详解使用Python+Pycaret进行异常检测
目录
- 概述
- 介绍
- 为什么是PyCaret
- 学习目标
- PyCaret安装
- 数据导入
- 探索性异常检测分析
- Swarm图
- 箱形图
- 散点图
- 异常检测
- 模型创建
- 隔离森林
- 局部异常因子
- K最近邻
- 比较模型中的异常
- 解释和可视化
- 尾注
概述
1.通过探索性异常检测分析了解异常
2.设置 PyCaret 环境并尝试准备任务的各种数据
3.比较性能并可视化不同的异常检测算法
介绍
异常检测提供了在数据中发现模式、偏差和异常的途径,这些模式、偏差和异常不限于模型的标准行为。异常检测旨在确定数据中的异常情况。这些异常也被称为数据集的异常值。
随着数据呈指数级增长,分析数据并得出形成重要业务决策基础的见解已成为一种普遍趋势。我们不仅需要分析数据,还需要准确地解释数据。找出异常并确定异常行为可以让我们找到最佳解决方案。
异常检测可以应用于各种领域。下面列出了其中一些。
- 网络安全 — 监控网络流量并确定异常值
- 欺诈检测—— 可以识别信用卡欺诈
- IT 部门 —发现并应对意外风险
- 银行业务—— 确定异常交易行为
许多机器学习算法可用于异常检测,它在检测和分类复杂数据集中的异常值方面起着至关重要的作用。
为什么是PyCaret
PyCaret是一个开源、低代码的 Python 机器学习库,支持多种功能,例如在几行代码中就可以为部署建模的数据准备。
PyCaret 提供的一些的功能包括 -
- 它是一个灵活的低代码库,可以提高生产力,从而节省时间和精力。
- PyCaret 是一个简单易用的机器学习库,使我们能够在几分钟内执行 ML 任务。
- PyCaret 库允许自动化机器学习步骤,例如数据转换、准备、超参数调整和标准模型比较。
学习目标
- 执行探索性异常检测分析
- PyCaret 环境介绍
- 创建和选择最佳模型
- 比较模型中的异常
- 可视化和解释模型
PyCaret 安装
在你的 jupyter notebook 中安装最新版本的 Pycaret 并开始使用!
pip3 install pycaret
数据导入
让我们从 PyCaret 预先配置的数据集中导入一个常见的异常检测数据集,开始我们的动手项目。
导入必要的库
首先,导入整个项目所需的必要库。
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd import numpy as np
导入数据集
from pycaret.datasets import get_data all_datasets = get_data(‘index')
现在我们可以看到所有列出的具有默认机器学习任务的数据集。
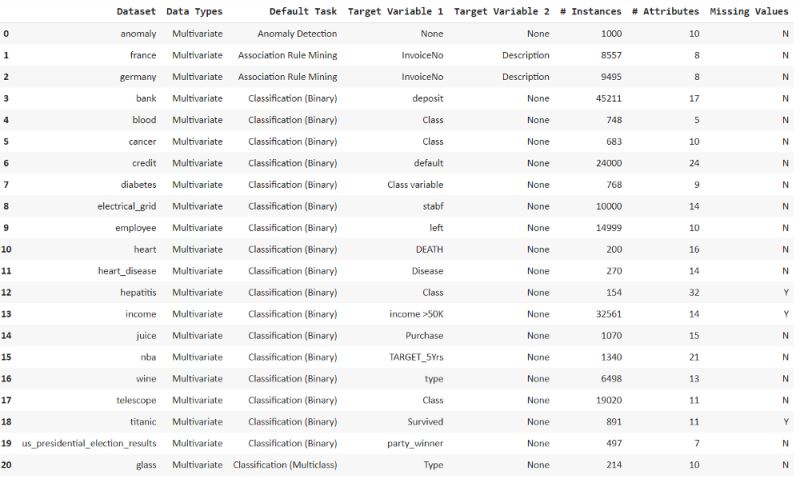
我们只需要访问通过get_data()函数可以获得的异常数据。
df = get_data(‘anomaly') df.head()

