Python爬虫实战演练之采集拉钩网招聘信息数据
目录
- 本文要点:
- 环境介绍
- 本次目标
- 爬虫块使用
- 内置模块:
- 第三方模块:
- 代码实现步骤: (爬虫代码基本步骤)
- 开始代码
- 导入模块
- 发送请求
- 解析数据
- 加翻页
- 保存数据
- 运行代码,得到数据
本文要点:
- 爬虫的基本流程
- requests模块的使用
- 保存csv
- 可视化分析展示
环境介绍
- python 3.8
- pycharm 2021专业版 激活码
- Jupyter Notebook
pycharm 是编辑器 >> 用来写代码的 (更方便写代码, 写代码更加舒适)
python 是解释器 >>> 运行解释python代码的
本次目标

爬虫块使用
内置模块:
- import pprint >>> 格式化输入模块
- import csv >>> 保存csv文件
- import re >>> re 正则表达式
- import time >>> 时间模块
第三方模块:
- import requests >>> 数据请求模块 pip install requests
win + R 输入cmd,回车输入安装命令pip install 模块名。
如果出现爆红,可能是因为,网络连接超时,切换国内镜像源
代码实现步骤: (爬虫代码基本步骤)
- 发送请求
- 获取数据
- 解析数据
- 保存数据
开始代码
导入模块
import requests # 数据请求模块 第三方模块 pip install requests import pprint # 格式化输出模块 import csv # csv保存数据 import time
发送请求
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
# headers 请求头 用来伪装python代码, 防止被识别出是爬虫程序, 然后被反爬
# user-agent: 浏览器的基本标识
headers = {
'cookie': 'privacyPolicyPopup=false; user_trace_token=20211016201224-ba4d90f0-3db5-4647-a86e-411ee3d5bfef; __lg_stoken__=08639898fbdd53a7ebf88fa16e895b59a51e47738f45faef6a32b9a88d6537bf9459b2c6d956a636a99ff599c6a260f04514df42cb77f83065d55f48a2549e60381e8da811b8; JSESSIONID=ABAAAECAAEBABIIE72FFC38A79322951663B5C7AF10CD12; WEBTJ-ID=20211016201225-17c89047f4293-0d7a7cd583dc83-b7a1438-2073600-17c89047f43a90; sajssdk_2015_cross_new_user=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2217c8904800d57b-04f17ed5193984-b7a1438-2073600-17c8904800e765%22%2C%22%24device_id%22%3A%2217c8904800d57b-04f17ed5193984-b7a1438-2073600-17c8904800e765%22%7D; PRE_UTM=; PRE_HOST=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist%5Fpython%3FlabelWords%3D%26fromSearch%3Dtrue%26suginput%3D; LGSID=20211016201225-7b8aa578-74ab-4b09-885c-ebbe57a6029a; PRE_SITE=; LGUID=20211016201225-fda15dbb-7823-4a2d-9d80-258caf018f02; _ga=GA1.2.903785807.1634386346; _gat=1; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1634386346; _gid=GA1.2.701447082.1634386346; X_HTTP_TOKEN=ba154973a88f2f64153683436141effc1d544fa2ed; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1634386352; LGRID=20211016201232-8913a057-d37d-41c3-b094-a04cf36515a7; SEARCH_ID=ff32d1294b464305b4e0907f659ef2a7',
'referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
data = {
'first': 'false',
'pn': page,
'kd': 'python',
'sid': 'bf8ed05047294473875b2c8373df0357'
}
# response 自定义变量 可以自己定义
response = requests.post(url=url, data=data, headers=headers)
<Response [200]> 获取服务器给我们响应数据
解析数据
json数据最好解析 非常好解析, 就根据字典键值对取值
result = response.json()['content']['positionResult']['result']
# 循环遍历 从 result 列表里面 把元素一个一个提取出来
for index in result:
# pprint.pprint(index)
# href = index['positionId']
href = f'https://www.lagou.com/jobs/{index["positionId"]}.html'
dit = {
'标题': index['positionName'],
'地区': index['city'],
'公司名字': index['companyFullName'],
'薪资': index['salary'],
'学历': index['education'],
'经验': index['workYear'],
'公司标签': ','.join(index['companyLabelList']),
'详情页': href,
}
# ''.join() 把列表转成字符串 '免费班车',
csv_writer.writerow(dit)
print(dit)
加翻页
for page in range(1, 31):
print(f'------------------------正在爬取第{page}页-------------------------')
time.sleep(1)
保存数据
f = open('招聘数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'标题',
'地区',
'公司名字',
'薪资',
'学历',
'经验',
'公司标签',
'详情页',
])
csv_writer.writeheader() # 写入表头
运行代码,得到数据

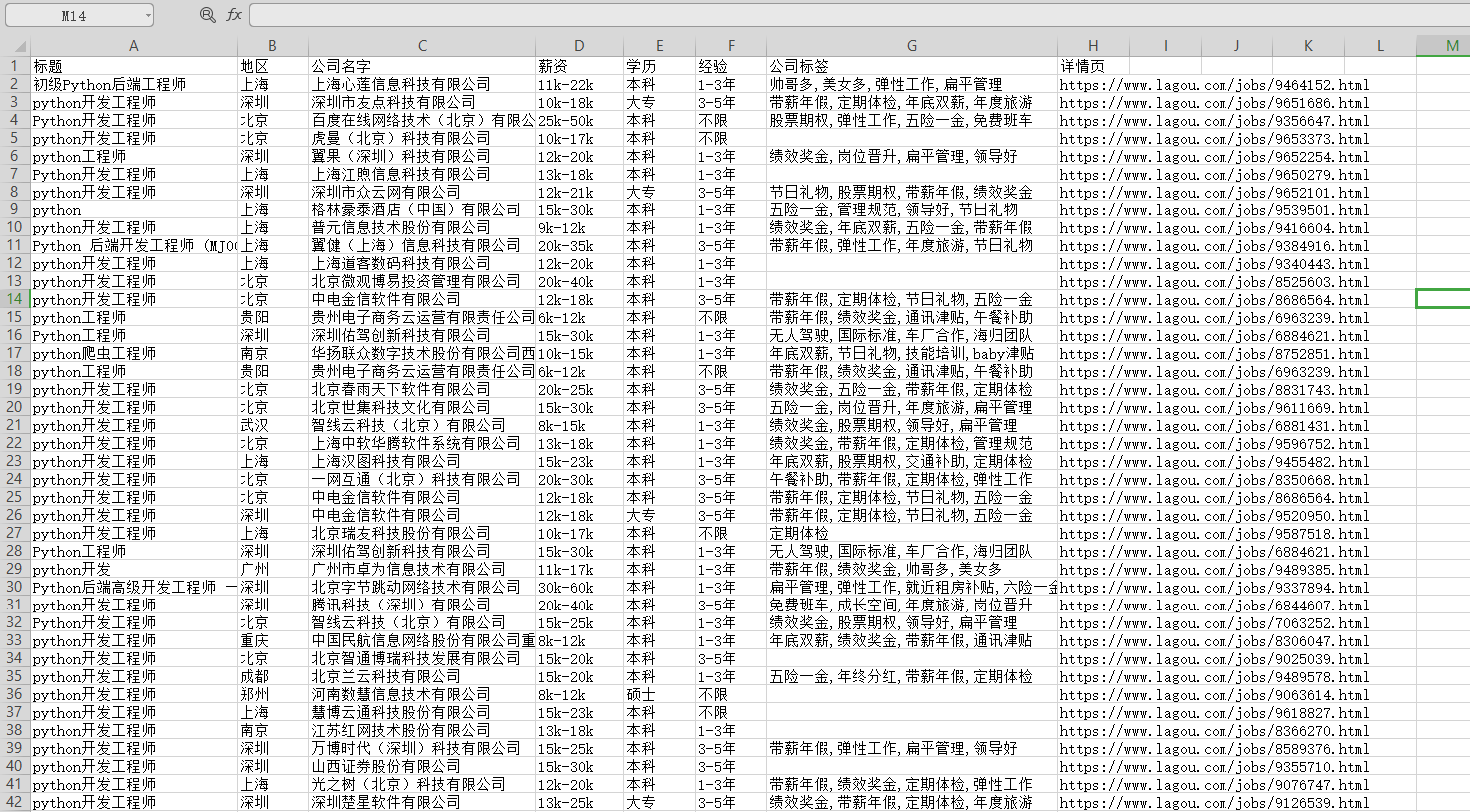
【付费VIP完整版】只要看了就能学会的教程,80集Python基础入门视频教学
到此这篇关于Python爬虫实战演练之采集拉钩网招聘信息数据的文章就介绍到这了,更多相关Python 采集拉钩网招聘信息数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫实战演练之采集糗事百科段子数据
目录 知识点 爬虫基本步骤: 爬虫代码 导入所需模块 获取网页地址 发送请求 数据解析 保存数据 运行代码,得到数据 知识点 1.爬虫基本步骤 2.requests模块 3.parsel模块 4.xpath数据解析方法 5.分页功能 爬虫基本步骤: 1.获取网页地址 (糗事百科的段子的地址) 2.发送请求 3.数据解析 4.保存 本地 爬虫代码 导入所需模块 import re import requests import parsel 获取网页地址 url = 'https://www.qiu
