浅谈MySQL排序原理与案例分析
前言
排序是数据库中的一个基本功能,MySQL也不例外。用户通过Order by语句即能达到将指定的结果集排序的目的,其实不仅仅是Order by语句,Group by语句,Distinct语句都会隐含使用排序。本文首先会简单介绍SQL如何利用索引避免排序代价,然后会介绍MySQL实现排序的内部原理,并介绍与排序相关的参数,最后会给出几个“奇怪”排序例子,来谈谈排序一致性问题,并说明产生现象的本质原因。
1.排序优化与索引使用
为了优化SQL语句的排序性能,最好的情况是避免排序,合理利用索引是一个不错的方法。因为索引本身也是有序的,如果在需要排序的字段上面建立了合适的索引,那么就可以跳过排序的过程,提高SQL的查询速度。下面我通过一些典型的SQL来说明哪些SQL可以利用索引减少排序,哪些SQL不能。假设t1表存在索引key1(key_part1,key_part2),key2(key2)
a.可以利用索引避免排序的SQL
SELECT * FROM t1 ORDER BY key_part1,key_part2; SELECT * FROM t1 WHERE key_part1 = constant ORDER BY key_part2; SELECT * FROM t1 WHERE key_part1 > constant ORDER BY key_part1 ASC; SELECT * FROM t1 WHERE key_part1 = constant1 AND key_part2 > constant2 ORDER BY key_part2;
b.不能利用索引避免排序的SQL
//排序字段在多个索引中,无法使用索引排序 SELECT * FROM t1 ORDER BY key_part1,key_part2, key2; //排序键顺序与索引中列顺序不一致,无法使用索引排序 SELECT * FROM t1 ORDER BY key_part2, key_part1; //升降序不一致,无法使用索引排序 SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC; //key_part1是范围查询,key_part2无法使用索引排序 SELECT * FROM t1 WHERE key_part1> constant ORDER BY key_part2;
2.排序实现的算法
对于不能利用索引避免排序的SQL,数据库不得不自己实现排序功能以满足用户需求,此时SQL的执行计划中会出现“Using filesort”,这里需要注意的是filesort并不意味着就是文件排序,其实也有可能是内存排序,这个主要由sort_buffer_size参数与结果集大小确定。MySQL内部实现排序主要有3种方式,常规排序,优化排序和优先队列排序,主要涉及3种排序算法:快速排序、归并排序和堆排序。假设表结构和SQL语句如下:
CREATE TABLE t1(id int, col1 varchar(64), col2 varchar(64), col3 varchar(64), PRIMARY KEY(id),key(col1,col2)); SELECT col1,col2,col3 FROM t1 WHERE col1>100 ORDER BY col2;
a.常规排序
(1).从表t1中获取满足WHERE条件的记录
(2).对于每条记录,将记录的主键+排序键(id,col2)取出放入sort buffer
(3).如果sort buffer可以存放所有满足条件的(id,col2)对,则进行排序;否则sort buffer满后,进行排序并固化到临时文件中。(排序算法采用的是快速排序算法)
(4).若排序中产生了临时文件,需要利用归并排序算法,保证临时文件中记录是有序的
(5).循环执行上述过程,直到所有满足条件的记录全部参与排序
(6).扫描排好序的(id,col2)对,并利用id去捞取SELECT需要返回的列(col1,col2,col3)
(7).将获取的结果集返回给用户。
