Python OpenCV实现姿态识别的详细代码
目录
- 前言
- 环境安装
- 下载并安装Anaconda
- 安装JupyterNotebook
- 生成JupyterNotebook项目目录
- 下载训练库
- 单张图片识别
- 导入库
- 加载训练模型
- 初始化
- 载入图片
- 显示图片
- 调整图片颜色
- 姿态识别
- 视频识别
- 实时摄像头识别
- 参考
前言
想要使用摄像头实现一个多人姿态识别
环境安装
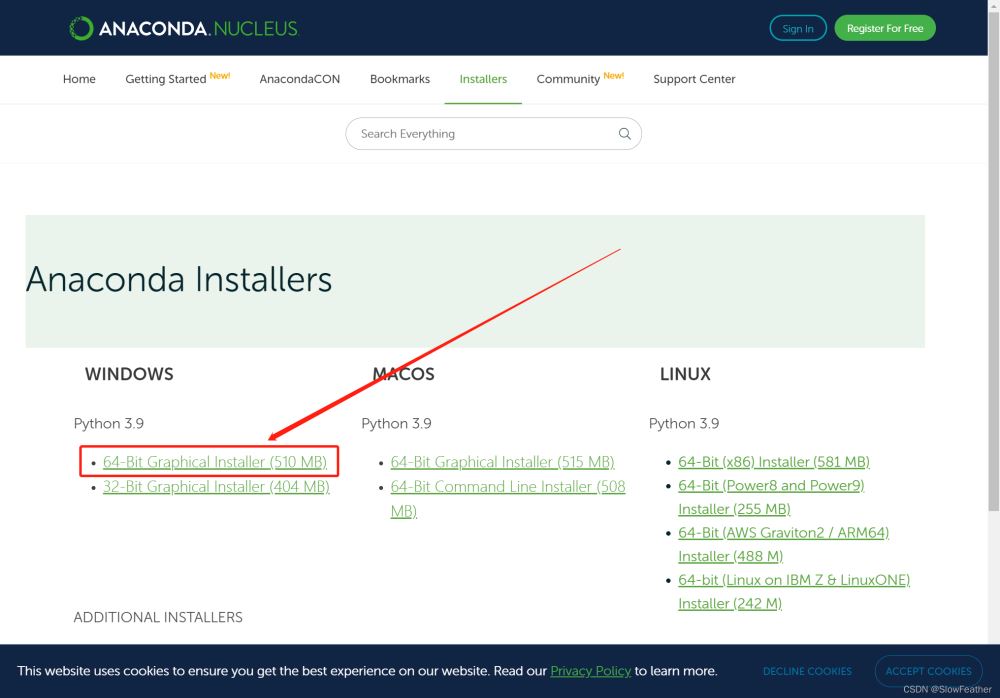
下载并安装 Anaconda
官网连接 https://anaconda.cloud/installers
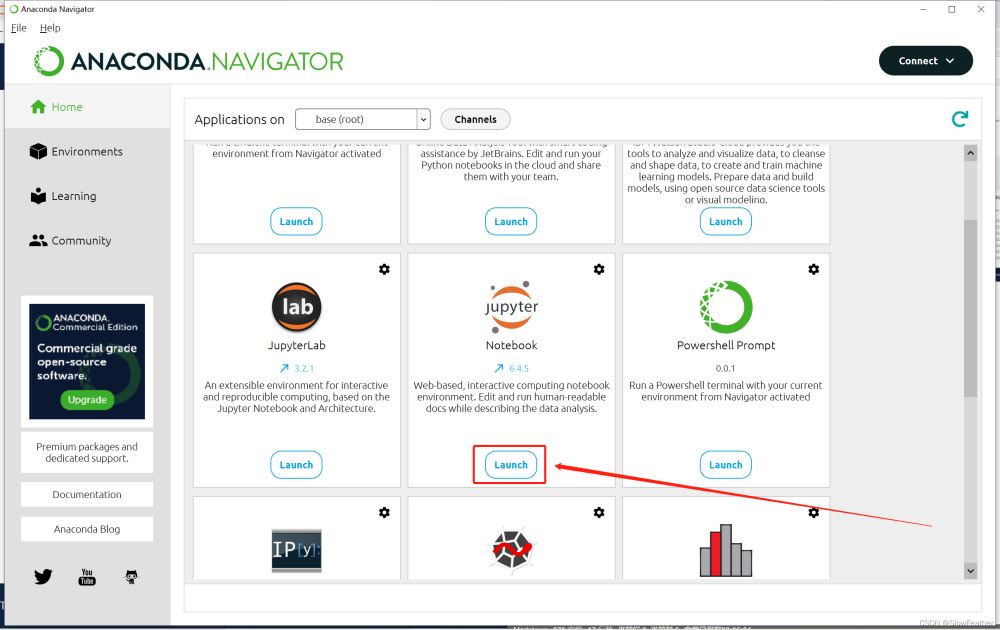
安装 Jupyter Notebook
检查Jupyter Notebook是否安装
Tip:这里涉及到一个切换Jupyter Notebook内核的问题,在我这篇文章中有提到
AnacondaNavigator Jupyter Notebook更换Python内核https://www.jb51.net/article/238496.htm
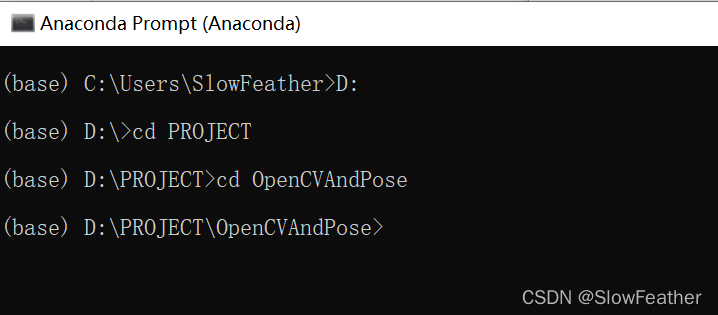
生成Jupyter Notebook项目目录
打开Anaconda Prompt切换到项目目录
输入Jupyter notebook在浏览器中打开 Jupyter Notebook
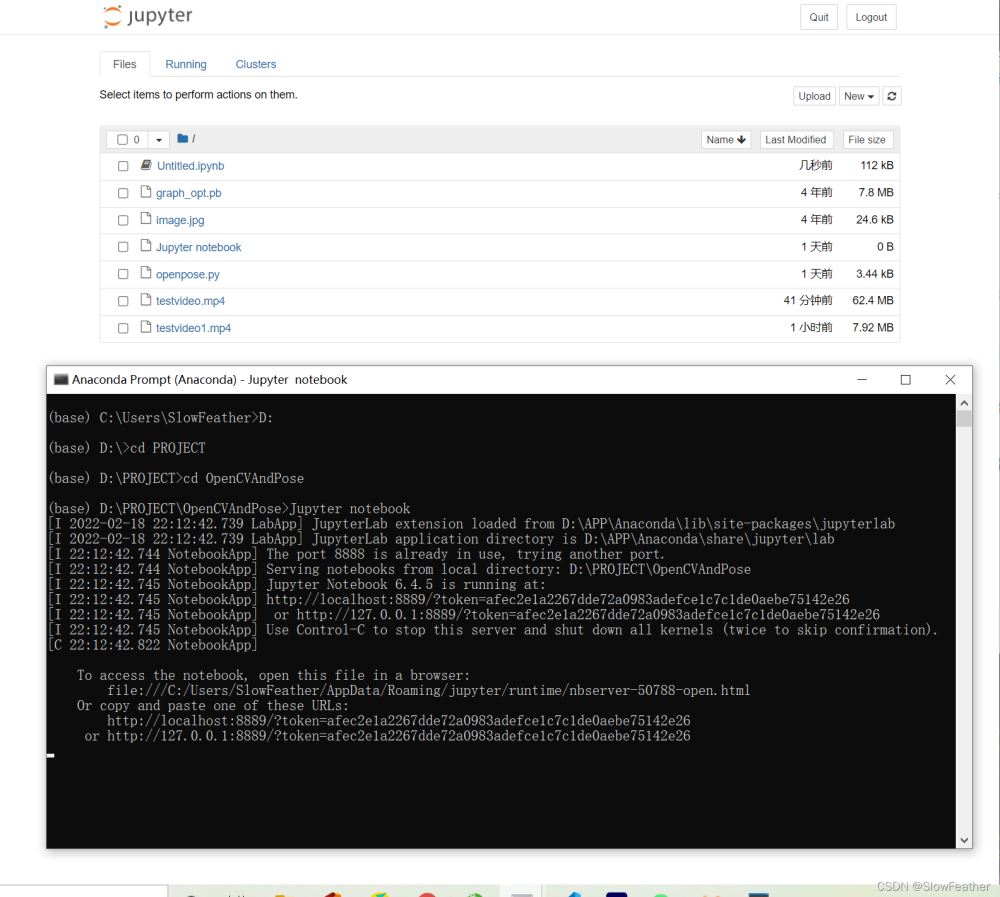
并创建新的记事本
下载训练库
图片以及训练库都在下方链接
https://github.com/quanhua92/human-pose-estimation-opencv
将图片和训练好的模型放到项目路径中graph_opt.pb为训练好的模型
单张图片识别
导入库
import cv2 as cv import os import matplotlib.pyplot as plt
加载训练模型
net=cv.dnn.readNetFromTensorflow("graph_opt.pb")
初始化
inWidth=368
inHeight=368
thr=0.2
BODY_PARTS = { "Nose": 0, "Neck": 1, "RShoulder": 2, "RElbow": 3, "RWrist": 4,