探索和描述此数据集以查找缺失值并获得统计分布。
df.describe() df.info()
我们可以注意到数据集没有任何缺失值。
探索性异常检测分析
现在我们可以使用各种可视化方法来解释数据集中的异常值和异常。
我们可以从 Swarm 图开始
Swarm 图
使用melt()函数获取数据集的Swarm图。
plt.rcParams["figure.figsize"] = (10,8) sns.swarmplot(x="variable", y="value", data=pd.melt(df)) plt.show()
这是我们所有列的Swarm图

箱形图
通过箱形图可视化数据集,这让我们清楚地了解大部分数据所在的位置。
sns.boxplot(x="variable", y="value", data=pd.melt(df)) plt.show()
这些图将帮助我们感知我们的模型是否能够跟踪它们。

散点图
我们可以通过散点图确定两个特征之间的线性关系。此处明确定义了Col1和Col2之间的关系。
sns.scatterplot(data=df, x="Col1", y='Col2')

我们也可以尝试不同的特征。探索各种特征如何相互关联。
sns.scatterplot(data=df, x="Col3", y='Col4')

这些图表明数据之间没有线性关系。现在让我们使用 Seaborn 成对分析所有特征之间的关系。
sns.pairplot(df)

该成对图确定了不同列之间的关系以及它们如何与直方图一起以多种方式区分值。
通过这种方式,我们可以为我们的模型解释多个维度的边界。
df1 = df.melt(‘Col1', var_name='cols', value_name='vals') g = sns.factorplot(x=”Col1", y=”vals”, hue='cols', data=df1)
异常检测
为异常检测设置 PyCaret 环境。为此,我们可以使用 Pycaret 的异常检测模块,这是一个无监督的机器学习模块,用于识别数据中可能导致异常情况的异常值。
from pycaret.anomaly import * setup = setup(df, session_id = 123)

指定会话 id,这会导致执行后进行处理。它会自动解释多种类型的变量,并允许我们通过按ENTER进行确认。
观察我们的数据集由 10 个特征组成,每个特征 1000 行。我们可以执行各种插补——数字和分类或归一化数据。但是我们不需要在我们的数据集中进行这样的转换,所以让我们继续!
用几行代码执行所有这些计算显示了PyCaret库的美妙之处。
模型创建
从模型库中选择最佳模型并创建用于异常检测的模型。我们可以使用model()函数显示模型列表。
models()

我们可以看到列出了许多流行的算法,例如隔离森林和 k 最近邻。
隔离森林
使用create_model()函数创建隔离森林模型。隔离森林算法通过随机选择一个特征,然后随机选择最大值和最小值之间的分割值来区分观察。
iforest = create_model('iforest')
print(iforest)
因此,异常分数被确定为分离给定观察所需的条件数量。
局部异常因子
它是一种无监督异常检测方法的算法,计算数据点相对于其邻居的局部密度偏差。
lof = create_model('lof')
print(lof)
K最近邻
KNN 是一种非参数惰性学习算法,用于根据相似性和各种距离度量对数据进行分类。它提供了一种简单而可靠的方法来检测异常。
knn = create_model('knn')
print(knn)neighbours
比较模型中的异常
继续我们的任务,我们现在可以观察模型确定的异常情况。传统上,我们必须手动设置不同的参数。
但是通过使用 PyCaret,我们可以通过分配的模型函数来分配结果。我们将从隔离森林模型开始。
iforest_results = assign_model(iforest) iforest_results.head()
assign_model()函数返回一个检测异常的数据帧,异常值的存在标记为 1,非异常值标记为 0,以及异常分数。

同样,我们也可以分配其他模型。所以可以进行比较。
lof_results = assign_model(lof) lof_results.head()
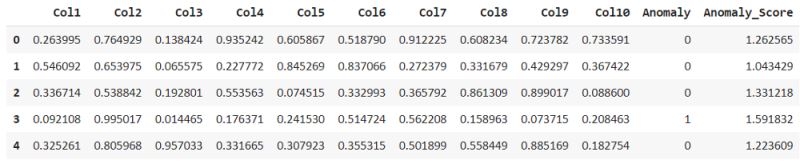
比较上述模型我们可以看到,隔离森林已经将第二行视为异常,但局部异常因子并未将其视为异常。但不同算法的异常得分不同。
对于 k 个最近邻,预测分数与隔离森林的预测分数非常相似。
knn_results = assign_model(knn) knn_results.head()