从上述流程来看,是否使用文件排序主要看sort buffer是否能容下需要排序的(id,col2)对,这个buffer的大小由sort_buffer_size参数控制。此外一次排序需要两次IO,一次是捞(id,col2),第二次是捞(col1,col2,col3),由于返回的结果集是按col2排序,因此id是乱序的,通过乱序的id去捞(col1,col2,col3)时会产生大量的随机IO。对于第二次MySQL本身一个优化,即在捞之前首先将id排序,并放入缓冲区,这个缓存区大小由参数read_rnd_buffer_size控制,然后有序去捞记录,将随机IO转为顺序IO。
b.优化排序
常规排序方式除了排序本身,还需要额外两次IO。优化的排序方式相对于常规排序,减少了第二次IO。主要区别在于,放入sort buffer不是(id,col2),而是(col1,col2,col3)。由于sort buffer中包含了查询需要的所有字段,因此排序完成后可以直接返回,无需二次捞数据。这种方式的代价在于,同样大小的sort buffer,能存放的(col1,col2,col3)数目要小于(id,col2),如果sort buffer不够大,可能导致需要写临时文件,造成额外的IO。当然MySQL提供了参数max_length_for_sort_data,只有当排序元组小于max_length_for_sort_data时,才能利用优化排序方式,否则只能用常规排序方式。
c.优先队列排序
为了得到最终的排序结果,无论怎样,我们都需要将所有满足条件的记录进行排序才能返回。那么相对于优化排序方式,是否还有优化空间呢?5.6版本针对Order by limit M,N语句,在空间层面做了优化,加入了一种新的排序方式--优先队列,这种方式采用堆排序实现。堆排序算法特征正好可以解limit M,N 这类排序的问题,虽然仍然需要所有元素参与排序,但是只需要M+N个元组的sort buffer空间即可,对于M,N很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。对于升序,采用大顶堆,最终堆中的元素组成了最小的N个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素。
3.排序不一致问题
案例1
Mysql从5.5迁移到5.6以后,发现分页出现了重复值。
测试表与数据:
create table t1(id int primary key, c1 int, c2 varchar(128)); insert into t1 values(1,1,'a'); insert into t1 values(2,2,'b'); insert into t1 values(3,2,'c'); insert into t1 values(4,2,'d'); insert into t1 values(5,3,'e'); insert into t1 values(6,4,'f'); insert into t1 values(7,5,'g');
假设每页3条记录,第一页limit 0,3和第二页limit 3,3查询结果如下:

我们可以看到 id为4的这条记录居然同时出现在两次查询中,这明显是不符合预期的,而且在5.5版本中没有这个问题。产生这个现象的原因就是5.6针对limit M,N的语句采用了优先队列,而优先队列采用堆实现,比如上述的例子order by c1 asc limit 0,3 需要采用大小为3的大顶堆;limit 3,3需要采用大小为6的大顶堆。由于c1为2的记录有3条,而堆排序是非稳定的(对于相同的key值,无法保证排序后与排序前的位置一致),所以导致分页重复的现象。为了避免这个问题,我们可以在排序中加上唯一值,比如主键id,这样由于id是唯一的,确保参与排序的key值不相同。将SQL写成如下:
select * from t1 order by c1,id asc limit 0,3; select * from t1 order by c1,id asc limit 3,3;
案例2
两个类似的查询语句,除了返回列不同,其它都相同,但排序的结果不一致。
测试表与数据:
create table t2(id int primary key, status int, c1 varchar(255),c2 varchar(255),c3 varchar(255),key(c1));