-
python opencv通过按键采集图片源码
一.python版本 写了个python opencv的小demo,可以通过键盘按下字母s进行采集图像. 功能说明 "N" 新建文件夹 data/ 用来存储图像 "S" 开始采集图像,将采集到的图像放到 data/ 路径下 "Q" 退出窗口 python opencv源码 ''' "N" 新建文件夹 data/ 用来存储图像 "S" 开始采集图像,将采集到的图像放到 data/ 路径下 "Q&qu
-
Python实战项目之MySQL tkinter pyinstaller实现学生管理系统
终极版终于有时间给大家分享了!!!. 我们先看一下效果图. 1:登录界面: 2:查询数据库所有的内容! 3:链接数据库: 4:最终的打包! 话不多说直接上代码!!!! from tkinter import * import pymysql from tkinter.messagebox import * from tkinter import ttk def get_connect(): conn = pymysql.connect(host='localhost', user="root&q
-
基于Python采集爬取微信公众号历史数据
鲲之鹏的技术人员将在本文介绍一种通过模拟操作微信App的方式采集指定公众号的所有历史数据的方法. 通过我们抓包分析发现,微信公众号的历史数据是通过HTTP协议加载的,对应的API接口如下图所示,其中有四个关键参数(__biz.appmsg_token.pass_ticket以及Cookie). 为了能够拿到这四个参数,我们需要模拟操作App,让其产生这些参数,然后我们再抓包获取.对于模拟App操作,前面我们曾介绍过通过Python模拟安卓App的方法(详见http://www.site-digg
-
Python编程实现下载器自动爬取采集B站弹幕示例
目录 实现效果 UI界面 数据采集 小结 大家好,我是小张! 在<Python编程实现小姐姐跳舞并生成词云视频示例>文章中简单介绍了B站弹幕的爬取方法,只需找到视频中的参数 cid,就能采集到该视频下的所有弹幕:思路虽然很简单,但个人感觉还是比较麻烦,例如之后的某一天,我想采集B站上的某个视频弹幕,还需要从头开始:找cid参数.写代码,重复单调: 因此我在想有没有可能一步到位,以后采集某个视频弹幕时只需一步操作,比如输入想爬取的视频链接,程序能自动识别下载 实现效果 基于此,借助 PyQt5
-
Python爬虫实战演练之采集拉钩网招聘信息数据
目录 本文要点: 环境介绍 本次目标 爬虫块使用 内置模块: 第三方模块: 代码实现步骤: (爬虫代码基本步骤) 开始代码 导入模块 发送请求 解析数据 加翻页 保存数据 运行代码,得到数据 本文要点: 爬虫的基本流程 requests模块的使用 保存csv 可视化分析展示 环境介绍 python 3.8 pycharm 2021专业版 激活码 Jupyter Notebook pycharm 是编辑器 >> 用来写代码的 (更方便写代码, 写代码更加舒适) python 是解释器 >&
-
Python爬虫之Selenium下拉框处理的实现
在我们浏览网页的时候经常会碰到下拉框,WebDriver提供了Select类来处理下拉框,详情请往下看: 本章中用到的关键方法如下: select_by_value():设置下拉框的值 switch_to.alert.accept():定位并接受现有警告框(详情请参考Python爬虫 - Selenium(9)警告框(弹窗)处理) click():鼠标点击事件(其他鼠标事件请参考Python爬虫 - Selenium(5)鼠标事件) move_to_element():鼠标悬停(详情请参考Pyt
-
python使用requests库爬取拉勾网招聘信息的实现