按每个模型过滤异常,这表明 iforest 模型将 1000 行中的 50 行视为异常。
iforest_anomaly=iforest_results[iforest_results['Anomaly']==1] iforest_anomaly.shape
同样,检查LOF和KNN,我们可以看到它们都考虑了50个异常。必须使用不同的计算方法来查找异常值。
lof_anomaly=lof_results[lof_results['Anomaly']==1] lof_anomaly.shape
knn_anomaly=knn_results[knn_results['Anomaly']==1] knn_anomaly.shape
根据以上结果,我们可以得出结论,1000 个异常中最有可能有 50 个。
验证的一种方法是分析它们中的哪一个更适合于对模型标记为离群值的数据进行分析,并比较它们对测试数据的影响,或者进行分析,看看它们是否位于决策边界内。
解释和可视化
可视化是以创造性和独立的方式解释手头信息的最便捷方式。
让我们首先从 PyCaret 库外部创建视觉效果,这将突出 PyCaret 库的好处,并使我们能够了解plot_model函数如何更具交互性。
from yellowbrick.features import Manifold dfr = iforest_results['Anomaly'] viz = Manifold(manifold="tsne") viz.fit_transform(df, dfr) viz.show()

我们可以看到,隔离森林在多个维度上确定的大多数异常通常来自不同的集群。
现在在PyCaret 中为 KNN使用plot_model() 函数,它将为异常值创建一个 3D 图,在其中我们可以看到为什么某些特征被视为异常。
plot_model(knn)
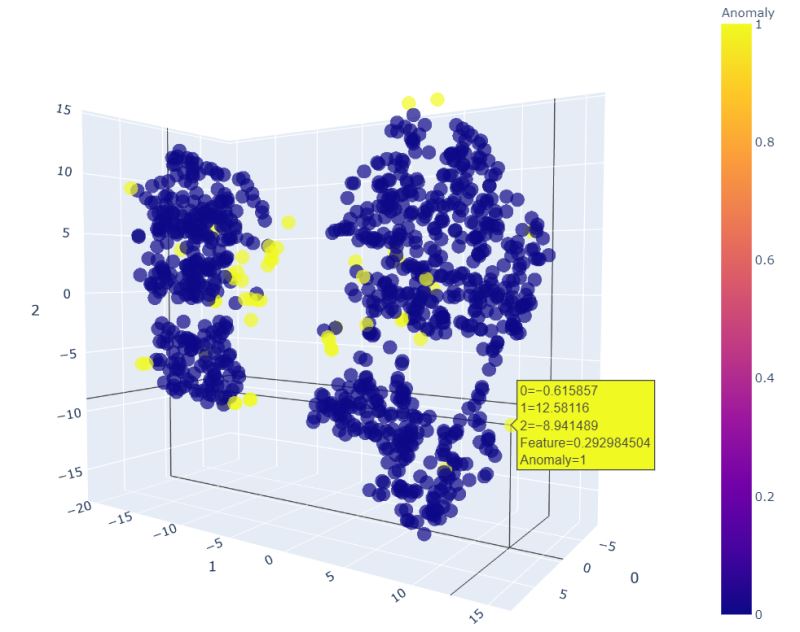
我们可以在任何维度上移动它以查看和指出异常。这个 3D 绘图有助于我们更好地查看它。KNN 图显示大多数异常值是那些不属于任何集群的异常值。所以这很好!
其他两个模型也可以这样做。
plot_model(iforest)

很明显,数据集被分成了四个不同的集群,所以这些组之外的任何东西都肯定是异常的。
异常并不总是坏兆头!有时它们在解释结果或数据分析方面非常有用。这些可用于解决不同的数据科学用例。
接下来是第三种模式。线性离群因子,我们可以用一个不同的图来实验,创造一个2D图。

我们可以放大这个二维图来查看哪些点被认为是异常值。
可以再次为配对图创建另一个视觉效果,现在使用异常来查看哪些点将被视为异常。
sns.pairplot(lof_results, hue = "Anomaly")