"LShoulder": 5, "LElbow": 6, "LWrist": 7, "RHip": 8, "RKnee": 9,
"RAnkle": 10, "LHip": 11, "LKnee": 12, "LAnkle": 13, "REye": 14,
"LEye": 15, "REar": 16, "LEar": 17, "Background": 18 }
POSE_PAIRS = [ ["Neck", "RShoulder"], ["Neck", "LShoulder"], ["RShoulder", "RElbow"],
["RElbow", "RWrist"], ["LShoulder", "LElbow"], ["LElbow", "LWrist"],
["Neck", "RHip"], ["RHip", "RKnee"], ["RKnee", "RAnkle"], ["Neck", "LHip"],
["LHip", "LKnee"], ["LKnee", "LAnkle"], ["Neck", "Nose"], ["Nose", "REye"],
["REye", "REar"], ["Nose", "LEye"], ["LEye", "LEar"] ]
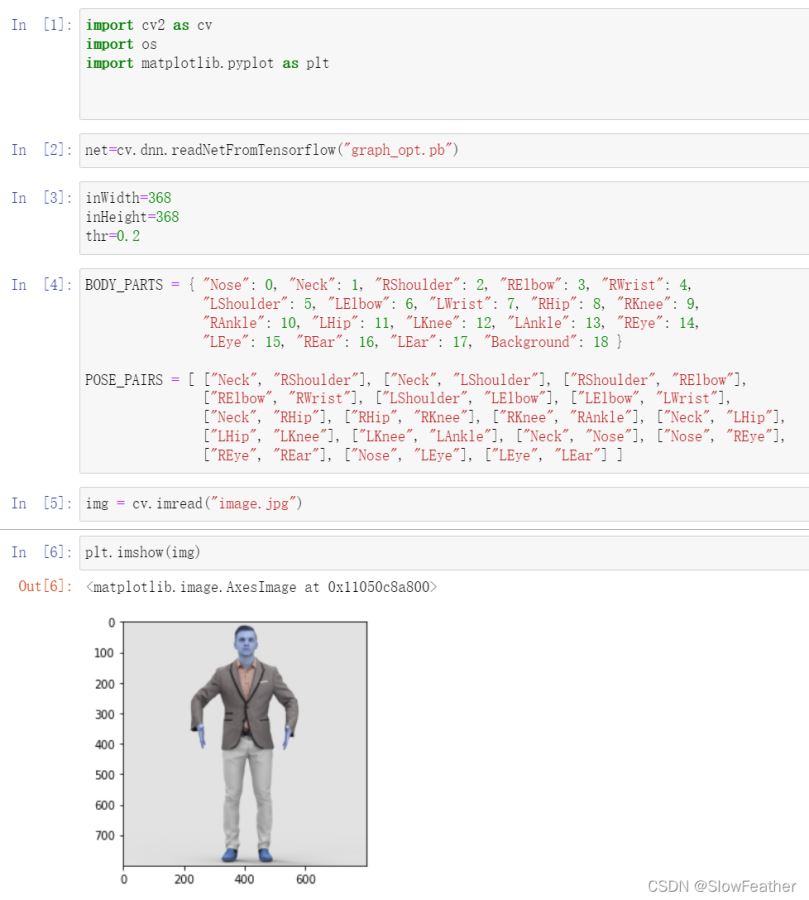
载入图片
img = cv.imread("image.jpg")
显示图片
plt.imshow(img)
调整图片颜色
plt.imshow(cv.cvtColor(img,cv.COLOR_BGR2RGB))

姿态识别
def pose_estimation(frame):
frameWidth=frame.shape[1]
frameHeight=frame.shape[0]
net.setInput(cv.dnn.blobFromImage(frame, 1.0, (inWidth, inHeight), (127.5, 127.5, 127.5), swapRB=True, crop=False))
out = net.forward()
out = out[:, :19, :, :] # MobileNet output [1, 57, -1, -1], we only need the first 19 elements
