Python Pandas的简单使用教程
一、 Pandas简介
1、Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
2、Pandas 是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
3、数据结构:
Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。
Time- Series:以时间为索引的Series。
DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
Panel :三维的数组,可以理解为DataFrame的容器。
Pandas 有两种自己独有的基本数据结构。读者应该注意的是,它固然有着两种数据结构,因为它依然是 Python 的一个库,所以,Python 中有的数据类型在这里依然适用,也同样还可以使用类自己定义数据类型。只不过,Pandas 里面又定义了两种数据类型:Series 和 DataFrame,它们让数据操作更简单了。
二、Python Pandas的使用
修改列数据:
df['price']=df['price'].str.replace('人均','') # 删除多余文字
df['price']=df['price'].str.split("¥").str[-1] # 分割文本串
df['price']=df['price'].str.replace('-','0') # 替换文本
df['price']=df['price'].astype(int) # 文本转整型
把pandas转换int型为str型的方法
切分列数据:
df['kw']=df['commentlist'].str.split().str[0].str.replace("口味",'')
df['hj']=df['commentlist'].str.split().str[1].str.replace("环境",'')
df['fw']=df['commentlist'].str.split().str[2].str.replace("服务",'')
注意:pandas中操作如果不明确指定参数,则不会修改原数据,而是返回一个新对象。
删除列数据:
del df['commentlist']
排序列数据:
df.sort_values(by=['kw','price'],axis=0,ascending=[False,True],inplace=True)
注意:排序前先用astype转换正确的类型,如str、int或float
重新设置索引列标签顺序:
df.columns=['类型','店铺名称','点评数量','星级','人均消费','店铺地址','口味','环境','服务']
打印前几行数据:
print(df.loc[:,['店铺名称','口味','人均消费']].head(6)) # 或者 # print(df.iloc[0:6,[1,6,4]]) # 前6行(整数) # 但不能是 # print(df.loc[0:6,['店铺名称','口味','人均消费']]) # 从索引0到索引6的行(对象)
https://www.jb51.net/article/155602.htm
综合示例:
图例:
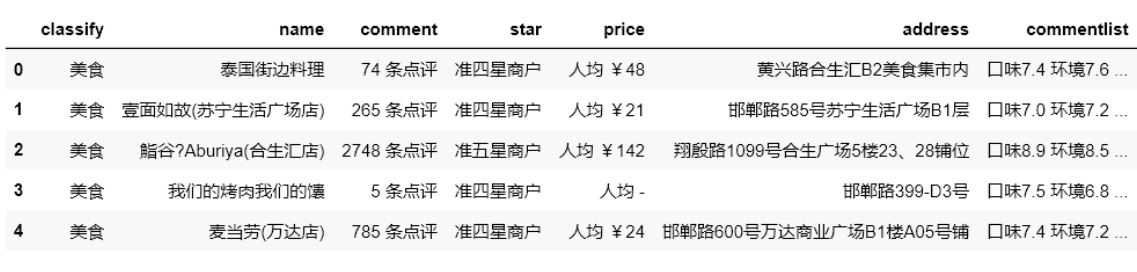
结果:

要求:
(1)对该数据中的comment、price进行数据清洗整理,
(2)将commentlist数据拆分为“口味”、“环境”和“服务”三列后再进行数据清洗整理,
(3)去除commentlist列数据
(4)将此数据按“口味”降序、“人均消费”升序进行排序,
(5)输出排序后前6条数据中的“店铺名称”、“口味”和“人均消费”三列数据。
代码:
import pandas as pd
df=pd.read_csv('spdata.csv',encoding='gbk') #读入文件,编码为gbk # 注意编码,重要
#对数据进行清洗
df['comment']=df['comment'].str.replace('条点评','')
df['price']=df['price'].str.replace('人均','')
df['price']=df['price'].str.split("¥").str[-1]
df['price']=df['price'].str.replace('-','0')
df['price']=df['price'].astype(int)
df['kw']=df['commentlist'].str.split().str[0].str.replace("口味",'')
df['hj']=df['commentlist'].str.split().str[1].str.replace("环境",'')
df['fw']=df['commentlist'].str.split().str[2].str.replace("服务",'')
del df['commentlist']
#按口味降序,人均消费升序进行排序
df.sort_values(by=['kw','price'],axis=0,ascending=[False,True],inplace=True)
#重新设置列索引标签
df.columns=['类型','店铺名称','点评数量','星级','人均消费','店铺地址','口味','环境','服务']
print(df.loc[:,['店铺名称','口味','人均消费']].head(6))
方法二:
import pandas as pd
df=pd.read_csv('spdata.csv',encoding='gbk')
df['comment']=df['comment'].str.replace('条点评','')
df['price']=df['price'].str.replace('人均','').str.replace('¥','').str.replace('-','0').str.replace(' ','').astype(int)