最后,我们可以保存模型。可以保存任何合适的模型。这里我们保存了 iforest 模型。
save_model(iforest,'IForest_Model')

模型与示例数据和日志一起成功保存。
尾注
这标志着我们关于异常检测的动手项目的结束。我们已经讨论了 PyCaret 库的用例和实现,以及它如何用于异常检测。PyCaret 是一个快速可靠的机器学习库,通常被数据科学家用来解决复杂的业务问题。在创建可部署模型的同时,可以扩展该项目进行进一步的实验和探索。
以上就是详解使用Python+Pycaret进行异常检测的详细内容,更多关于Python Pycaret异常检测的资料请关注我们其它相关文章!
相关推荐
-
Python实现非正太分布的异常值检测方式
工作中,我们经常会遇到数据异常,比如说浏览量突增猛降,交易量突增猛降,但是这些数据又不是符合正太分布的,如果用几倍西格玛就不合适,那么我们如何来判断这些变化是否在合理的范围呢? 小白查阅一些资料后,发现可以用箱形图,具体描述如下: 箱形图(英文:Box plot),又称为盒须图.盒式图.盒状图或箱线图,是一种用作显示一组数据分散情况资料的统计图.因型状如箱子而得名.箱形图最大的优点就是不受异常值的影响,能够准确稳定地描绘出数据的离散分布情况,同时也利于数据的清洗. 异常值可以设置为上四分位数的1
-
Python异常的检测和处理方法
捕获异常 # 对数字变量使用append操作 a = 123 a.apppend(4) 执行这个程序时,会抛出: AttributeError: 'int' object has no attribute 'apppend' 我们使用try:except语句进行捕获. # 捕获异常 a = 123 try: a.apppend(4) except AttributeError: print("数字类型不能使用append操作") 输出结果如下: 数字类型不能使用append操作 捕获多
-

