Python Pytorch深度学习之神经网络
目录
- 一、简介
- 二、神经网络训练过程
- 2、通过调用net.parameters()返回模型可训练的参数
- 3、迭代整个输入
- 4、调用反向传播
- 5、计算损失值
- 6、反向传播梯度
- 7、更新神经网络参数
- 总结
一、简介
神经网络可以通过torch.nn包构建,上一节已经对自动梯度有些了解,神经网络是基于自动梯度来定义一些模型。一个nn.Module包括层和一个方法,它会返回输出。例如:数字图片识别的网络:
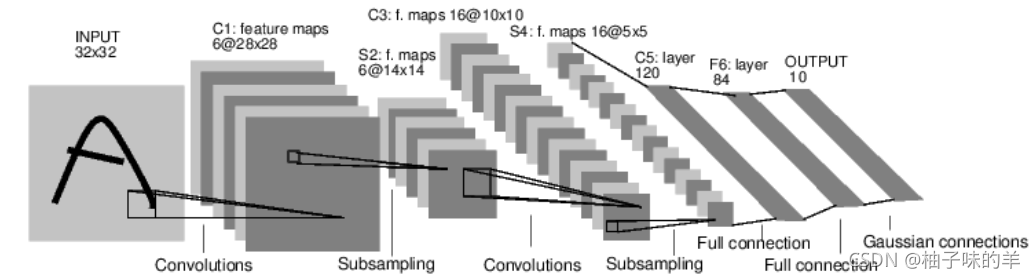
上图是一个简单的前回馈神经网络,它接收输入,让输入一个接着一个通过一些层,最后给出输出。
二、神经网络训练过程
一个典型的神经
# -*- coding: utf-8 -*-
"""
Created on Sun Oct 24 15:56:23 2021
@author: Lenovo
"""
# 神经网络
# import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
# 1个输入,6个输出,5*5的卷积
# 内核
self.conv1=nn.Conv2d(1,6,5)
self.conv2=nn.Conv2d(6,16,5)
# 映射函数:线性——y=Wx+b
self.fc1=nn.Linear(16*5*5,120)#输入特征值:16*5*5,输出特征值:120
self.fc2=nn.Linear(120,84)
self.fc3=nn.Linear(84,10)
def forward(self,x):
x=F.max_pool2d(F.relu(self.conv1(x)),(2,2))
# 如果其尺寸是一个square只能指定一个数字
x=F.max_pool2d(F.relu(self.conv2(x)),2)
x=x.view(-1,self.num_flat_features(x))
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)
return x
def num_flat_features(self,x):
size=x.size()[1:]
num_features=1
for s in size:
num_features *= s
return num_features
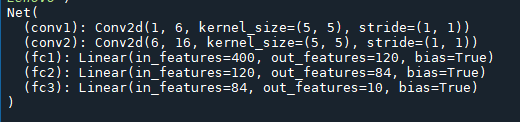
net=Net()
print(net)
运行结果
以上定义了一个前馈函数,然后反向传播函数被自动通过autograd定义,可以使用任何张量操作在前馈函数上。
2、通过调用net.parameters()返回模型可训练的参数
# 查看模型可训练的参数 params=list(net.parameters()) print(len(params)) print(params[0].size())# conv1 的权重weight
运行结果

3、迭代整个输入
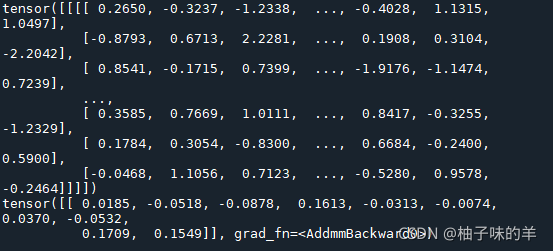
尝试随机生成一个3232的输入。注:期望的输入维度是3232,为了在MNIST数据集上使用这个网络,我们需要把数据集中的图片维度修改为32*32
input=torch.randn(1, 1, 32,32) print(input) out=net(input) print(out)
运行结果
4、调用反向传播
将所有参数梯度缓存器置零,用随机的梯度来反向传播
# 调用反向传播 net.zero_grad() out.backward(torch.randn(1, 10))
运行结果

5、计算损失值
#计算损失值——损失函数:一个损失函数需要一对输入:模型输出和目标,然后计算一个值来评估输出距离目标多远。有一些不同的损失函数在nn包中,一个简单的损失函数就是nn.MSELoss,他计算了均方误差
如果跟随损失到反向传播路径,可以使用他的.grad_fn属性,将会看到一个计算图

# 在调用loss.backward()时候,整个图都会微分,而且所有的图中的requires_grad=True的张量将会让他们的grad张量累计梯度 #跟随以下步骤反向传播 print(loss.grad_fn)#MSELoss print(loss.grad_fn.next_functions[0][0])#Linear print(loss.grad_fn.next_functions[0][0].next_functions[0][0])#relu
运行结果

