MySql Sql 优化技巧分享
有天发现一个带inner join的sql 执行速度虽然不是很慢(0.1-0.2),但是没有达到理想速度。两个表关联,且关联的字段都是主键,查询的字段是唯一索引。
sql如下:
SELECT p_item_token.*, p_item.product_type FROM p_item_token INNER JOIN p_item ON p_item.itemid = p_item_token.itemid WHERE p_item_token.token ='db87a780427d4d02ba2bd49fac8xxx';
其中表 p_item_token 中 itemid 是主键, token 是唯一索引。 p_item 中itemid 是主键
按照理想速度,应该在0.03s左右正常。但实际为0.2左右,慢了不少。
直接 EXPLAIN 看计划
EXPLAIN SELECT p_item_token.*, p_item.product_type FROM p_item_token INNER JOIN p_item ON p_item.itemid = p_item_token.itemid WHERE p_item_token.token = 'db87a780427d4d02ba2bd49fac8xxx';
结果:

注意看上面大红框。p_item表中就是2w条数据,那这个就是全表扫描了。
不正常啊。
加个show warnings 看看。注意:有些情况下SHOW WARNINGS 会没有结果。我还不知道原因。建议用本地测试数据库运行。
EXPLAIN SELECT p_item_token.*, p_item.product_type FROM p_item_token INNER JOIN p_item ON p_item.itemid = p_item_token.itemid WHERE p_item_token.token = 'db87a780427d4d02ba2bd49fac8xxx'; SHOW WARNINGS;
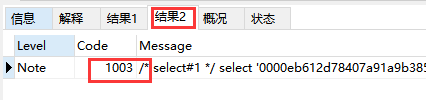
结果2里面显示code=1003.后面有个sql语句。这个语句就是mysql把我们输入的sql语句,按照规则改写之后执行的最终语句。
/* select#1 */
SELECT
'0000eb612d78407a91a9b3854ffffffff' AS `itemid`, /*注:直接按主键把值查出来了*/
'db87a780427d4d02ba2bd49fac8cf98b' AS `token`,
'2016-12-16 10:46:53' AS `create_time`,
'' AS `ftoken`,
`p_db`.`p_item`.`product_type` AS `product_type`
FROM
`p_db`.`p_item_token`
JOIN `p_db`.`p_item`
WHERE
(
(
CONVERT (
`p_db`.`p_item`.`itemid` USING utf8mb4
) = '0000eb612d78407a91a9b3854fffffff'
)
)
奇怪啊。Where中怎么有个 CONVERT ?我们知道,如果where条件中,等式的左边,也就是要查询的字段上有函数的话,就会导致慢。(我的理解:慢因为索引用不到了。索引的值是原始值,这个条件中用的却是处理后的值。)
注意看这函数,意思是把 itemid 这一列的编码转换成 utf8mb4 .也就是说,这一列的编码不是 utf8mb4 !
打开表,把两个表中itemid这一列的编码都改成utf8。再次运行解释。

从解释结果来看已经没有问题了。
再看下结果2中的语句:
/* select#1 */ SELECT '0000eb612d78407a91a9b3854fffffff' AS `itemid`, 'db87a780427d4d02ba2bd49fac8cf98b' AS `token`, '2016-12-16 10:46:53' AS `create_time`, '' AS `ftoken`, 'cxx' AS `product_type` FROM `toy_item_plat`.`p_item_token` JOIN `toy_item_plat`.`p_item` WHERE 1
这 select 中全是常量了。速度能不快吗?
执行结果0.036s。符合预期
经验总结:
explain 可以查看执行计划是否符合预期,如果有出现rows较大的情况,则说明出现了全表扫描,将来会是性能瓶颈
show warning的结果,则能看到优化器处理后的语句。如果与原始语句有出入,仔细对比研究能够发现实际问题。
相关推荐
-
MySQL数据库21条最佳性能优化经验
今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显.关于数据库的性能,这并不只是DBA才需要担心的事,而这更是我们程序员需要去关注的事情. 当我们去设计数据库表结构,对操作数据库时(尤其是查表时的SQL语句),我们都需要注意数据操作的性能.这里,我们不会讲过多的SQL语句的优化,而只是针对MySQL这一Web应用最多的数据库.希望下面的这些优化技巧对你有用. 1. 为查询缓存优化你的查询 大多数的MySQL服务器都开启了查询缓存.这是提高性最有效的方法之一,而且这是被M
-
MYSQL 优化常用方法
1.选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快.因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小.例如,在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间,甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很好的完成任务了.同样的,如果可以的话,我们应该使用MEDIUMINT而不是 BIGIN来定义整型字段. 另外一个提高效率的方法
-
MySQL优化必须调整的10项配置
当我们被人雇来监测MySQL性能时,人们希望我们能够检视一下MySQL配置然后给出一些提高建议.许多人在事后都非常惊讶,因为我们建议他们仅仅改动几个设置,即使是这里有好几百个配置项.这篇文章的目的在于给你一份非常重要的配置项清单. 我们曾在几年前在博客里给出了这样的建议,但是MySQL的世界变化实在太快了!写在开始前-即使是经验老道的人也会犯错,会引起很多麻烦.所以在盲目的运用这些推荐之前,请记住下面的内容: 一次只改变一个设置!这是测试改变是否有益的唯一方法. 大多数配置能在运行时使用SET
-
简单谈谈MySQL优化利器-慢查询
慢查询 首先,无论进行何种优化,开启慢查询都算是前置条件.慢查询机制,将记录过慢的查询语句(事件),从而为DB维护人员提供优化目标. 检查慢查询是否开启 通过show variables like 'slow_query_log'这条语句,可以找到慢查询的状态(On/Off). 开启慢查询 本文使用的MySQL版本:MariaDB - 10.1.19,请注意,不同版本的MySQL存在差异. 在[mysqld]下加入: [mysqld] port= 3306 slow-query-log=1 #
-