pyCaret效率倍增开源低代码的python机器学习工具
目录 PyCaret 时间序列模块 加载数据 初始化设置 统计测试 探索性数据分析 模型训练和选择 保存模型 PyCaret 是一个开源.低代码的 Python 机器学习库,可自动执行机器学习工作流.它是一种端到端的机器学习和模型管理工具,可以以指数方式加快实验周期并提高您的工作效率.欢迎收藏学习,喜欢点赞支持,文末提供技术交流群. 与其他开源机器学习库相比,PyCaret 是一个替代的低代码库,可用于仅用几行代码替换数百行代码. 这使得实验速度和效率呈指数级增长. PyCaret 本质上是围绕
-
详解使用Python+Pycaret进行异常检测
目录 概述 介绍 为什么是PyCaret 学习目标 PyCaret安装 数据导入 探索性异常检测分析 Swarm图 箱形图 散点图 异常检测 模型创建 隔离森林 局部异常因子 K最近邻 比较模型中的异常 解释和可视化 尾注 概述 1.通过探索性异常检测分析了解异常 2.设置 PyCaret 环境并尝试准备任务的各种数据 3.比较性能并可视化不同的异常检测算法 介绍 异常检测提供了在数据中发现模式.偏差和异常的途径,这些模式.偏差和异常不限于模型的标准行为.异常检测旨在确定数据中的异常情况.这些异
-
详解在Python中处理异常的教程
什么是异常? 异常是一个事件,其中一个程序,破坏程序的指令的正常流的执行过程中而发生的.一般情况下,当一个Python脚本遇到一些情况不能处理,就抛出一个异常.异常是一个Python对象,它表示一个错误. 当Python脚本抛出一个异常,它必须处理异常,否则将立即终止. 处理异常: 如果有可能会引发异常的一些可疑的代码,就可以通过将可疑的代码在一个try块:保卫你的程序.在try块,包括以下情况except:语句,其次是代码,作为优雅的处理问题,尽可能块. 语法 这里是try....except
-
详解在Python中使用OpenCV进行直线检测
目录 1.引言 2.霍夫变换 3.举个栗子 3.1读入图像进行灰度化 3.2执行边缘检测 3.3进行霍夫变换 补充 1. 引言 在图像处理中,直线检测是一种常见的算法,它通常获取n个边缘点的集合,并找到通过这些边缘点的直线.其中用于直线检测,最为流行的检测器是基于霍夫变换的直线检测技术. 2. 霍夫变换 霍夫变换是图像处理中的一种特征提取方法,可以识别图像中的几何形状.它将在参数空间内进行投票来决定其物体形状,通过检测累计结果找到一极大值所对应的解,利用此解即可得到一个符合特定形状的参数. 在使
-
详解使用Python写一个向数据库填充数据的小工具(推荐)
一. 背景 公司又要做一个新项目,是一个合作型项目,我们公司出web展示服务,合作伙伴线下提供展示数据. 而且本次项目是数据统计展示为主要功能,并没有研发对应的数据接入接口,所有展示数据源均来自数据库查询, 所以验证数据没有别的入口,只能通过在数据库写入数据来进行验证. 二. 工具 Python+mysql 三.前期准备 前置:当然是要先准备好测试方案和测试用例,在准备好这些后才能目标明确将要开发自动化小工具都要有哪些功能,避免走弯路 3.1 跟开发沟通 1)确认数据库连接方式,库名 : 2)测
-
详解利用Python制作中文汉字雨效果
直接上代码 import pygame import random def main(): # 初始化pygame pygame.init() # 默认不全屏 fullscreen = False # 窗口未全屏宽和高 WIDTH, HEIGHT = 1100, 600 init_width, init_height = WIDTH, HEIGHT # 字块大小,宽,高 suface_height = 18 # 字体大小 font_size = 20 # 创建一个窗口 screen = pyga
-
详解使用python的logging模块在stdout输出的两种方法
详解使用python的logging模块在stdout输出 前言: 使用python的logging模块时,除了想将日志记录在文件中外,还希望在前台执行python脚本时,可以将日志直接输出到标准输出std.out中. 实现 logging模块可以有两种方法实现该功能: 方案一:basicconfig import sys import logging logging.basicConfig(stream=sys.stdout, level=logging.DEBUG) 方案二:handler
-
基于YUV 数据格式详解及python实现方式
YUV 数据格式概览 YUV 的原理是把亮度与色度分离,使用 Y.U.V 分别表示亮度,以及蓝色通道与亮度的差值和红色通道与亮度的差值.其中 Y 信号分量除了表示亮度 (luma) 信号外,还含有较多的绿色通道量,单纯的 Y 分量可以显示出完整的黑白图像.U.V 分量分别表示蓝 (blue).红 (red) 分量信号,它们只含有色彩 (chrominance/color) 信息,所以 YUV 也称为 YCbCr,C 意思可以理解为 (component 或者 color). 维基百科上的 RGB
-
详解用Python进行时间序列预测的7种方法
数据准备 数据集(JetRail高铁的乘客数量)下载. 假设要解决一个时序问题:根据过往两年的数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量. import pandas as pd import numpy as np import matplotlib.pyplot as plt df = pd.read_csv('train.csv') df.head() df.shape 依照上面的代码,我们获得了 2012-2014 年两年每个小时的乘
-
详解用Python爬虫获取百度企业信用中企业基本信息
一.背景 希望根据企业名称查询其经纬度,所在的省份.城市等信息.直接将企业名称传给百度地图提供的API,得到的经纬度是非常不准确的,因此希望获取企业完整的地理位置,这样传给API后结果会更加准确. 百度企业信用提供了企业基本信息查询的功能.希望通过Python爬虫获取企业基本信息.目前已基本实现了这一需求. 本文最后会提供具体的代码.代码仅供学习参考,希望不要恶意爬取数据! 二.分析 以苏宁为例.输入"江苏苏宁"后,查询结果如下: 经过分析,这里列示的企业信息是用JavaScript动
-
详解在Python中使用Torchmoji将文本转换为表情符号
很难找到关于如何使用Python使用DeepMoji的教程.我已经尝试了几次,后来又出现了几次错误,于是决定使用替代版本:torchMoji. TorchMoji是DeepMoji的pyTorch实现,可以在这里找到:https://github.com/huggingface/torchMoji 事实上,我还没有找到一个关于如何将文本转换为表情符号的教程.如果你也没找到,那么本文就是一个了. 安装 这些代码并不完全是我的写的,源代码可以在这个链接上找到. pip3 install torch=