6、反向传播梯度
为了实现反向传播loss,我们所有需要做的事情仅仅是使用loss.backward()。需要先清空现存的梯度,不然梯度将会和现存的梯度累计在一起。
# 调用loss.backward()然后看一下con1的偏置项在反向传播之前和之后的变化
net.zero_grad()
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()#反向传播
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
运行结果

7、更新神经网络参数
# ============================================================================= # # 最简单的更新规则就是随机梯度下降:weight=weight-learning_rate*gradient # learning_rate=0.01 # for f in net.parameters(): # f.data.sub_(f.grad.data*learning_rate)#f.data=f.data-learning_rate*gradient # =============================================================================
如果使用的是神经网络,想要使用不同的更新规则,类似于SGD,Nesterov-SGD,Adam,RMSProp等。为了让这可行,Pytorch建立一个称为torch.optim的package实现所有的方法,使用起来更加方便
# ============================================================================= # import torch.optim as optim # optimizer=optim.SGD(net.parameters(), lr=0.01) # # 在迭代训练过程中 # optimizer.zero_grad()#将现存梯度置零 # output=net(input) # loss=criterion(output,target) # loss.backward()#反向传递 # optimizer.step()#更新网络参数 # =============================================================================
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

Python深度学习pytorch神经网络Dropout应用详解解
目录 扰动的鲁棒性 实践中的dropout 简洁实现 扰动的鲁棒性 在之前我们讨论权重衰减(L2正则化)时看到的那样,参数的范数也代表了一种有用的简单性度量.简单性的另一个有用角度是平滑性,即函数不应该对其输入的微笑变化敏感.例如,当我们对图像进行分类时,我们预计向像素添加一些随机噪声应该是基本无影响的. dropout在正向传播过程中,计算每一内部层同时注入噪声,这已经成为训练神经网络的标准技术.这种方法之所以被称为dropout,因为我们从表面上看是在训练过程中丢弃(drop out)一些
-
Python深度学习pytorch神经网络多层感知机简洁实现
我们可以通过高级API更简洁地实现多层感知机. import torch from torch import nn from d2l import torch as d2l 模型 与softmax回归的简洁实现相比,唯一的区别是我们添加了2个全连接层.第一层是隐藏层,它包含256个隐藏单元,并使用了ReLU激活函数.第二层是输出层. net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 1
-
Python深度学习pytorch神经网络汇聚层理解
