精确查找PHP WEBSHELL木马 修正版
先来看下反引号可以成功执行命名的代码片段。代码如下:
代码如下:
`ls -al`;
`ls -al`;
echo "sss"; `ls -al`;
$sql = "SELECT `username` FROM `table` WHERE 1";
$sql = 'SELECT `username` FROM `table` WHERE 1'
/*
无非是 前面有空白字符,或者在一行代码的结束之后,后面接着写,下面两行为意外情况,也就是SQL命令里的反引号,要排除的就是它。
*/
正则表达式该如何写?
分析:
对于可移植性的部分共同点是什么?与其他正常的包含反引号的部分,区别是什么?
他们前面可以有空格,tab键等空白字符。也可以有程序代码,前提是如果有引号(单双)必须是闭合的。才是危险有隐患的。遂CFC4N给出的正则如下:【(?:(?:^(?:\s+)?)|(?:(?P<quote>["'])[^(?P=quote)]+?(?P=quote)[^`]*?))`(?P<shell>[^`]+)`】。
解释一下:
【(?:(?:^(?:\s+)?)|(?:(?P<quote>["'])[^(?P=quote)]+?(?P=quote)[^`]*?))】匹配开始位置或者开始位置之后有空白字符或者前面有代码,且代码有闭合的单双引号。(这段PYTHON的正则中用了捕获命名以及反向引用)
【`(?P<shell>[^`]+)`】这个就比较简单了,匹配反引号中间的字符串。 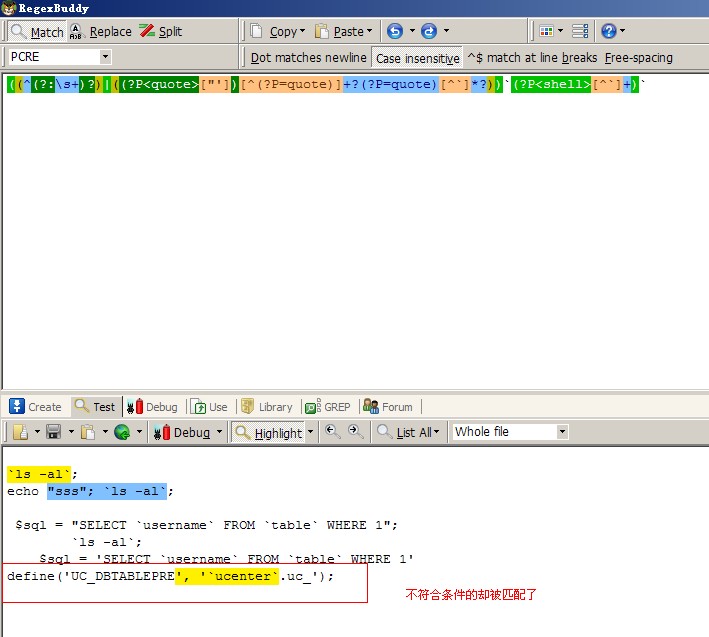
python脚本检测PHP WEBSHELL
然后我将这段代码写入程序中,测试跑了一下discuz的程序。结果有一个误报。误报的位置为“config.inc.php”中的“define(‘UC_DBTABLEPRE', ‘`ucenter`.uc_');”,什么原因造成的?这行代码符合了前面有闭合的引号,也有反引号的使用,所以,符合要求,被检测到了。如何再排除这种情况呢?这个有什么特殊的?前面有逗号“,”?如果是字符串连接的点号“.”呢?再排除逗号?