Mysql数据库性能优化三(分表、增量备份、还原)
接上篇Mysql数据库性能优化二 对表进行水平划分 如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了.如果我拆成100个表,那么每个表只有10万条记录.当然这需要数据在逻辑上可以划分.一个好的划分依据,有利于程序的简单实现,也可以充分利用水平分表的优势.比如系统界面上只提供按月查询的功能,那么把表按月拆分成12个,每个查询只查询一个表就够了.如果非要按照地域来分,即使把表拆的再小,查询还是要联合所有表来查,还不如不拆了.所以一个好的拆分依据是 最重要的
-
MYSQL分页limit速度太慢的优化方法
在mysql中limit可以实现快速分页,但是如果数据到了几百万时我们的limit必须优化才能有效的合理的实现分页了,否则可能卡死你的服务器哦. 当一个表数据有几百万的数据的时候成了问题! 如 * from table limit 0,10 这个没有问题 当 limit 200000,10 的时候数据读取就很慢,可以按照一下方法解决 第一页会很快 PERCONA PERFORMANCE CONFERENCE 2009上,来自雅虎的几位工程师带来了一篇"EfficientPag
-
mysql如何优化插入记录速度
插入记录时,影响插入速度的主要是索引.唯一性校验.一次插入记录条数等.根据这些情况,可以分别进行优化,本节将介绍优化插入记录速度的几种方法. 一. 对于MyISAM引擎表常见的优化方法如下: 1. 禁用索引.对于非空表插入记录时,MySQL会根据表的索引对插入记录建立索引.如果插入大量数据,建立索引会降低插入记录的速度.为了解决这种情况可以在插入记录之前禁用索引,数据插入完毕后在开启索引.禁用索引的语句为: ALTER TABLE tb_name DISABLE KEYS; 重新开启索引的语句
-
设置MySQL中的数据类型来优化运行速度的实例
今天看了一个优化案例觉的挺有代表性,这里记录下来做一个标记,来纪念一下随便的字段定义的问题. 回忆一下,在表的设计中很多人习惯的把表的结构设计成Varchar(64),Varchar(255)之类的,虽然大多数情况只存了5-15个字节.那么我看一下下面这个案例. 查询语句: SELECT SQL_NO_CACHE channel, COUNT(channel) AS visitors FROM xxx_sources WHERE client_id = 1301 GROUP BY client_
-
MYSQL性能优化分享(分库分表)
1.分库分表 很明显,一个主表(也就是很重要的表,例如用户表)无限制的增长势必严重影响性能,分库与分表是一个很不错的解决途径,也就是性能优化途径,现在的案例是我们有一个1000多万条记录的用户表members,查询起来非常之慢,同事的做法是将其散列到100个表中,分别从members0到members99,然后根据mid分发记录到这些表中,牛逼的代码大概是这样子: 复制代码 代码如下: <?php for($i=0;$i< 100; $i++ ){ //echo "CREATE TA
-
mysql优化连接数防止访问量过高的方法
很多开发人员都会遇见"MySQL: ERROR 1040: Too many connections"的异常情况,造成这种情况的一种原因是访问量过高,MySQL服务器抗不住,这个时候就要考虑增加从服务器分散读压力:另一种原因就是MySQL配置文件中max_connections值过小. 首先,我们来查看mysql的最大连接数: mysql> show variables like '%max_connections%'; +-----------------+-------+ |