Python Pytorch深度学习之数据加载和处理
目录
- 一、下载安装包
- 二、下载数据集
- 三、读取数据集
- 四、编写一个函数看看图像和landmark
- 五、数据集类
- 六、数据可视化
- 七、数据变换
- 1、Function_Rescale
- 2、Function_RandomCrop
- 3、Function_ToTensor
- 八、组合转换
- 九、迭代数据集
- 总结
一、下载安装包
packages:
scikit-image:用于图像测IO和变换pandas:方便进行csv解析
二、下载数据集
数据集说明:该数据集(我在这)是imagenet数据集标注为face的图片当中在dlib面部检测表现良好的图片——处理的是一个面部姿态的数据集,也就是按照入戏方式标注人脸

数据集展示

三、读取数据集
#%%读取数据集
landmarks_frame=pd.read_csv('D:/Python/Pytorch/data/faces/face_landmarks.csv')
n=65
img_name=landmarks_frame.iloc[n,0]
landmarks=landmarks_frame.iloc[n,1:].values
landmarks=landmarks.astype('float').reshape(-1,2)
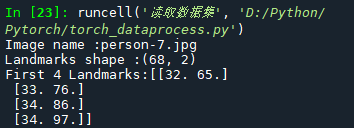
print('Image name :{}'.format(img_name))
print('Landmarks shape :{}'.format(landmarks.shape))
print('First 4 Landmarks:{}'.format(landmarks[:4]))
运行结果
四、编写一个函数看看图像和landmark
#%%编写显示人脸函数
def show_landmarks(image,landmarks):
plt.imshow(image)
plt.scatter(landmarks[:,0],landmarks[:,1],s=10,marker=".",c='r')
plt.pause(0.001)
plt.figure()
show_landmarks(io.imread(os.path.join('D:/Python/Pytorch/data/faces/',img_name)),landmarks)
plt.show()
运行结果

五、数据集类
torch.utils.data.Dataset是表示数据集的抽象类,自定义数据类应继承Dataset并覆盖__len__实现len(dataset)返还数据集的尺寸。__getitem__用来获取一些索引数据:
#%%数据集类——将数据集封装成一个类
class FaceLandmarksDataset(Dataset):
def __init__(self,csv_file,root_dir,transform=None):
# csv_file(string):待注释的csv文件的路径
# root_dir(string):包含所有图像的目录
# transform(callabele,optional):一个样本上的可用的可选变换
self.landmarks_frame=pd.read_csv(csv_file)
self.root_dir=root_dir
self.transform=transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
img_name=os.path.join(self.root_dir,self.landmarks_frame.iloc[idx,0])
image=io.imread(img_name)
landmarks=self.landmarks_frame.iloc[idx,1:]
landmarks=np.array([landmarks])
landmarks=landmarks.astype('float').reshape(-1,2)
sample={'image':image,'landmarks':landmarks}
if self.transform:
sample=self.transform(sample)
return sample
六、数据可视化
#%%数据可视化
# 将上面定义的类进行实例化并便利整个数据集
face_dataset=FaceLandmarksDataset(csv_file='D:/Python/Pytorch/data/faces/face_landmarks.csv',
root_dir='D:/Python/Pytorch/data/faces/')
fig=plt.figure()
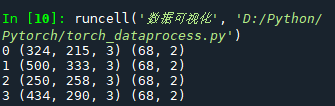
for i in range(len(face_dataset)) :
sample=face_dataset[i]
print(i,sample['image'].shape,sample['landmarks'].shape)
ax=plt.subplot(1,4,i+1)
plt.tight_layout()
ax.set_title('Sample #{}'.format(i))
ax.axis('off')
show_landmarks(**sample)
if i==3:
plt.show()
break
运行结果

七、数据变换
由上图可以发现每张图像的尺寸大小是不同的。绝大多数神经网路都嘉定图像的尺寸相同。所以需要对图像先进行预处理。创建三个转换:
Rescale:缩放图片
RandomCrop:对图片进行随机裁剪
ToTensor:把numpy格式图片转成torch格式图片(交换坐标轴)和上面同样的方式,将其写成一个类,这样就不需要在每次调用的时候川第一此参数,只需要实现__call__的方法,必要的时候使用__init__方法