assert(len(BODY_PARTS) == out.shape[1])
points = []
for i in range(len(BODY_PARTS)):
# Slice heatmap of corresponging body's part.
heatMap = out[0, i, :, :]
# Originally, we try to find all the local maximums. To simplify a sample
# we just find a global one. However only a single pose at the same time
# could be detected this way.
_, conf, _, point = cv.minMaxLoc(heatMap)
x = (frameWidth * point[0]) / out.shape[3]
y = (frameHeight * point[1]) / out.shape[2]
# Add a point if it's confidence is higher than threshold.
points.append((int(x), int(y)) if conf > thr else None)
for pair in POSE_PAIRS:
partFrom = pair[0]
partTo = pair[1]
assert(partFrom in BODY_PARTS)
assert(partTo in BODY_PARTS)
idFrom = BODY_PARTS[partFrom]
idTo = BODY_PARTS[partTo]
# 绘制线条
if points[idFrom] and points[idTo]:
cv.line(frame, points[idFrom], points[idTo], (0, 255, 0), 3)
cv.ellipse(frame, points[idFrom], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
cv.ellipse(frame, points[idTo], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
t, _ = net.getPerfProfile()
freq = cv.getTickFrequency() / 1000
cv.putText(frame, '%.2fms' % (t / freq), (10, 20), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
return frame
# 处理图片
estimated_image=pose_estimation(img)
# 显示图片
plt.imshow(cv.cvtColor(estimated_image,cv.COLOR_BGR2RGB))

视频识别
Tip:与上面图片识别代码是衔接的
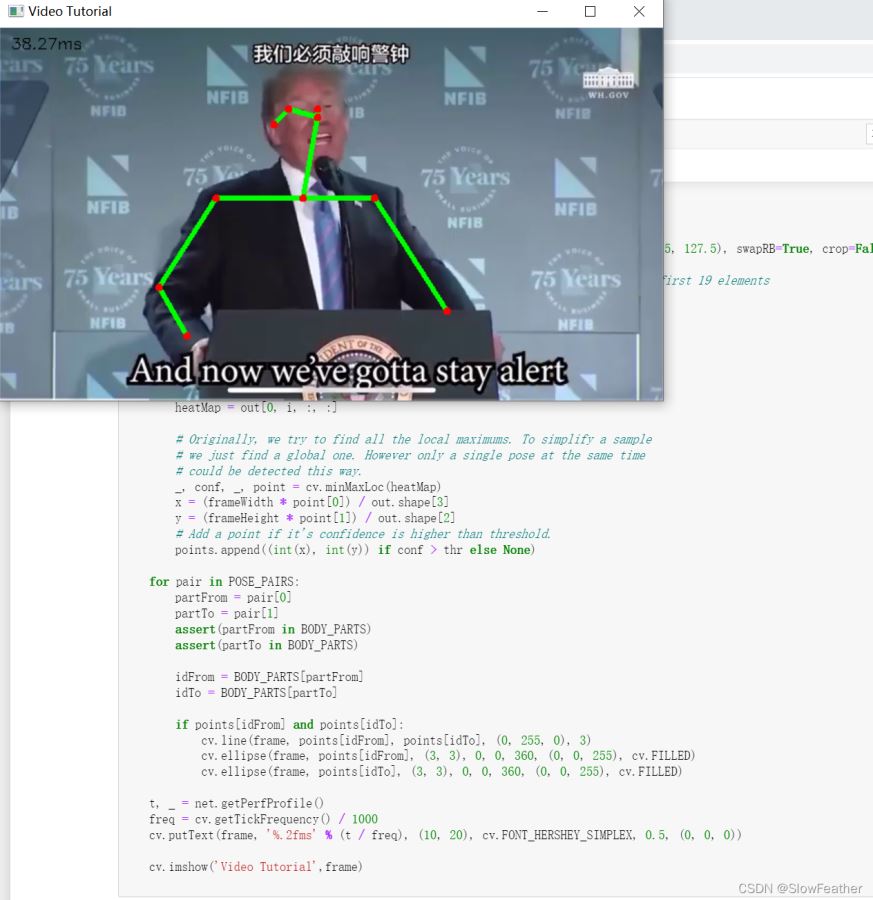
视频来自互联网,侵删
cap = cv.VideoCapture('testvideo.mp4')
cap.set(3,800)
cap.set(4,800)
if not cap.isOpened():
cap=cv.VideoCapture(0)
raise IOError("Cannot open vide")
while cv.waitKey(1) < 0:
hasFrame,frame=cap.read()
if not hasFrame:
cv.waitKey()
break
frameWidth=frame.shape[1]
frameHeight=frame.shape[0]
net.setInput(cv.dnn.blobFromImage(frame, 1.0, (inWidth, inHeight), (127.5, 127.5, 127.5), swapRB=True, crop=False))
out = net.forward()
out = out[:, :19, :, :] # MobileNet output [1, 57, -1, -1], we only need the first 19 elements
assert(len(BODY_PARTS) == out.shape[1])
points = []
for i in range(len(BODY_PARTS)):
# Slice heatmap of corresponging body's part.
heatMap = out[0, i, :, :]