insert into t2 values(7,1,'a',repeat('a',255),repeat('a',255));
insert into t2 values(6,2,'b',repeat('a',255),repeat('a',255));
insert into t2 values(5,2,'c',repeat('a',255),repeat('a',255));
insert into t2 values(4,2,'a',repeat('a',255),repeat('a',255));
insert into t2 values(3,3,'b',repeat('a',255),repeat('a',255));
insert into t2 values(2,4,'c',repeat('a',255),repeat('a',255));
insert into t2 values(1,5,'a',repeat('a',255),repeat('a',255));
分别执行SQL语句:
select id,status,c1,c2 from t2 force index(c1) where c1>='b' order by status; select id,status from t2 force index(c1) where c1>='b' order by status;
执行结果如下:
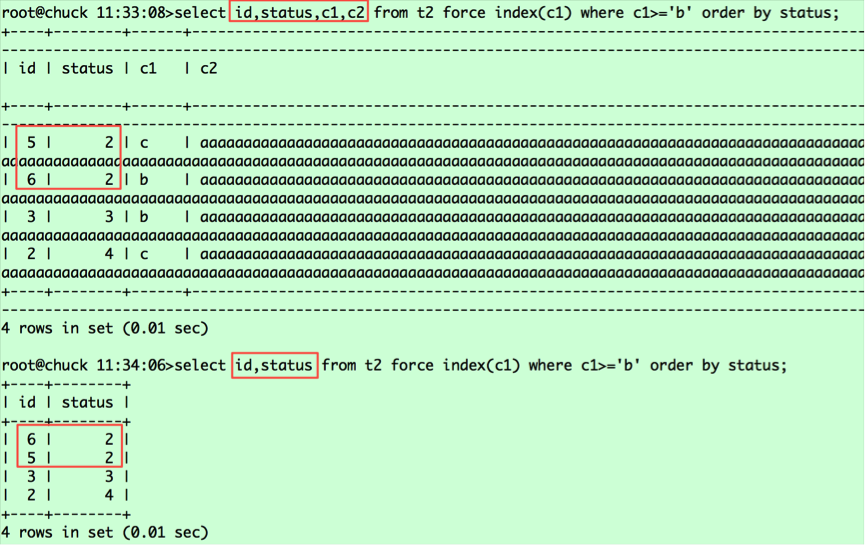
看看两者的执行计划是否相同

为了说明问题,我在语句中加了force index的hint,确保能走上c1列索引。语句通过c1列索引捞取id,然后去表中捞取返回的列。根据c1列值的大小,记录在c1索引中的相对位置如下:
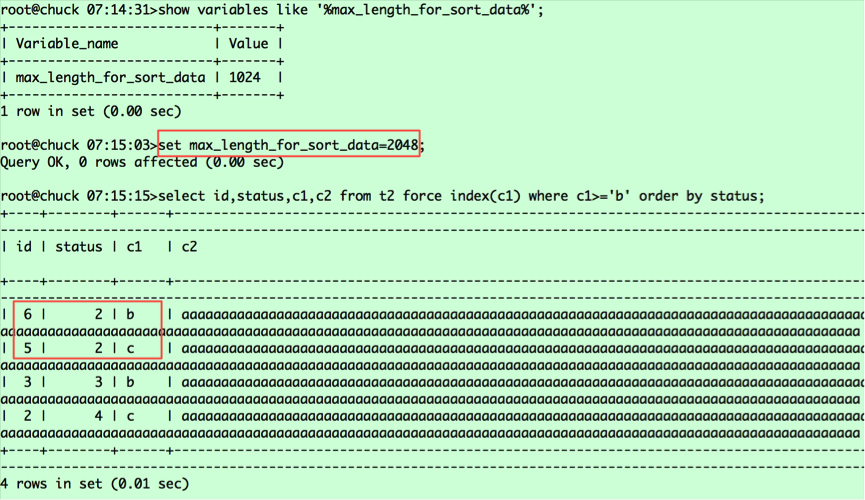
(c1,id)===(b,6),(b,3),(5,c),(c,2),对应的status值分别为2 3 2 4。从表中捞取数据并按status排序,则相对位置变为(6,2,b),(5,2,c),(3,3,c),(2,4,c),这就是第二条语句查询返回的结果,那么为什么第一条查询语句(6,2,b),(5,2,c)是调换顺序的呢?这里要看我之前提到的a.常规排序和b.优化排序中标红的部分,就可以明白原因了。由于第一条查询返回的列的字节数超过了max_length_for_sort_data,导致排序采用的是常规排序,而在这种情况下MYSQL将rowid排序,将随机IO转为顺序IO,所以返回的是5在前,6在后;而第二条查询采用的是优化排序,没有第二次捞取数据的过程,保持了排序后记录的相对位置。对于第一条语句,若想采用优化排序,我们将max_length_for_sort_data设置调大即可,比如2048。
下面是本人关于mysql 自定义排序(field,INSTR,locate)的一点心得,希望对大家有所帮助
首先说明这里有三个函数(order by field,ORDER BY INSTR,ORDER BY locate)
原表:
id user pass aaa aaa bbb bbb ccc ccc ddd ddd eee eee fff fff
下面是我执行后的结果:
SELECT * FROM `user` order by field(2,3,5,4,id) asc
id user pass aaa aaa ccc ccc ddd ddd eee eee fff fff bbb bbb
根据结果分析:order by field(2,3,5,4,1,6) 结果显示顺序为:1 3 4 5 6 2
SELECT * FROM `user` order by field(2,3,5,4,id) desc
id user pass bbb bbb aaa aaa ccc ccc ddd ddd eee eee fff fff
根据结果分析:order by field(2,3,5,4,1,6) 结果显示顺序为:2 1 3 4 5 6
SELECT * FROM `user` ORDER BY INSTR( '2,3,5,4', id ) ASC