1、Function_Rescale
# 将样本中的图像重新缩放到给定的大小
class Rescale(object):
def __init__(self,output_size):
assert isinstance(output_size,(int,tuple))
self.output_size=output_size
#output_size 为int或tuple,如果是元组输出与output_size匹配,
#如果是int,匹配较小的图像边缘到output_size保持纵横比相同
def __call__(self,sample):
image,landmarks=sample['image'],sample['landmarks']
h,w=image.shape[:2]
if isinstance(self.output_size, int):#输入参数是int
if h>w:
new_h,new_w=self.output_size*h/w,self.output_size
else:
new_h,new_w=self.output_size,self.output_size*w/h
else:#输入参数是元组
new_h,new_w=self.output_size
new_h,new_w=int(new_h),int(new_w)
img=transform.resize(image, (new_h,new_w))
landmarks=landmarks*[new_w/w,new_h/h]
return {'image':img,'landmarks':landmarks}
2、Function_RandomCrop
# 随机裁剪样本中的图像
class RandomCrop(object):
def __init__(self,output_size):
assert isinstance(output_size, (int,tuple))
if isinstance(output_size, int):
self.output_size=(output_size,output_size)
else:
assert len(output_size)==2
self.output_size=output_size
# 输入参数依旧表示想要裁剪后图像的尺寸,如果是元组其而包含两个元素直接复制长宽,如果是int,则裁剪为方形
def __call__(self,sample):
image,landmarks=sample['image'],sample['landmarks']
h,w=image.shape[:2]
new_h,new_w=self.output_size
#确定图片裁剪位置
top=np.random.randint(0,h-new_h)
left=np.random.randint(0,w-new_w)
image=image[top:top+new_h,left:left+new_w]
landmarks=landmarks-[left,top]
return {'image':image,'landmarks':landmarks}
3、Function_ToTensor
#%%
# 将样本中的npdarray转换为Tensor
class ToTensor(object):
def __call__(self,sample):
image,landmarks=sample['image'],sample['landmarks']
image=image.transpose((2,0,1))#交换颜色轴
#numpy的图片是:Height*Width*Color
#torch的图片是:Color*Height*Width
return {'image':torch.from_numpy(image),
'landmarks':torch.from_numpy(landmarks)}
八、组合转换
将上面编写的类应用到实例中
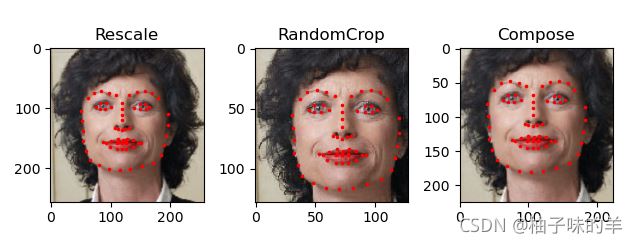
Req: 把图像的短边调整为256,随机裁剪(randomcrop)为224大小的正方形。即:组合一个Rescale和RandomCrop的变换。
#%%
scale=Rescale(256)
crop=RandomCrop(128)
composed=transforms.Compose([Rescale(256),RandomCrop(224)])
# 在样本上应用上述变换
fig=plt.figure()
sample=face_dataset[65]
for i,tsfrm in enumerate([scale,crop,composed]):
transformed_sample=tsfrm(sample)
ax=plt.subplot(1,3,i+1)
plt.tight_layout()
ax.set_title(type(tsfrm).__name__)
show_landmarks(**transformed_sample)
plt.show()
运行结果
九、迭代数据集
把这些整合起来以创建一个带有组合转换的数据集,总结一下没每次这个数据集被采样的时候:及时的从文件中读取图片,对读取的图片应用转换,由于其中一部是随机的randomcrop,数据被增强了。可以使用循环对创建的数据集执行同样的操作
transformed_dataset=FaceLandmarksDataset(csv_file='D:/Python/Pytorch/data/faces/face_landmarks.csv',
root_dir='D:/Python/Pytorch/data/faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