# Originally, we try to find all the local maximums. To simplify a sample
# we just find a global one. However only a single pose at the same time
# could be detected this way.
_, conf, _, point = cv.minMaxLoc(heatMap)
x = (frameWidth * point[0]) / out.shape[3]
y = (frameHeight * point[1]) / out.shape[2]
# Add a point if it's confidence is higher than threshold.
points.append((int(x), int(y)) if conf > thr else None)
for pair in POSE_PAIRS:
partFrom = pair[0]
partTo = pair[1]
assert(partFrom in BODY_PARTS)
assert(partTo in BODY_PARTS)
idFrom = BODY_PARTS[partFrom]
idTo = BODY_PARTS[partTo]
if points[idFrom] and points[idTo]:
cv.line(frame, points[idFrom], points[idTo], (0, 255, 0), 3)
cv.ellipse(frame, points[idFrom], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
cv.ellipse(frame, points[idTo], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
t, _ = net.getPerfProfile()
freq = cv.getTickFrequency() / 1000
cv.putText(frame, '%.2fms' % (t / freq), (10, 20), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
cv.imshow('Video Tutorial',frame)
实时摄像头识别
Tip:与上面图片识别代码是衔接的
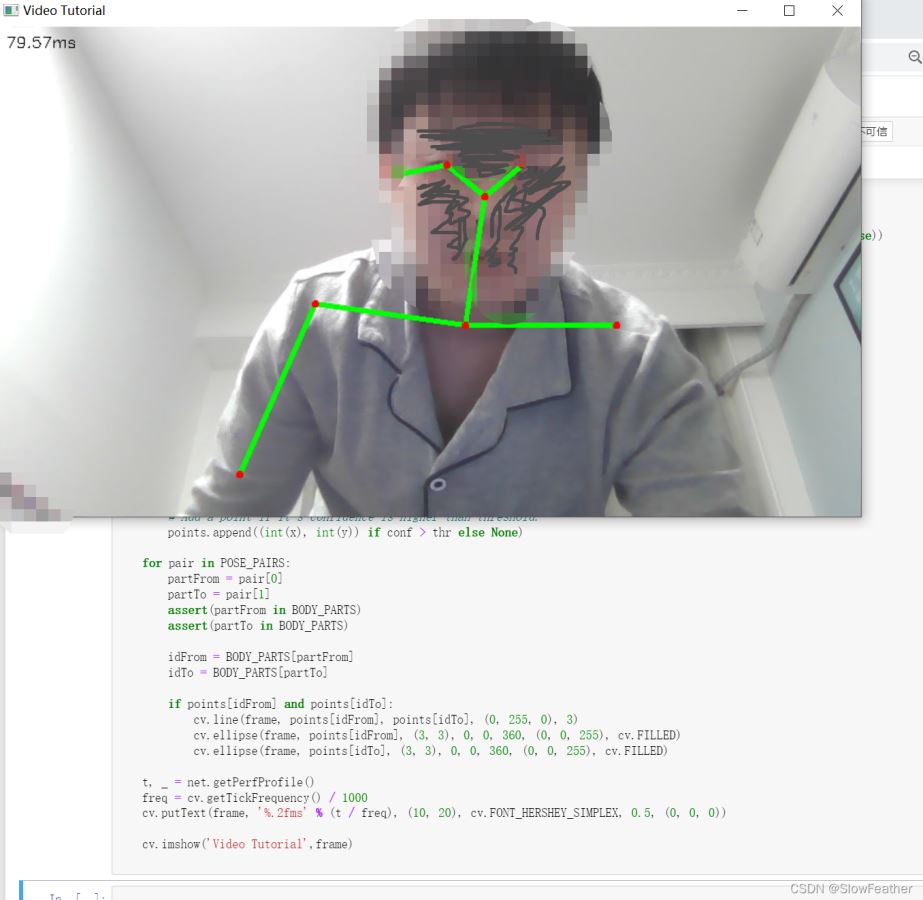
cap = cv.VideoCapture(0)
cap.set(cv.CAP_PROP_FPS,10)
cap.set(3,800)
cap.set(4,800)
if not cap.isOpened():
cap=cv.VideoCapture(0)
raise IOError("Cannot open vide")
while cv.waitKey(1) < 0:
hasFrame,frame=cap.read()
if not hasFrame:
cv.waitKey()
break
frameWidth=frame.shape[1]
frameHeight=frame.shape[0]
net.setInput(cv.dnn.blobFromImage(frame, 1.0, (inWidth, inHeight), (127.5, 127.5, 127.5), swapRB=True, crop=False))
out = net.forward()
out = out[:, :19, :, :] # MobileNet output [1, 57, -1, -1], we only need the first 19 elements
assert(len(BODY_PARTS) == out.shape[1])
points = []
for i in range(len(BODY_PARTS)):
# Slice heatmap of corresponging body's part.
heatMap = out[0, i, :, :]
# Originally, we try to find all the local maximums. To simplify a sample
# we just find a global one. However only a single pose at the same time
# could be detected this way.
_, conf, _, point = cv.minMaxLoc(heatMap)
x = (frameWidth * point[0]) / out.shape[3]
y = (frameHeight * point[1]) / out.shape[2]