id user pass aaa aaa fff fff bbb bbb ccc ccc eee eee ddd ddd
根据结果分析:order by INSTR(2,3,5,4,1,6) 结果显示顺序为:1 6 2 3 5 4
SELECT * FROM `user` ORDER BY INSTR( '2,3,5,4', id ) DESC
id user pass ddd ddd eee eee ccc ccc bbb bbb aaa aaa fff fff
根据结果分析:order by INSTR(2,3,5,4,1,6) 结果显示顺序为:4 5 3 2 1 6
SELECT * FROM `user` ORDER BY locate( id, '2,3,5,4' ) ASC
id user pass
aaa aaa fff fff bbb bbb ccc ccc eee eee ddd ddd
根据结果分析:order by locate(2,3,5,4,1,6) 结果显示顺序为:1 6 2 3 5 4
SELECT * FROM `user` ORDER BY locate( id, '2,3,5,4' ) DESC
id user pass ddd ddd eee eee ccc ccc bbb bbb aaa aaa fff fff
根据结果分析:order by locate(2,3,5,4,1,6) 结果显示顺序为:4 5 3 2 1 6
如我想要查找的数据库中的ID顺序首先是(2,3,5,4)然后在是其它的ID顺序,你首先要把他降序排即(4 5 3 2),然后在 SELECT * FROM `user` ORDER BY INSTR( '4,5,3,2', id ) DESC limit 0,10 或用 SELECT * FROM `user` ORDER BY locate( id, '4,5,3,2' ) DESC 就得到你想要的结果了。
id user pass bbb bbb ccc ccc eee eee ddd ddd aaa aaa fff fff
相关推荐
-
MYSQL 关于两个经纬度之间的距离由近及远排序
复制代码 代码如下: select *,(2 * 6378.137* ASIN(SQRT(POW(SIN(PI()*(111.86141967773438-lat)/360),2)+COS(PI()*33.07078170776367/180)* COS(lat * PI()/180)*POW(SIN(PI()*(33.07078170776367-lng)/360),2)))) as juli from `area` order by juli asc limit 0,20 差不多就是这样的
-
Mysql select in 按id排序实现方法
表结构如下: mysql> select * from test; +----+-------+ | id | name | +----+-------+ | 1 | test1 | | 2 | test2 | | 3 | test3 | | 4 | test4 | | 5 | test5 | +----+-------+ 执行以下SQL: mysql> select * from test where id in(3,1,5); +----+-------+ | id | name | +-
-
mysql如何根据汉字首字母排序
复制代码 代码如下: select areaName from area order by convert(areaName USING gbk) COLLATE gbk_chinese_ci asc 说明:areaName为列名 area为表名 PS:这里再为大家推荐一款本站的相关在线工具供大家参考: 在线中英文根据首字母排序工具: http://tools.jb51.net/aideddesign/zh_paixu
-
MySQL中按照多字段排序及问题解决
因为在做一个项目需要筛选掉一部分产品列表中的产品,使其在列表显示时排在最后,但是所有产品都要按照更新时间排序. 研究了一下系统的数据库结构后,决定将要排除到后面的产品加为粗体,这样在数据库中的"ifbold"就会被标记为1,而其他产品就默认标记为0,然后就打算使用MySQL在Order By时进行多字段排序. Order by的多条件分割一般使用英文逗号分割,所以我测试的SQL如下: 复制代码 代码如下: select * from {P}_product_con where $scl