for i in range(len(transformed_dataset)):
sample=transformed_dataset[i]
print(i,sample['image'].size(),sample['landmarks'].size())
if i==3:
break
运行结果

对所有数据集简单使用for循环会牺牲很多功能——>麻烦,效率低!!改用多线程并行进行
torch.utils.data.DataLoader可以提供上述功能的迭代器。collate_fn参数可以决定如何对数据进行批处理,绝大多数情况下默认值就OK
transformed_dataset=FaceLandmarksDataset(csv_file='D:/Python/Pytorch/data/faces/face_landmarks.csv',
root_dir='D:/Python/Pytorch/data/faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
for i in range(len(transformed_dataset)):
sample=transformed_dataset[i]
print(i,sample['image'].size(),sample['landmarks'].size())
if i==3:
break
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
pytorch 图像中的数据预处理和批标准化实例
目前数据预处理最常见的方法就是中心化和标准化. 中心化相当于修正数据的中心位置,实现方法非常简单,就是在每个特征维度上减去对应的均值,最后得到 0 均值的特征. 标准化也非常简单,在数据变成 0 均值之后,为了使得不同的特征维度有着相同的规模,可以除以标准差近似为一个标准正态分布,也可以依据最大值和最小值将其转化为 -1 ~ 1 之间 批标准化:BN 在数据预处理的时候,我们尽量输入特征不相关且满足一个标准的正态分布,这样模型的表现一般也较好.但是对于很深的网路结构,网路的非线性层会使得输出的结
-
pytorch加载语音类自定义数据集的方法教程
前言 pytorch对一下常用的公开数据集有很方便的API接口,但是当我们需要使用自己的数据集训练神经网络时,就需要自定义数据集,在pytorch中,提供了一些类,方便我们定义自己的数据集合 torch.utils.data.Dataset:所有继承他的子类都应该重写 __len()__ , __getitem()__ 这两个方法 __len()__ :返回数据集中数据的数量 __getitem()__ :返回支持下标索引方式获取的一个数据 torch.utils.data.DataLoad
-
pytorch加载自己的图像数据集实例
之前学习深度学习算法,都是使用网上现成的数据集,而且都有相应的代码.到了自己开始写论文做实验,用到自己的图像数据集的时候,才发现无从下手 ,相信很多新手都会遇到这样的问题. 参考文章https://www.jb51.net/article/177613.htm 下面代码实现了从文件夹内读取所有图片,进行归一化和标准化操作并将图片转化为tensor.最后读取第一张图片并显示. # 数据处理 import os import torch from torch.utils import data fr
-
Pytorch自己加载单通道图片用作数据集训练的实例
pytorch 在torchvision包里面有很多的的打包好的数据集,例如minist,Imagenet-12,CIFAR10 和CIFAR100.在torchvision的dataset包里面,用的时候直接调用就行了.具体的调用格式可以去看文档(目前好像只有英文的).网上也有很多源代码. 不过,当我们想利用自己制作的数据集来训练网络模型时,就要有自己的方法了.pytorch在torchvision.dataset包里面封装过一个函数ImageFolder().这个函数功能很强大,只要你直接将
-
pytorch数据预处理错误的解决
出错: Traceback (most recent call last): File "train.py", line 305, in <module> train_model(model_conv, criterion, optimizer_conv, exp_lr_scheduler) File "train.py", line 145, in train_model for inputs, age_labels, gender_labels in
-
Pytorch 数据加载与数据预处理方式
数据加载分为加载torchvision.datasets中的数据集以及加载自己使用的数据集两种情况. torchvision.datasets中的数据集 torchvision.datasets中自带MNIST,Imagenet-12,CIFAR等数据集,所有的数据集都是torch.utils.data.Dataset的子类,都包含 _ _ len _ (获取数据集长度)和 _ getItem _ _ (获取数据集中每一项)两个子方法. Dataset源码如上,可以看到其中包含了两个没有实现的子
-

Python Pytorch深度学习之数据加载和处理
目录 一.下载安装包 二.下载数据集 三.读取数据集 四.编写一个函数看看图像和landmark 五.数据集类 六.数据可视化 七.数据变换 1.Function_Rescale 2.Function_RandomCrop 3.Function_ToTensor 八.组合转换 九.迭代数据集 总结 一.下载安装包 packages: scikit-image:用于图像测IO和变换 pandas:方便进行csv解析 二.下载数据集 数据集说明:该数据集(我在这)是imagenet数据集标注为fac