按F12打开开发者工具抓包,可以定位到招聘信息的接口 在请求中可以获取到接口的url和formdata,表单中pn为请求的页数,kd为关请求职位的关键字 使用python构建post请求 data = { 'first': 'true', 'pn': '1', 'kd': 'python' } headers = { 'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&a
-
python爬虫_微信公众号推送信息爬取的实例
问题描述 利用搜狗的微信搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地. 注意点 搜狗微信获取的地址为临时链接,具有时效性. 公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容是不含推送消息的,这里使用selenium+PhantomJS处理 代码 #! /usr/bin/env python3 from selenium import webdriver from datetime import datetime import bs4, requ
-
Python爬虫使用脚本登录Github并查看信息
前言分析目标网站的登录方式 目标地址: https://github.com/login 登录方式做出分析: 第一,用form表单方式提交信息, 第二,有csrf_token, 第三 ,是以post请求发送用户名和密码时,需要第一次get请求的cookie 第四,登录成功以后,请求其他页面是只需要带第一次登录成功以后返回的cookie就可以. 以get发送的请求获取我们想要的token和cookie 代码: import requests from bs4 import BeautifulSou
-
Python爬虫之爬取2020女团选秀数据
一.先看结果 1.1创造营2020撑腰榜前三甲 创造营2020撑腰榜前三名分别是 希林娜依·高.陈卓璇 .郑乃馨 >>>df1[df1['排名']<=3 ][['排名','姓名','身高','体重','生日','出生地']] 排名 姓名 身高 体重 生日 出生地 0 1.0 希林娜依·高 NaN NaN 1998年07月31日 新疆 1 2.0 陈卓璇 168.0 42.0 1997年08月13日 贵州 2 3.0 郑乃馨 NaN NaN 1997年06月25日 泰国 1.2青春有
-
Python爬虫之爬取某文库文档数据
一.基本开发环境 Python 3.6 Pycharm 二.相关模块的使用 import os import requests import time import re import json from docx import Document from docx.shared import Cm 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.目标网页分析 网站的文档内容,都是以图片形式存在的.它有自己的数据接口 接口链接: https://openapi.book11
-
Python爬虫之爬取我爱我家二手房数据
一.问题说明 首先,运行下述代码,复现问题: # -*-coding:utf-8-*- import re import requests from bs4 import BeautifulSoup cookie = 'PHPSESSID=aivms4ufg15sbrj0qgboo3c6gj; HMF_CI=4d8ff20092e9832daed8fe5eb0475663812603504e007aca93e6630c00b84dc207; _ga=GA1.2.556271139.1620784
-
Python爬虫实战之批量下载快手平台视频数据
知识点 requests json re pprint 开发环境: 版 本:anaconda5.2.0(python3.6.5) 编辑器:pycharm 案例实现步骤: 一. 数据来源分析 (只有当你找到数据来源的时候, 才能通过代码实现) 1.确定需求 (要爬取的内容是什么?) 爬取某个关键词对应的视频 保存mp4 2.通过开发者工具进行抓包分析 分析数据从哪里来的(找出真正的数据来源)? 静态加载页面 笔趣阁为例 动态加载页面 开发者工具抓数据包 [付费VIP完整版]只要看了就能学会的教程,