-
让MySQL支持中文排序的实现方法
让MySQL支持中文排序 编绎MySQL时一般以ISO-8859字符集作为默认的字符集,因此在比较过程中中文编码字符大小写转换造成了这种现象,一种解决方法是对于包含中文的字段加上"binary"属性,使之作为二进制比较,例如将"name char(10)"改成"name char(10)binary". 编译MySQL时使用--with--charset=gbk 参数,这样MySQL就会直接支持中文查找和排序了. mysql order by 中
-
Mysql中的排序规则utf8_unicode_ci、utf8_general_ci的区别总结
用了这么长时间,发现自己竟然不知道utf_bin和utf_general_ci这两者到底有什么区别.. ci是 case insensitive, 即 "大小写不敏感", a 和 A 会在字符判断中会被当做一样的; bin 是二进制, a 和 A 会别区别对待. 例如你运行: SELECT * FROM table WHERE txt = 'a' 那么在utf8_bin中你就找不到 txt = 'A' 的那一行, 而 utf8_general_ci 则可以. utf8_general_
-
mysql的中文数据按拼音排序的2个方法
客服那边需要我对一些酒店进行中文拼音排序,以前没有接触过,在php群里问了一些大牛..得到了2种答案,都可以.哈哈·~ 以下既是msyql 例子,表结构是utf-8的 方法一. 复制代码 代码如下: SELECT `hotel_name` FROM `hotel_base` ORDER BY convert( `hotel_name` USING gbk ) COLLATE gbk_chinese_ci 方法二. 复制代码 代码如下: SELECT `hotel_id` , `hotel_nam
-

浅谈MySQL排序原理与案例分析
前言 排序是数据库中的一个基本功能,MySQL也不例外.用户通过Order by语句即能达到将指定的结果集排序的目的,其实不仅仅是Order by语句,Group by语句,Distinct语句都会隐含使用排序.本文首先会简单介绍SQL如何利用索引避免排序代价,然后会介绍MySQL实现排序的内部原理,并介绍与排序相关的参数,最后会给出几个"奇怪"排序例子,来谈谈排序一致性问题,并说明产生现象的本质原因. 1.排序优化与索引使用 为了优化SQL语句的排序性能,最好的情况是避免排序,合理利
-
MySQL排序原理和案例详析
前言 排序是数据库中的一个基本功能,MySQL也不例外.用户通过Order by语句即能达到将指定的结果集排序的目的,其实不仅仅是Order by语句,Group by语句,Distinct语句都会隐含使用排序.本文首先会简单介绍SQL如何利用索引避免排序代价,然后会介绍MySQL实现排序的内部原理,并介绍与排序相关的参数,最后会给出几个"奇怪"排序例子,来谈谈排序一致性问题,并说明产生现象的本质原因. 1.排序优化与索引使用 为了优化SQL语句的排序性能,最好的情况是避免排序,合理利
-
浅谈MySQL和Lucene索引的对比分析
MySQL和Lucene都可以对数据构建索引并通过索引查询数据,一个是关系型数据库,一个是构建搜索引擎(Solr.ElasticSearch)的核心类库.两者的索引(index)有什么区别呢?以前写过一篇<Solr与MySQL查询性能对比>,只是简单的对比了下查询性能,对于内部原理却没有解释,本文简单分析下两者的索引区别. MySQL索引实现 在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式. M
-
浅谈MySQL使用笛卡尔积原理进行多表查询