-
Python Pytorch深度学习之图像分类器
目录 一.简介 二.数据集 三.训练一个图像分类器 1.导入package吧 2.归一化处理+贴标签吧 3.先来康康训练集中的照片吧 4.定义一个神经网络吧 5.定义一个损失函数和优化器吧 6.训练网络吧 7.在测试集上测试一下网络吧 8.分别查看一下训练效果吧 总结 一.简介 通常,当处理图像.文本.语音或视频数据时,可以使用标准Python将数据加载到numpy数组格式,然后将这个数组转换成torch.*Tensor 对于图像,可以用Pillow,OpenCV 对于语音,可以用scipy,l
-
Python Pytorch深度学习之核心小结
目录 一.Numpy实现网络 二.Pytorch:Tensor 三.自动求导 1.PyTorch:Tensor和auto_grad 总结 Pytorch的核心是两个主要特征: 1.一个n维tensor,类似于numpy,但是tensor可以在GPU上运行 2.搭建和训练神经网络时的自动微分/求导机制 一.Numpy实现网络 在总结Tensor之前,先使用numpy实现网络.numpy提供了一个n维数组对象,以及许多用于操作这些数组的函数. import numpy as np # n是批量大小,
-
Python Pytorch深度学习之自动微分
目录 一.简介 二.TENSOR 三.梯度 四.Example--雅克比向量积 总结 一.简介 antograd包是Pytorch中所有神经网络的核心.autograd为Tensor上的所有操作提供自动微分,它是一个由运行定义的框架,这意味着以代码运行方式定义后向传播,并且每一次迭代都可能不同 二.TENSOR torch.Tensor是包的核心. 1.如果将属性.requires_grad设置为True,则会开始跟踪针对tensor的所有操作. 2.完成计算之后,可以调用backward()来
-
Python Pytorch深度学习之神经网络
目录 一.简介 二.神经网络训练过程 2.通过调用net.parameters()返回模型可训练的参数 3.迭代整个输入 4.调用反向传播 5.计算损失值 6.反向传播梯度 7.更新神经网络参数 总结 一.简介 神经网络可以通过torch.nn包构建,上一节已经对自动梯度有些了解,神经网络是基于自动梯度来定义一些模型.一个nn.Module包括层和一个方法,它会返回输出.例如:数字图片识别的网络: 上图是一个简单的前回馈神经网络,它接收输入,让输入一个接着一个通过一些层,最后给出输出. 二.神经
-
Python Pytorch深度学习之Tensors张量
目录 一.Tensor(张量) 二.操作 总结 环境:Anaconda自带的编译器--Spyder 最近才开使用conda,发现conda 就是 yyds,爱啦~ 一.Tensor(张量) import torch #构造一个5*3的空矩阵 x=torch.FloatTensor(5,3) print(x) # 构造随机初始化矩阵 x=torch.rand(5,3) print(x) # 构造一个矩阵全为0,而且数据类型为long x=torch.zeros(5,3,dtype=torch.lo
-
python机器学习pytorch自定义数据加载器
目录 正文 1. 加载数据集 2. 迭代和可视化数据集 3.创建自定义数据集 3.1 __init__ 3.2 __len__ 3.3 __getitem__ 4. 使用 DataLoaders 为训练准备数据 5.遍历 DataLoader 正文 处理数据样本的代码可能会逐渐变得混乱且难以维护:理想情况下,我们希望我们的数据集代码与我们的模型训练代码分离,以获得更好的可读性和模块化.PyTorch 提供了两个数据原语:torch.utils.data.DataLoader和torch.util
-
PyTorch深度学习模型的保存和加载流程详解
一.模型参数的保存和加载 torch.save(module.state_dict(), path):使用module.state_dict()函数获取各层已经训练好的参数和缓冲区,然后将参数和缓冲区保存到path所指定的文件存放路径(常用文件格式为.pt..pth或.pkl). torch.nn.Module.load_state_dict(state_dict):从state_dict中加载参数和缓冲区到Module及其子类中 . torch.nn.Module.state_dict()函数
-
pytorch 数据加载性能对比分析
传统方式需要10s,dat方式需要0.6s import os import time import torch import random from common.coco_dataset import COCODataset def gen_data(batch_size,data_path,target_path): os.makedirs(target_path,exist_ok=True) dataloader = torch.utils.data.DataLoader(COCODat
-
利用python进行数据加载
前言 最近参加了datawhale的组队学习活动,在组队学习动员下,开始通过强迫自己输出来实现更好的输入与处理,6-15开始自己的第一次文章发布,我会把自己这个真的很小白遇到的问题写出来,希望能给屏幕前小白的你带来帮助. 工作中大量繁琐的自动化,把以前在学校摸过的python重新捡起来,不成体系的.拼图一样把需要的工作搭建起来,工作暂时是可用上了,每天节省了至少3个小时的数据处理工作,手里拿着python这个锤子,看什么都像钉子. 首先,你要先学会安装软件,anaconda软件,安装成功后,你点