最全的用正则批量去除Teleport Pro整站下载文件冗余代码
tppabs
html原文件中tppabs标记是Teleport Pro软件留下的标记。该软件是离线浏览器,下载完整个网页后,它会在图片或超级链接标签内插入tppabs标签,以记录该图片或超级链接指向的原始地址。因为这个标签不是合法标签,所以普通浏览器会忽略它。但可以通过element.getAttribute("tppabs")在JS中读取这个属性。
如我们手动清除的话,那将是一个无法估计的工作量,需要批量清除。利用DreamWeaver正则表达式批量清除tppabs标签更加容易、快捷。

方法如下:
使用DW替换功能:
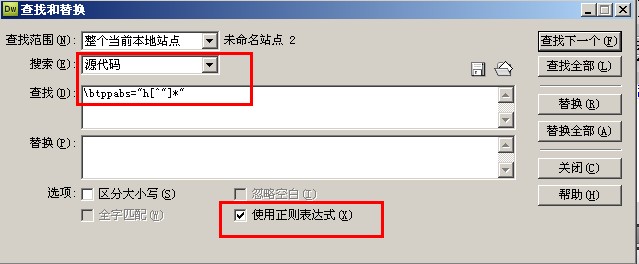
查找范围:整个当前本地站点
搜索:源代码
查找:\btppabs="h[^"]*"
替换:(为空)
勾选:使用正则表达式
点替换全部按钮即可
匹配javascript代码:
<a href="javascript: if(confirm('http://www.xxx.com \n\n文件并未依 Teleport Pro 取回,因为服务器报告错误导致无法读取。 \n\n你要从服务器上打开它吗?'))window.location='http: //www.xxx.com'" >
方法如下:
查找范围:整个当前本地站点
搜索:源代码
查找:href="javascript:if\(confirm\('htt[^"]*"
替换:href=www.xxx.com
勾选:使用正则表达式
点替换全部按钮
注:如果该表达式中含有不同的网址,可使用if\(confirm\('htt[^"]*\)(注意其他代码是否使用此类语法表达)匹配不带网址的部分,替换成空。
css文件有一些类似/*tpa=http://www.xxx.com/test.gif*/代码
方法如下:
查找范围:整个当前本地站点
搜索:源代码
查找:\/\*tpa=http://[^\s]*\/
替换:空
勾选:使用正则表达式
点替换全部按钮
| 字符 | 匹配 | 示例 |
| ^ | 输入或行的起始部分。 | ^T 匹配“This good earth”中的“T”,但不匹配“Uncle Tom's Cabin”中的“T”。 |
| $ | 输入或行的结尾部分。 | h$ 匹配“teach”中的“h”,但是不匹配“teacher”中的“h” |
| * | 0 个或多个前置字符。 | um* 匹配“rum”中的“um”、“yummy”中的“umm”以及“huge”中的“u” |
| + | 1 个或多个前置字符。 | um+ 匹配“rum”中的“um”和“yummy”中的“umm”,但在“huge”中没有任何匹配项 |
| ? | 前置字符最多出现一次(即,指示前置字符是可选的)。 | st?on 匹配“Johnson”中的“son”和“Johnston”中的“ston”,但在“Appleton”和“tension”中没有任何匹配项 |
| . | 除换行符外的任何单字符。 | .an 匹配短语“bran muffins can be tasty”中的“ran”和“can” |
| x|y | x 或 y。 | FF0000|0000FF 匹配 bgcolor=”#FF0000” 中的“FF0000”和 font color=”#0000FF” 中的“0000FF” |
| {n} | 恰好 n 个前置字符。 | o{2} 匹配“loom”中的“oo”和“mooooo”中的前两个“o”,但在“money”中没有任何匹配项 |
| {n,m} | 至少 n 个、至多 m 个前置字符。 | F{2,4} 匹配“#FF0000”中的“FF”和“#FFFFFF”中的前四个“F” |
| [abc] | 用括号括起来的字符中的任何一个字符。用连字符指定某一范围的字符(例如, [a-f] 等效于 [abcdef])。 | [e-g] 匹配“bed”中的“e”、“folly”中的“f”和“guard”中的“g” |
| [^abc] | 未在括号中括起来的任何字符。用连字符指定某一范围的字符(例如,[^a-f] 等效于[^abcdef])。 | [^aeiou] 最初匹配“orange”中“r”、“book”中的“b”和“eek!”中的“k” |
| \b | 词边界(例如空格或回车符)。 | \bb 匹配“book”中的“b”,但在“goober”和“snob”中没有任何匹配项 |
| \B | 词边界之外的任何内容。 | \Bb 匹配“goober”中的“b”,但在“book”中没有任何匹配项 |
| \d | 任何数字字符。等效于 [0-9]。 | \d 匹配“C3PO”中的“3”和“apartment 2G”中的“2” |
| \D | 任何非数字字符。等效于 [^0-9]。 | \D 匹配“900S”中的“S”和“Q45”中的“Q” |
| \f | 换页符。 | |
| \n | 换行符。 | |
| \r | 回车符。 | |
| \s | 任何单个空白字符,包括空格、制表符、换页符或换行符。 | \sbook 匹配“blue book”中的“book”,但在“notebook”中没有任何匹配项 |
| \S | 任何单个非空白字符。 | \Sbook 匹配“notebook”中的“book”,但在“blue book”中没有任何匹配项 |
| \t | 制表符。 | |
| \w | 任何字母数字字符,包括下划线。等效于 [A-Za-z0-9_]。 | b\w* 匹配“the barking dog”中的“barking”以及“the big black dog”中的“big”和“black” |