目录 最大汇聚层和平均汇聚层 填充和步幅 多个通道 我们的机器学习任务通常会跟全局图像的问题有关(例如,"图像是否包含一只猫呢?"),所以我们最后一层的神经元应该对整个输入的全局敏感.通过逐渐聚合信息,生成越来越粗糙的映射,最终实现学习全局表示的目标,同时将卷积图层的所有有时保留在中间层. 此外,当检测较底层的特征时(例如之前讨论的边缘),我们通常希望这些特征保持某种程度上的平移不变性.例如,如果我们拍摄黑白之间轮廓清晰的图像X,并将整个图像向右移动一个像素,即Z[i, j] = X[
-
Python深度学习pytorch神经网络图像卷积运算详解
目录 互相关运算 卷积层 特征映射 由于卷积神经网络的设计是用于探索图像数据,本节我们将以图像为例. 互相关运算 严格来说,卷积层是个错误的叫法,因为它所表达的运算其实是互相关运算(cross-correlation),而不是卷积运算.在卷积层中,输入张量和核张量通过互相关运算产生输出张量. 首先,我们暂时忽略通道(第三维)这一情况,看看如何处理二维图像数据和隐藏表示.下图中,输入是高度为3.宽度为3的二维张量(即形状为 3 × 3 3\times3 3×3).卷积核的高度和宽度都是2. 注意,
-
Python深度学习pytorch神经网络多输入多输出通道
目录 多输入通道 多输出通道 1 × 1 1\times1 1×1卷积层 虽然每个图像具有多个通道和多层卷积层.例如彩色图像具有标准的RGB通道来指示红.绿和蓝.但是到目前为止,我们仅展示了单个输入和单个输出通道的简化例子.这使得我们可以将输入.卷积核和输出看作二维张量. 当我们添加通道时,我们的输入和隐藏的表示都变成了三维张量.例如,每个RGB输入图像具有 3 × h × w 3\times{h}\times{w} 3×h×w的形状.我们将这个大小为3的轴称为通道(channel)维度.在本节
-
Python深度学习pytorch神经网络填充和步幅的理解
目录 填充 步幅 上图中,输入的高度和宽度都为3,卷积核的高度和宽度都为2,生成的输出表征的维度为 2 × 2 2\times2 2×2.从上图可看出卷积的输出形状取决于输入形状和卷积核的形状. 填充 以上面的图为例,在应用多层卷积时,我们常常丢失边缘像素. 解决这个问题的简单方法即为填充(padding):在输入图像的边界填充元素(通常填充元素是0). 例如,在上图中我们将 3 × 3 3\times3 3×3输入填充到 5 × 5 5\times5 5×5,那么它的输出就增加为 4 × 4
-
Python Pytorch深度学习之神经网络
目录 一.简介 二.神经网络训练过程 2.通过调用net.parameters()返回模型可训练的参数 3.迭代整个输入 4.调用反向传播 5.计算损失值 6.反向传播梯度 7.更新神经网络参数 总结 一.简介 神经网络可以通过torch.nn包构建,上一节已经对自动梯度有些了解,神经网络是基于自动梯度来定义一些模型.一个nn.Module包括层和一个方法,它会返回输出.例如:数字图片识别的网络: 上图是一个简单的前回馈神经网络,它接收输入,让输入一个接着一个通过一些层,最后给出输出. 二.神经
-
Python Pytorch深度学习之数据加载和处理
目录 一.下载安装包 二.下载数据集 三.读取数据集 四.编写一个函数看看图像和landmark 五.数据集类 六.数据可视化 七.数据变换 1.Function_Rescale 2.Function_RandomCrop 3.Function_ToTensor 八.组合转换 九.迭代数据集 总结 一.下载安装包 packages: scikit-image:用于图像测IO和变换 pandas:方便进行csv解析 二.下载数据集 数据集说明:该数据集(我在这)是imagenet数据集标注为fac
-
Python Pytorch深度学习之核心小结
目录 一.Numpy实现网络 二.Pytorch:Tensor 三.自动求导 1.PyTorch:Tensor和auto_grad 总结 Pytorch的核心是两个主要特征: 1.一个n维tensor,类似于numpy,但是tensor可以在GPU上运行 2.搭建和训练神经网络时的自动微分/求导机制 一.Numpy实现网络 在总结Tensor之前,先使用numpy实现网络.numpy提供了一个n维数组对象,以及许多用于操作这些数组的函数. import numpy as np # n是批量大小,
-
Python Pytorch深度学习之图像分类器
