线程
目录 线程创建与结束 线程的创建方式: 线程的结束方式: join() detach() 互斥锁 <mutex> 头文件介绍 std::mutex 介绍 std::lock_guard std::unique_lock 示例: 原子变量 线程同步通信 线程死锁 死锁概述 死锁产生的条件 示例: 总结 线程创建与结束 C++11 新标准中引入了四个头文件来支持多线程编程,他们分别是<atomic> ,<thread>,<mutex>,<condition
-
详解Python GUI编程之PyQt5入门到实战
1. PyQt5基础 1.1 GUI编程学什么 大致了解你所选择的GUI库 基本的程序的结构:使用这个GUI库来运行你的GUI程序 各种控件的特性和如何使用 控件的样式 资源的加载 控件的布局 事件和信号 动画特效 界面跳转 设计工具的使用 1.2 PyQT是什么 QT是跨平台C++库的集合,它实现高级API来访问现代桌面和移动系统的许多方面.这些服务包括定位和定位服务.多媒体.NFC和蓝牙连接.基于Chromium的web浏览器以及传统的UI开发.PyQt5是Qt v5的一组完整的Python
-
详解C++元编程之Parser Combinator
引子 前不久在CppCon上看到一个Talk:[constexpr All the things](https://www.youtube.com/watch?v=PJwd4JLYJJY),这个演讲技术令我非常震惊,在编译期解析json字符串,进而提出了编译期构造正则表达式(编译期构建FSM),现场掌声一片,而背后依靠的是C++强大的constexpr特性,从而大大提高了编译期计算威力. 早在C++11的时候就有constexpr特性,那时候约束比较多,只能有一条return语句,能做的事情只有
-
详解JUC并发编程之锁
目录 1.自旋锁和自适应锁 2.轻量级锁和重量级锁 轻量级锁加锁过程 轻量级锁解锁过程 3.偏向锁 4.可重入锁和不可重入锁 5.悲观锁和乐观锁 6.公平锁和非公平锁 7.共享锁和独占锁 8.可中断锁和不可中断锁 总结: 当多个线程访问一个对象时,如果不用考虑这些线程在运行环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获得正确的结果,那么这个对象就是线程安全的.但是现实并不是这样子的,所以JVM实现了锁机制,今天就叭叭叭JAVA中各种
-
详解python异步编程之asyncio(百万并发)
前言:python由于GIL(全局锁)的存在,不能发挥多核的优势,其性能一直饱受诟病.然而在IO密集型的网络编程里,异步处理比同步处理能提升成百上千倍的效率,弥补了python性能方面的短板,如最新的微服务框架japronto,resquests per second可达百万级. python还有一个优势是库(第三方库)极为丰富,运用十分方便.asyncio是python3.4版本引入到标准库,python2x没有加这个库,毕竟python3x才是未来啊,哈哈!python3.5又加入了asyn
-
详解Java并发编程之volatile关键字
目录 1.volatile是什么? 2.并发编程的三大特性 3.什么是指令重排序? 4.volatile有什么作用? 5.volatile可以保证原子性? 6.volatile 和 synchronized对比 总结 1.volatile是什么? 首先简单说一下,volatile是什么?volatile是Java中的一个关键字,也是一种同步机制.volatile为了保证变量的可见性,通过volatile修饰的变量具有共享性.修改了volatile修饰的变量,其它线程是可以读取到最新的值的 2.并
-
go语言编程之select信道处理示例详解
目录 select信道处理 fibonacci数列监听 select监听协程 select信道处理 注意:有default就不会阻塞 package main func main() { var chan1 = make(chan int) var chan2 = make(chan int) select { case <-chan1: // 如果chan1成功读到数据,则进行该case处理语句 case chan2: // 如果chan2成功读到数据,则进行该case处理语句 default
-
详解C语言 三大循环 四大跳转 和判断语句
三大循环for while 和 do{ }while; 四大跳转 : 无条件跳转语句 go to; 跳出循环语句 break; 继续跳出循环语句 continue; 返回值语句 return 判断语句 if,if else,if else if else if...else ifelse 组合 if(0 == x) if(0 == y) error(): else{ //program code } else到底与那个if配对 C语言有这样的规定: else 始终与同一括号内最近的未匹配的if语
-
详解C语言gets()函数与它的替代者fgets()函数
在c语言中读取字符串有多种方法,比如scanf() 配合%s使用,但是这种方法只能获取一个单词,即遇到空格等空字符就会返回.如果要读取一行字符串,比如: I love BIT 这种情况,scanf()就无能为力了.这时我们最先想到的是用gets()读取. gets()函数从标准输入(键盘)读入一行数据,所谓读取一行,就是遇到换行符就返回.gets()函数并不读取换行符'\n',它会吧换行符替换成空字符'\0',作为c语言字符串结束的标志. gets()函数经常和puts()函数配对使用,puts
-
详解go语言 make(chan int, 1) 和 make (chan int) 的区别
遇到golang channel 的一个问题:发现go 协程读取channel 数据 并没有按照预期进行协作执行. 经过查资料: 使用channel 操作不当导致,channel分 有缓冲区 和 无缓冲区 , 以下是两者的区别. 无缓冲区channel 用make(chan int) 创建的chan, 是无缓冲区的, send 数据到chan 时,在没有协程取出数据的情况下, 会阻塞当前协程的运行.ch <- 后面的代码就不会再运行,直到channel 的数据被接收,当前协程才会继续往下执行.