好吧,我错了,我不该用我的思维来误导你。换个思路。找下反引号可执行的代码的前面字符串的情况,他们只能是行的开始,或者有空白字符(包括空格,tab键等),再前面也可以有代码的结束标识分号“;”,其他的情况,都是不可以执行的吧?嗯,应该是这样。(如有错误,欢迎斧正)既然思路有了,那正则代码更好写了。如下【(^|(?<=;))\s*`[^`]+`】,解释一下,【(^|(?<=;))】匹配位置,是行的开始,或者前面有分号“;”。【\s*`[^`]+`】空白字符任一个,然后是….(你懂的)。OK,写好之后,检测,又发现一个问题。 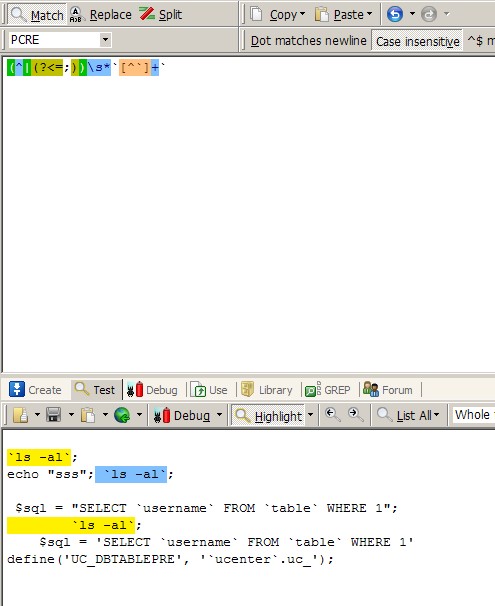
匹配引入文件的正则也匹配了“require_once ‘./include/db_'.$database.'.class.php';”这种代码,什么原因造成的,您自己分析吧。
给出修复之后的python代码,如下:
代码如下:
#!/usr/bin/python
#-*- encoding:UTF-8 -*-
###
## @package
##
## @author CFC4N <cfc4nphp@gmail.com>
## @copyright copyright (c) Www.cnxct.Com
## @Version $Id: check_php_shell.py 37 2010-07-22 09:56:28Z cfc4n $
###
import os
import sys
import re
import time
def listdir(dirs,liston='0'):
flog = open(os.getcwd()+"/check_php_shell.log","a+")
if not os.path.isdir(dirs):
print "directory %s is not exist"% (dirs)
return
lists = os.listdir(dirs)
for list in lists:
filepath = os.path.join(dirs,list)
if os.path.isdir(filepath):
if liston == '1':
listdir(filepath,'1')
elif os.path.isfile(filepath):
filename = os.path.basename(filepath)
if re.search(r"\.(?:php|inc|html?)$", filename, re.IGNORECASE):
i = 0
iname = 0
f = open(filepath)
while f:
file_contents = f.readline()
if not file_contents:
break
i += 1
match = re.search(r'''(?P<function>\b(?:include|require)(?:_once)?\b)\s*\(?\s*["'](?P<filename>[^;]*(?<!\.(?:php|inc)))["']\)?\s*;''', file_contents, re.IGNORECASE| re.MULTILINE)
if match:
function = match.group("function")
filename = match.group("filename")
if iname == 0:
info = '\n[%s] :\n'% (filepath)
else:
info = ''
info += '\t|-- [%s] - [%s] line [%d] \n'% (function,filename,i)
flog.write(info)
print info
iname += 1
match = re.search(r'\b(?P<function>eval|proc_open|popen|shell_exec|exec|passthru|system)\b\s*\(', file_contents, re.IGNORECASE| re.MULTILINE)
if match:
function = match.group("function")
if iname == 0:
info = '\n[%s] :\n'% (filepath)
else:
info = ''
info += '\t|-- [%s] line [%d] \n'% (function,i)
flog.write(info)
print info
iname += 1
match = re.search(r'(^|(?<=;))\s*`(?P<shell>[^`]+)`\s*;', file_contents, re.IGNORECASE)
if match:
shell = match.group("shell")
if iname == 0:
info = '\n[%s] :\n'% (filepath)
else:
info = ''
info += '\t|-- [``] command is [%s] in line [%d] \n'% (shell,i)
flog.write(info)
print info
iname += 1
f.close()
flog.close()
if '__main__' == __name__:
argvnum = len(sys.argv)
liston = '0'
if argvnum == 1:
action = os.path.basename(sys.argv[0])
print "Command is like:\n %s D:\wwwroot\ \n %s D:\wwwroot\ 1 -- recurse subfolders"% (action,action)
quit()
elif argvnum == 2:
path = os.path.realpath(sys.argv[1])
listdir(path,liston)
else:
liston = sys.argv[2]
path = os.path.realpath(sys.argv[1])
listdir(path,liston)
flog = open(os.getcwd()+"/check_php_shell.log","a+")
ISOTIMEFORMAT='%Y-%m-%d %X'
now_time = time.strftime(ISOTIMEFORMAT,time.localtime())
flog.write("\n----------------------%s checked ---------------------\n"% (now_time))
flog.close()
稍微检测了一下Discuz7.2的代码,还是有误报的,误报的为这种包含sql的代码:
代码如下:
$query = $db->query("SELECT `status`,`threads`,`posts`