目录 一.简介 二.数据集 三.训练一个图像分类器 1.导入package吧 2.归一化处理+贴标签吧 3.先来康康训练集中的照片吧 4.定义一个神经网络吧 5.定义一个损失函数和优化器吧 6.训练网络吧 7.在测试集上测试一下网络吧 8.分别查看一下训练效果吧 总结 一.简介 通常,当处理图像.文本.语音或视频数据时,可以使用标准Python将数据加载到numpy数组格式,然后将这个数组转换成torch.*Tensor 对于图像,可以用Pillow,OpenCV 对于语音,可以用scipy,l
-
Python Pytorch深度学习之自动微分
目录 一.简介 二.TENSOR 三.梯度 四.Example--雅克比向量积 总结 一.简介 antograd包是Pytorch中所有神经网络的核心.autograd为Tensor上的所有操作提供自动微分,它是一个由运行定义的框架,这意味着以代码运行方式定义后向传播,并且每一次迭代都可能不同 二.TENSOR torch.Tensor是包的核心. 1.如果将属性.requires_grad设置为True,则会开始跟踪针对tensor的所有操作. 2.完成计算之后,可以调用backward()来
-
Python Pytorch深度学习之Tensors张量
目录 一.Tensor(张量) 二.操作 总结 环境:Anaconda自带的编译器--Spyder 最近才开使用conda,发现conda 就是 yyds,爱啦~ 一.Tensor(张量) import torch #构造一个5*3的空矩阵 x=torch.FloatTensor(5,3) print(x) # 构造随机初始化矩阵 x=torch.rand(5,3) print(x) # 构造一个矩阵全为0,而且数据类型为long x=torch.zeros(5,3,dtype=torch.lo
-
Python深度学习TensorFlow神经网络基础概括
目录 一.基础理论 1.TensorFlow 2.TensorFlow过程 1.构建图阶段 2.执行图阶段(会话) 二.TensorFlow实例(执行加法) 1.构造静态图 1-1.创建数据(张量) 1-2.创建操作(节点) 2.会话(执行) API: 普通执行 fetches(多参数执行) feed_dict(参数补充) 总代码 一.基础理论 1.TensorFlow tensor:张量(数据) flow:流动 Tensor-Flow:数据流 2.TensorFlow过程 TensorFlow
-
Pytorch深度学习经典卷积神经网络resnet模块训练
目录 前言 一.resnet 二.resnet网络结构 三.resnet18 1.导包 2.残差模块 2.通道数翻倍残差模块 3.rensnet18模块 4.数据测试 5.损失函数,优化器 6.加载数据集,数据增强 7.训练数据 8.保存模型 9.加载测试集数据,进行模型测试 四.resnet深层对比 前言 随着深度学习的不断发展,从开山之作Alexnet到VGG,网络结构不断优化,但是在VGG网络研究过程中,人们发现随着网络深度的不断提高,准确率却没有得到提高,如图所示: 人们觉得深度学习到此
-
Pytorch深度学习之实现病虫害图像分类
目录 一.pytorch框架 1.1.概念 1.2.机器学习与深度学习的区别 1.3.在python中导入pytorch成功截图 二.数据集 三.代码复现 3.1.导入第三方库 3.2.CNN代码 3.3.测试代码 四.训练结果 4.1.LOSS损失函数 4.2. ACC 4.3.单张图片识别准确率 四.小结 一.pytorch框架 1.1.概念 PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序. 2017年1月,由Facebook人工智能研究院(FA
-
Python编程深度学习计算库之numpy
NumPy是python下的计算库,被非常广泛地应用,尤其是近来的深度学习的推广.在这篇文章中,将会介绍使用numpy进行一些最为基础的计算. NumPy vs SciPy NumPy和SciPy都可以进行运算,主要区别如下 最近比较热门的深度学习,比如在神经网络的算法,多维数组的使用是一个极为重要的场景.如果你熟悉tensorflow中的tensor的概念,你会非常清晰numpy的作用.所以熟悉Numpy可以说是使用python进行深度学习入门的一个基础知识. 安装 liumiaocn:tmp