# Add a point if it's confidence is higher than threshold.
points.append((int(x), int(y)) if conf > thr else None)
for pair in POSE_PAIRS:
partFrom = pair[0]
partTo = pair[1]
assert(partFrom in BODY_PARTS)
assert(partTo in BODY_PARTS)
idFrom = BODY_PARTS[partFrom]
idTo = BODY_PARTS[partTo]
if points[idFrom] and points[idTo]:
cv.line(frame, points[idFrom], points[idTo], (0, 255, 0), 3)
cv.ellipse(frame, points[idFrom], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
cv.ellipse(frame, points[idTo], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
t, _ = net.getPerfProfile()
freq = cv.getTickFrequency() / 1000
cv.putText(frame, '%.2fms' % (t / freq), (10, 20), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
cv.imshow('Video Tutorial',frame)
参考
DeepLearning_by_PhDScholar
Human Pose Estimation using opencv | python | OpenPose | stepwise implementation for beginners
https://www.youtube.com/watch?v=9jQGsUidKHs
到此这篇关于Python OpenCV实现姿态识别的文章就介绍到这了,更多相关Python姿态识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python基于pyopencv人脸识别并绘制GUI界面
目录 项目介绍 采集人脸: 识别功能: 项目思路 项目模块 1.人脸采集 2.数据训练 3.人脸识别 4.GUI界面 项目代码 人脸采集 数据训练 人脸识别 合并GUI 项目总结 项目介绍 我们先来看看成果: 首先写了一个能够操作的GUI界面. 其中两个按钮对应相应的功能: 采集人脸: 识别功能: 我可是牺牲了色相五五五五...(电脑像素不是很好大家将就一下嘿嘿嘿) 项目思路 本项目是借助于python的一个cv2图像识别库,通过调取电脑的摄像头进行识别人脸并保存人脸图片的功能,然后在通过cv2
-
Python+OpenCV进行人脸面部表情识别
目录 前言 一.图片预处理 二.数据集划分 三.识别笑脸 四.Dlib提取人脸特征识别笑脸和非笑脸 前言 环境搭建可查看Python人脸识别微笑检测 数据集可在https://inc.ucsd.edu/mplab/wordpress/index.html%3Fp=398.html获取 数据如下: 一.图片预处理 import dlib # 人脸识别的库dlib import numpy as np # 数据处理的库numpy import cv2 # 图像处理的库OpenCv import os
-
python+mediapipe+opencv实现手部关键点检测功能(手势识别)
目录 一.mediapipe是什么? 二.使用步骤 1.引入库 2.主代码 3.识别结果 补充: 一.mediapipe是什么? mediapipe官网 二.使用步骤 1.引入库 代码如下: import cv2 from mediapipe import solutions import time 2.主代码 代码如下: cap = cv2.VideoCapture(0) mpHands = solutions.hands hands = mpHands.Hands() mpDraw = so
-
Python OpenCV机器学习之图像识别详解
目录 背景 一.人脸识别 二.车牌识别 三.DNN图像分类 背景 OpenCV中也提供了一些机器学习的方法,例如DNN:本篇将简单介绍一下机器学习的一些应用,对比传统和前沿的算法,能从其中看出优劣: 一.人脸识别 主要有以下两种实现方法: 1.哈尔(Haar)级联法:专门解决人脸识别而推出的传统算法: 实现步骤: 创建Haar级联器: 导入图片并将其灰度化: 调用函数接口进行人脸识别: 函数原型: detectMultiScale(img,scaleFactor,minNeighbors) sc
-
Python OpenCV实现姿态识别的详细代码
目录 前言 环境安装 下载并安装Anaconda 安装JupyterNotebook 生成JupyterNotebook项目目录 下载训练库 单张图片识别 导入库 加载训练模型 初始化 载入图片 显示图片 调整图片颜色 姿态识别 视频识别 实时摄像头识别 参考 前言 想要使用摄像头实现一个多人姿态识别 环境安装 下载并安装 Anaconda 官网连接 https://anaconda.cloud/installers 安装 Jupyter Notebook 检查Jupyter Notebook是