FROM `{$tablepre}forums` WHERE
`status`='1';
");
稍微检测了一下Discuz7.2的代码,还是有误报的,误报的为这种包含sql的代码:
代码如下:
$query = $db->query("SELECT `status`,`threads`,`posts`
FROM `{$tablepre}forums` WHERE
`status`='1';
");
由于这个脚本是按照一行一行的代码来处理的,所以,有这种误报。您自己去修复吧。相对网上流传的脚本来说,还是比较准确的。
欢迎转载。转载请注明来源,以及留下博客链接,同时,不能用于商业用途。(已经修复,增加了反引号后面【\s*;】的判断。2010-07-27 17:06)
PS:如果说上传文件也算是危险的、值得注意的操作的话,建议加上move_uploaded_file函数的检测。你知道在哪里加的。^_^
2010-12-17 关于这些代码,已经放到google 的代码托管上了。SVN地址为 http://code.google.com/p/cnxct/ 大家个获得最新版。
我是一个PHPer,写的python有点憋,有点懒,还请各位安全界的大牛,程序界的前辈不要鄙视,要给建议,谢谢。php版的以后在写吧。同时,也欢迎各位安全爱好者反馈最新的web shell特征代码,我尽力增加到程序中区。
完整的代码
代码如下:
#!/usr/bin/python
#-*- encoding:UTF-8 -*-
###
## @package
##
## @author CFC4N <cfc4nphp@gmail.com>
## @copyright copyright (c) Www.cnxct.Com
## @Version $Id$
###
import os
import sys
import re
import time
def listdir(dirs,liston='0'):
flog = open(os.getcwd()+"/check_php_shell.log","a+")
if not os.path.isdir(dirs):
print "directory %s is not exist"% (dirs)
return
lists = os.listdir(dirs)
for list in lists:
filepath = os.path.join(dirs,list)
if os.path.isdir(filepath):
if liston == '1':
listdir(filepath,'1')
elif os.path.isfile(filepath):
filename = os.path.basename(filepath)
if re.search(r"\.(?:php|inc|html?)$", filename, re.IGNORECASE):
i = 0
iname = 0
f = open(filepath)
while f:
file_contents = f.readline()
if not file_contents:
break
i += 1
match = re.search(r'''(?P<function>\b(?:include|require)(?:_once)?\b)\s*\(?\s*["'](?P<filename>[^;]*(?<!\.(?:php|inc)))["']\)?\s*;''', file_contents, re.IGNORECASE| re.MULTILINE)
if match:
function = match.group("function")
filename = match.group("filename")
if iname == 0:
info = '\n[%s] :\n'% (filepath)
else:
info = ''
info += '\t|-- [%s] - [%s] line [%d] \n'% (function,filename,i)
flog.write(info)
print info
iname += 1
match = re.search(r'\b(?P<function>eval|proc_open|popen|shell_exec|exec|passthru|system|assert|fwrite|create_function)\b\s*\(', file_contents, re.IGNORECASE| re.MULTILINE)
if match:
function = match.group("function")
if iname == 0:
info = '\n[%s] :\n'% (filepath)
else:
info = ''
info += '\t|-- [%s] line [%d] \n'% (function,i)
flog.write(info)
print info
iname += 1
match = re.search(r'(^|(?<=;))\s*`(?P<shell>[^`]+)`\s*;', file_contents, re.IGNORECASE)
if match:
shell = match.group("shell")
if iname == 0:
info = '\n[%s] :\n'% (filepath)
else:
info = ''
info += '\t|-- [``] command is [%s] in line [%d] \n'% (shell,i)
flog.write(info)
print info
iname += 1
match = re.search(r'(?P<shell>\$_(?:POS|GE|REQUES)T)\s*\[[^\]]+\]\s*\(', file_contents, re.IGNORECASE)
if match:
shell = match.group("shell")
if iname == 0:
info = '\n[%s] :\n'% (filepath)
else:
info = ''
info += '\t|-- [``] command is [%s] in line [%d] \n'% (shell,i)
flog.write(info)
print info
iname += 1
f.close()
flog.close()
if '__main__' == __name__:
argvnum = len(sys.argv)
liston = '0'
if argvnum == 1:
action = os.path.basename(sys.argv[0])
print "Command is like:\n %s D:\wwwroot\ \n %s D:\wwwroot\ 1 -- recurse subfolders"% (action,action)
quit()
elif argvnum == 2:
path = os.path.realpath(sys.argv[1])
listdir(path,liston)
else:
liston = sys.argv[2]
path = os.path.realpath(sys.argv[1])
listdir(path,liston)
flog = open(os.getcwd()+"/check_php_shell.log","a+")
ISOTIMEFORMAT='%Y-%m-%d %X'
now_time = time.strftime(ISOTIMEFORMAT,time.localtime())
flog.write("\n----------------------%s checked ---------------------\n"% (now_time))
flog.close()
相关推荐
-
php网站被挂木马后的修复方法总结
本文实例总结了php网站被挂木马后的修复方法.分享给大家供大家参考.具体方法如下: 在linux中我们可以使用命令来搜查木马文件,到代码安装目录执行下面命令 复制代码 代码如下: find ./ -iname "*.php" | xargs grep -H -n "eval(base64_decode" 搜出来接近100条结果,这个结果列表很重要,木马都在里面,要一个一个文件打开验证是否是木马,如果是,马上删除掉 最后找到10个木马文件,存放在各种目录,都是php
-

精确查找PHP WEBSHELL木马的方法(1)
先来看下反引号可以成功执行命名的代码片段.代码如下: 复制代码 代码如下: `ls -al`; `ls -al`; echo "sss"; `ls -al`; $sql = "SELECT `username` FROM `table` WHERE 1"; $sql = 'SELECT `username` FROM `table` WHERE 1' /* 无非是 前面有空白字符,或者在一行代码的结束之后,后面接着写,下面两行为意外情况,也就是SQL命令里的反引号,
-
PHP Web木马扫描器代码分享
不废话了,直接贴代码了. 代码如下: <?php header('content-type:text/html;charset=gbk'); set_time_limit(0);//防止超时 /** * * php目录扫描监控增强版 * * @version 1.0 * 下面几个变量使用前需要手动设置 * **/ /*===================== 程序配置 =====================*/ $pass="test";//设置密码 $jkdir=&quo
-
php 木马的分析(加密破解)
分析可以知道,此木马经过了base64进行了编码,然后进行压缩.虽然做了相关的保密措施,可是php代码要执行,其最终要生成php源代码,所以写出如下php程序对其进行解码,解压缩,写入文件.解码解压缩代码如下: 复制代码 代码如下: <?php function writetofile($filename, $data) { //File Writing $filenum=@fopen($filename,"w"); if (!$filenum) { return false;
-
php检测图片木马多进制编程实践
前不久,我申请加入了某开源组织,他们要我写一个功能用来检测图片中是否有木马脚本. 其实一开始我什么也不知道,只是后来在网上查了一些资料,找到的全是有制作图片木马的教程,并没有找到检测的程序. 经过几番思索之后,决定从制作原理来分析这种木马程序.这种木马程序是十六进制编码写的,我灵机一动,写了以下这个上传类.最终通过了组织测验.呵呵 现在把它拿出来给大家分享,有什么不好的地方,还请指正! anyon@139.com; 复制代码 代码如下: <?php /** +------------------
-
PHP实现webshell扫描文件木马的方法
本文实例讲述了PHP实现webshell扫描文件木马的方法.分享给大家供大家参考,具体如下: 可扫描 weevelyshell 生成 或加密的shell 及各种变异webshell 目前仅支持php 支持扫描 weevelyshell 生成 或加密的shell 支持扫描callback一句话shell 支持各种php大马 <!DOCTYPE html> <html> <head> <meta charset='gb2312'> <title>PH
-
PHP 木马攻击的防御设置方法
1.防止跳出web目录 首先修改httpd.conf,假如您只允许您的php脚本程式在web目录里操作,还能够修改httpd.conf文档限制php的操作路径.比如您的web目录是/usr/local/apache/htdocs,那么在httpd.conf里加上这么几行: php_admin_value open_basedir /usr/local/apache /htdocs 这样,假如脚本要读取/usr/local/apache/htdocs以外的文档将不会被允许,假如错误显示打开的话会提
-
一句话木马的原理及利用分析(asp,aspx,php,jsp)
一句话木马的适用环境: 1.服务器的来宾账户有写入权限 2.已知数据库地址且数据库格式为asa或asp 3.在数据库格式不为asp或asa的情况下,如果能将一句话插入到asp文件中也可 一句话木马的工作原理: "一句话木马"服务端(本地的html提交文件) 就是我们要用来插入到asp文件中的asp语句,(不仅仅是以asp为后缀的数据库文件),该语句将回为触发,接收入侵者通过客户端提交的数据,执行并完成相应的操作,服务端的代码内容为 <%execute request("
-
php木马webshell扫描器代码
复制代码 代码如下: <?php /* +--------------------------------------------------------------------------+ | Codz by indexphp Version:0.01 | | (c) 2009 indexphp | | http://www.indexphp.org | +--------------------------------------------------------------------
-
PHP Web木马扫描器代码 v1.0 安全测试工具
scanner.php 复制代码 代码如下: <?php /**************PHP Web木马扫描器************************/ /* [+] 作者: alibaba */ /* [+] QQ: 1499281192 */ /* [+] MSN: weeming21@hotmail.com */ /* [+] 首发: t00ls.net , 转载请注明t00ls */ /* [+] 版本: v1.0 */ /* [+] 功能: web版php木马扫描工具 */