| \W | 任何非字母数字字符。等效于 [^A-Za-z0-9_]。 | \W 匹配“Jake&Mattie”中的 |
相关推荐
-
文件名 正则表达式提取方法
下面这段子程基本上可以算是比较不错的通用匹配了.(PS:我突然发现CODE_LITE把我的UBB转义了!!!晕,我只好自己转义了...) Dim objRegExp,Matches,i,DC9_DOT_CN_MATCH Dim aryMatch() Redim Preserve aryMatch(0) Set objRegExp=New RegExp objRegExp.IgnoreCase =True objRegExp.Global=True objRegExp.Pattern="(?:\[
-
shell脚本正则匹配文件中的Email并写入到文件中代码分享
代码如下: 复制代码 代码如下: #! /bin/bashfunction read_file(){ for line in `cat $1` do if [ `echo $line |grep "^[a-zA-Z0-9_-]*@[A-Za-z_-]*\.[a-zA-Z_-]*$"` ];then echo $line >> result.txt else echo "---&qu
-
Powershell学习笔记--使用正则表达式查找文件
支持所有PS版本 Get-ChildItem 不支持文件高级筛选.它只能使用简单的通配符,但不能使用正则表达式. 围绕这个问题,我们可以使用-match命令来筛选. 下面这个例子将获得所有windows目录下包含至少连续有两个数字的文件同时文件名长度不超过8个字符: Get-ChildItem -Path $env:windir -Recurse -ErrorAction SilentlyContinue | Where-Object { $_.BaseName -match '\d{2}' -
-
简单分析javascript面向对象与原型
本文主要内容参考来自JavaScript高级程序设计,面向对象与原型章节: 1.工厂模式 ECMAScript 可以通过工厂模式来创建对象: //工厂模式 function createObject(name, age) { var obj = new Object(); //创建对象 obj.name = name; //添加属性 obj.age = age; obj.run = function () { //添加方法 return this.name + this.age + '运行中..
-
FileUpload1 上传文件类型验证正则表达式
复制代码 代码如下: <asp:RegularExpressionValidator id="FileUpLoadValidator" runat="server" ErrorMessage="Upload Jpegs and Gifs only." ValidationExpression="^(([a-zA-Z]:)|(\\{2}\w+)\$?)(\\(\w[\w].*))(.jpg|.JPG|.gif|.GIF)
-
js 得到文件后缀(通过正则实现)
正则得到后缀 复制代码 代码如下: <script type="text/javascript"> function validate(){ //var importUrl= $("#importurl").val(); var importUrl="test.xlsx"; var d=/\.[^\.]+$/.exec(importUrl); alert(d); return false; } </script>
-
.NET读取所有目录下文件正则匹配文本电子邮件
复制代码 代码如下: using System; using System.Collections.Generic; using System.Text; using System.IO; using System.Text.RegularExpressions; namespace Test { class FiEmail { public static void Main(string[] args) { Console.WriteLine("请输入内容路径:"); string[
-
javascript 获取链接文件地址中第一个斜线内的正则表达式
window.location.pathname 比如: /windows/location/page.html 我想得到"windows",请问用正则表达式怎么写? var a="/windows/location/page.html"; var reg=/(^(http[s]?:\/\/[^\/]*\/)|(^\/))([^\/]+)\/.*$/ig; var t=a.replace(reg,"$4"); alert(a + "\n
-
用正则获取指定路径文件的名称
其中主要是涉及到"\"在javascript中的特殊字符,是不是要用到正规表达式 <script> var m="D:\图片\丐帮.jpg" //求解 </script> 希望能获取的值为"丐帮" 复制代码 代码如下: <script type="text/javascript"> var s ="D:\\图片\\丐帮.jpg"; var t = s.match(/\\(
-

最全的用正则批量去除Teleport Pro整站下载文件冗余代码
tppabs html原文件中tppabs标记是Teleport Pro软件留下的标记.该软件是离线浏览器,下载完整个网页后,它会在图片或超级链接标签内插入tppabs标签,以记录该图片或超级链接指向的原始地址.因为这个标签不是合法标签,所以普通浏览器会忽略它.但可以通过element.getAttribute("tppabs")在JS中读取这个属性. 如我们手动清除的话,那将是一个无法估计的工作量,需要批量清除.利用DreamWeaver正则表达式批量清除tppabs标签更加容易.快