-
Python+OpenCV六种实时图像处理详细讲解
目录 1.导入库文件 2.设计GUI 3.调用摄像头 4.实时图像处理 4.1.阈值二值化 4.2.边缘检测 4.3.轮廓检测 4.4.高斯滤波 4.5.色彩转换 4.6.调节对比度 5.退出系统 初学OpenCV图像处理的小伙伴肯定对什么高斯函数.滤波处理.阈值二值化等特性非常头疼,这里给各位分享一个小项目,可通过摄像头实时动态查看各类图像处理的特点,也可对各位调参.测试有一定帮助. 1.导入库文件 这里主要使用PySimpleGUI.cv2和numpy库文件,PySimpleGUI库文件实现
-
python链接sqlite数据库的详细代码实例
一.创建数据库 创建sqlite数据库的代码 import sqlite3 conn = sqlite3.connect("test.db") print("成功创建数据库") 运行代码后左侧文件栏中会出现"test.db"文件, 二.链接数据库 视图->工具窗口->Database 此时编辑器右侧出现Database,点击添加按钮 点击路径选择按钮,找到创建好的"test.db"文件,选中 注意:Download
-
python解析.pyd文件的详细代码
有的时候,为了对python文件进行加密,会把python模块编译成.pyd文件,供其他人调用.拿到一个.pyd文件,在没有文档说明的情况下,可以试试查看模块内的一些函数和类的用法. 首先 import XXX(pyd的文件名) 然后直接 print(dir(XXX)) print(help(xxx)) 其中dir( ) 列出了属性和方法 而hlep()直接列出了其中的函数以及参数,并且是源码的函数名和类型,非常直观. 例如我这里的一个例子,输出如下: ['RC', '__doc__', '__
-
python turtle库画圣诞树详细代码教程
目录 1. 圣诞树的本体 2. 蝴蝶结 3. 星星 4. 圣诞帽 5. 圣诞袜 6. 最后奉上完整代码 首先我们的目标是这样子的: 那么他有什么成分呢?有圣诞树的本体.大小蝴蝶结.星星.圣诞帽和袜子. 首先我们来画圣诞树的本体. 1. 圣诞树的本体 圣诞树本体是这样子的: 代码: class TreeBackBone(): def __init__(self): pencolor("pink") pensize(10) self.layer1() self.layer2() self.
-
Python实现迷宫生成器的详细代码
作为一项古老的智力游戏,千百年来迷宫都散发着迷人的魅力.但是,手工设计迷宫费时又耗(脑)力,于是,我们有必要制作一个程序:迷宫生成器…… 好吧,我编不下去了.但是,从上面的文字中,我们可以看出,我们此次的主题是:用Python实现一个迷宫生成器. 首先展示一下效果图: 我们先分析一下所需的库: 既然是生成器,每次生成的迷宫一模一样显然是说不过去的.因此,我们不可避免地要使用随机数(Random库).迷宫一定是要绘制的,所以需要有一个GUI库或绘图库,这里我使用Pygame(Tkinter或Tur
-
python 远程执行命令的详细代码
1.简单版 # coding: utf-8 import paramiko import re from time import sleep def ssh(): ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) #指定当对方主机没有本机公钥的情况时应该怎么办,AutoAddPolicy表示自动在对方主机保存下本机的秘钥 ssh.connect('172.16.1.5',22,
-
一篇文章带你顺利通过Python OpenCV入门阶段
目录 1. OpenCV 初识与安装 2. OpenCV 模块简介 3. OpenCV 图像读取,显示,保存 4. 摄像头和视频读取,保存 5. OpenCV 常用数据结构和颜色空间 6. OpenCV 常用绘图函数 7. OpenCV 界面事件操作之鼠标与滑动条 8. 图像像素.通道分离与合并 9. 图像逻辑运算 10. 图像 ROI 与 mask 掩膜 11. 图像几何变换 12. 图像滤波 13. 图像固定阈值与自适应阈值 14. 图像膨胀腐蚀 15. 边缘检测 16. 霍夫变换 17.
-
python opencv摄像头的简单应用
本文实例为大家分享了python opencv摄像头应用的具体代码,供大家参考,具体内容如下 1.安装 下载安装包 pip install opencv_python-2.4.12-cp27-none-win_amd64.whl 2.代码 #coding=utf-8 import cv2 import time cap=cv2.VideoCapture(0) #读取摄像头,0表示系统默认摄像头 while True: ret,photo=cap.read() #读取图像 cv2.imshow('
-
Python OpenCV实现鼠标画框效果
使用Python+OpenCV实现鼠标画框的代码,供大家参考,具体内容如下 # -*-coding: utf-8 -*- """ @Project: IntelligentManufacture @File : user_interaction.py @Author : panjq @E-mail : pan_jinquan@163.com @Date : 2019-02-21 15:03:18 """ # -*- coding: utf-8 -