MySQL的多表查询(笛卡尔积原理) 先确定数据要用到哪些表. 将多个表先通过笛卡尔积变成一个表. 然后去除不符合逻辑的数据(根据两个表的关系去掉). 最后当做是一个虚拟表一样来加上条件即可. 注意:列名最好使用表别名来区别. 笛卡尔积 Demo: 左,右连接,内,外连接 l 内连接: 要点:返回的是所有匹配的记录. select * from a,b where a.x = b.x ////内连接 l 外连接有左连接和右连接两种. 要点:返回的是所有匹配的记录 外加 每行主表外键值为null的
-
浅谈MySQL之浅入深出页原理
一.页的概览 我们往 MySQL 插入的数据最终都是存在页中的.在 InnoDB 中的设计中,页与页之间是通过一个双向链表连接起来. 而存储在页中的一行一行的数据则是通过单链表连接起来的. 上图中的 User Records 的区域就是用来存储行数据的.那 InnoDB 为什么要这么设计?假设我们没有页这个概念,那么当我们查询时,成千上万的数据要如何做到快速的查询出结果?众所周知,MySQL 的性能是不错的,而如果没有页,我们剩下的只能是逐条逐条的遍历数据了. 那页是如何做到快速查询的呢?在当前
-
浅谈MySQL中group_concat()函数的排序方法
group_concat()函数的参数是可以直接使用order by排序的.666.. 下面通过例子来说明,首先看下面的t1表. 比如,我们要查看每个人的多个分数,将该人对应的多个分数显示在一起,分数要从高到底排序. 可以这样写: SELECT username,GROUP_CONCAT(score ORDER BY score DESC) AS myScore FROM t1 GROUP BY username; 效果如下: 以上这篇浅谈MySQL中group_concat()函数的排序方法就
-
浅谈mysql join底层原理
目录 join算法 驱动表和非驱动表的区别 1.Simple Nested-Loop Join,简单嵌套-无索引的情况 2.Index Nested-Loop Join-有索引的情况 3.Block Nested-Loop Join ,join buffer缓冲区 缓冲区大小 数据量大的表和数据量小的表如何选择连接顺序 细节 join算法 mysql只支持一种join算法:Nested-Loop Join(嵌套循环连接),但Nested-Loop Join有三种变种: Simple Nested
-
浅谈MYSQL中树形结构表3种设计优劣分析与分享
目录 简介 问题 设计1:邻接表 表设计 SQL示例 设计2:路径枚举 表设计 SQL示例 设计3:闭包表 表设计 SQL示例 结合使用 表设计 总结 简介 在开发中经常遇到树形结构的场景,本文将以部门表为例对比几种设计的优缺点: 问题 需求背景:根据部门检索人员, 问题:选择一个顶级部门情况下,跨级展示当前部门以及子部门下的所有人员,表怎么设计更合理 ? 递归吗 ?递归可以解决,但是势必消耗性能 设计1:邻接表 注:(常见父Id设计) 表设计 CREATE TABLE `dept_info01
-
浅谈MySQL与redis缓存的同步方案
本文介绍MySQL与Redis缓存的同步的两种方案 方案1:通过MySQL自动同步刷新Redis,MySQL触发器+UDF函数实现 方案2:解析MySQL的binlog实现,将数据库中的数据同步到Redis 一.方案1(UDF) 场景分析:当我们对MySQL数据库进行数据操作时,同时将相应的数据同步到Redis中,同步到Redis之后,查询的操作就从Redis中查找 过程大致如下: 在MySQL中对要操作的数据设置触发器Trigger,监听操作 客户端(NodeServer)向MySQL中写入数
-
浅谈mysql的索引设计原则以及常见索引的区别
索引定义:是一个单独的,存储在磁盘上的数据库结构,其包含着对数据表里所有记录的引用指针. 数据库索引的设计原则: 为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引. 那么索引设计原则又是怎样的? 1.选择唯一性索引 唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录. 例如,学生表中学号是具有唯一性的字段.为该字段建立唯一性索引可以很快的确定某个学生的信息. 如果使用姓名的话,可能存在同名现象,从而降低查询速度. 2.为经常需要排序.分组和联合操