-
PHP批量去除BOM头内容信息代码
什么是bom头? 在utf-8编码文件中BOM在文件头部,占用三个字节,用来标示该文件属于utf-8编码,现在已经有很多软件识别bom头,但是还有些不能识别bom头,比如PHP就不能识别bom头,这也是用记事本编辑utf-8编码后执行就会出错的原因了. 批量去除bom头代码如下所示: <?php if (isset($_GET['dir'])){ //设置文件目录 $basedir=$_GET['dir']; }else{ $basedir = '.'; } $auto = 1; checkdi
-
BAT批量去除文件首行以及批量合并文件脚本
bat批量去除文件首行 复制代码 代码如下: set n=1 :starline for %%j in (*.txt) do ( :3 if exist D:\work\test\new_%n%.txt (set /a n+=1&goto 3) set file=%n%.txt for /f "skip=1 delims=" %%i in ('type "%file%"') do ( echo %%i >>D:\work\test\new_%n%
-
批量去除PHP文件中bom的PHP代码
需要去除BOM,就把附件里的tool.php文件放到目标目录,然后在浏览器访问tool.php即可! 复制代码 代码如下: <?php //此文件用于快速测试UTF8编码的文件是不是加了BOM,并可自动移除 $basedir="."; //修改此行为需要检测的目录,点表示当前目录 $auto=1; //是否自动移除发现的BOM信息.1为是,0为否. //以下不用改动 if ($dh = opendir($basedir)) { while (($file = readdir($d
-
PHP基于正则批量替换Img中src内容实现获取缩略图的功能示例
本文实例讲述了PHP基于正则批量替换Img中src内容实现获取缩略图的功能.分享给大家供大家参考,具体如下: 这里PHP用正则批量替换Img中src内容,实现获取图片路径缩略图的功能 网上很多正则表达式只能获取或者替换一个img的src内容,或者只能替换固定的字符串,要动态替换多个图片内容的试了几个小时才解决. /** * 图片地址替换成压缩URL * @param string $content 内容 * @param string $suffix 后缀 */ function get_img
-
Vue 中批量下载文件并打包的示例代码
思路: 用 ajax 将文件下载, 然后用 jszip 压缩文件, 最后用 file-saver 生成文件 1. 准备工作 安装 3 个依赖: axios, jszip, file-saver yarn add axios yarn add jszip yarn add file-saver 2. 下载文件 import axios from 'axios' const getFile = url => { return new Promise((resolve, reject) => { a
-
java后台批量下载文件并压缩成zip下载的方法
本文实例为大家分享了java后台批量下载文件并压缩成zip下载的具体代码,供大家参考,具体内容如下 因项目需要,将服务器上的图片文件压缩打包zip,下载到本地桌面. 首先,前端js: function doQueryPic() { var picsDate = $("#picsDate").val(); var piceDate = $("#piceDate").val(); var picInst = $("#pic_inst").combot
-
python爬虫智能翻页批量下载文件的实例详解
python爬虫遇到爬取文件内容时,需要一页页的翻页爬取,这样很是麻烦,其实可以获取每个列表信息下的文件名和文件链接,让文件名和文件链接处理为列表,保存后下载,实现智能翻页批量下载文件,本文以以京客隆为例,批量下载文件,如财务资料,他的每一份报告都是一份pdf格式的文档.以此页面为目标,下载他每个分类的文件python爬虫实战之智能翻页批量下载文件. 1.引入库 import requests import pandas as pd from lxml import etree import r
-
Angular搜索 过滤 批量删除 添加 表单验证功能集锦(实例代码)
废话不多说了,直接给大家贴代码,具体代码如下所示: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <style> *{ margin: 0; padding: 0; } .sspan{ background: #28a54c; color: #fff; margi
-
使用python实现正则匹配检索远端FTP目录下的文件
遇到一个问题,需要正则匹配远端FTP目录下的文件,如果使用ftp客户端可以通过命令行很容易的做到这一点,但是暂时没有一个工具支持这样的需求,于是通过python对FTP的支持和对正则表达式的支持,写了这么一个简单的工具,用于使用正则表达式来匹配远端目录的文件. 代码如下 # coding=utf-8 ######################################################################### # File Name: reg_url.py #