df[['kw','hj','fw']]=df['commentlist'].str.replace('口味','').str.replace('环境','').str.replace('服务','').str.split(expand=True).astype(float) # expand将普通的列表转为DataFrame对象
del df['commentlist']
df.sort_values(by=['kw','price'],axis=0,ascending=[False,True],inplace=True) # 注意inplace=True
df.columns=['类型','店铺名称','点评数量','星级','人均消费','店铺地址','口味','环境','服务']
print(df[['店铺名称','口味','人均消费']].head(6))
注意:df.str.split是列表,加了expand=True之后才是DataFrame对象,或者用.str[x]提取某一列,注意不是df.str.split()[x]而是df.str.split().str[x],前者是对list(二维)操作,后者是对DataFrame操作(取某一列)
到此这篇关于Python Pandas的简单使用教程的文章就介绍到这了,更多相关Python Pandas使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python pandas自定义函数的使用方法示例
本文实例讲述了Python pandas自定义函数的使用方法.分享给大家供大家参考,具体如下: 自定义函数的使用 import numpy as np import pandas as pd # todo 将自定义的函数作用到dataframe的行和列 或者Serise的行上 ser1 = pd.Series(np.random.randint(-10,10,5),index=list('abcde')) df1 = pd.DataFrame(np.random.randint(-10,10,(
-
Python使用Pandas读写Excel实例解析
这篇文章主要介绍了Python使用Pandas读写Excel实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Pandas是python的一个数据分析包,纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具. Pandas提供了大量能使我们快速便捷地处理数据的函数和方法. Pandas官方文档:https://pandas.pydata.org/pandas-docs/stable/ Pandas中文文档:https:/
-

python绘图pyecharts+pandas的使用详解
pyecharts介绍 pyecharts 是一个用于生成 Echarts 图表的类库.Echarts 是百度开源的一个数据可视化 JS 库.用 Echarts 生成的图可视化效果非常棒 为避免绘制缺漏,建议全部安装 为了避免下载缓慢,作者全部使用镜像源下载过了 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ echarts-countries-pypkg pip install -i https://pypi.tuna.tsin
-
python pandas dataframe 去重函数的具体使用
今天笔者想对pandas中的行进行去重操作,找了好久,才找到相关的函数 先看一个小例子 from pandas import Series, DataFrame data = DataFrame({'k': [1, 1, 2, 2]}) print data IsDuplicated = data.duplicated() print IsDuplicated print type(IsDuplicated) data = data.drop_duplicates() print data 执行
-
Python使用Pandas库常见操作详解
本文实例讲述了Python使用Pandas库常见操作.分享给大家供大家参考,具体如下: 1.概述 Pandas 是Python的核心数据分析支持库,提供了快速.灵活.明确的数据结构,旨在简单.直观地处理关系型.标记型数据.Pandas常用于处理带行列标签的矩阵数据.与 SQL 或 Excel 表类似的表格数据,应用于金融.统计.社会科学.工程等领域里的数据整理与清洗.数据分析与建模.数据可视化与制表等工作. 数据类型:Pandas 不改变原始的输入数据,而是复制数据生成新的对象,有普通对象构成的
-
python pandas.DataFrame.loc函数使用详解
官方函数 DataFrame.loc Access a group of rows and columns by label(s) or a boolean array. .loc[] is primarily label based, but may also be used with a boolean array. # 可以使用label值,但是也可以使用布尔值 Allowed inputs are: # 可以接受单个的label,多个label的列表,多个label的切片 A singl
-
Python使用Pandas对csv文件进行数据处理的方法
今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不给力,又尝试用R搞一下吧结果发现光加载csv文件就要3分钟左右的时间,相当不给力啊,翻了翻万能的知乎发现了Python下的一个神器包:Pandas(熊猫们?),加载这个140多M的csv文件两秒钟就搞定,后面的分类汇总等操作也都是秒开,太牛逼了!记录一下这次数据处理的过程: 使用
-
Python Pandas的简单使用教程
一. Pandas简介 1.Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.pandas提供了大量能使我们快速便捷地处理数据的函数和方法.你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一. 2.Pandas 是python的一个数据分析包,最初由AQR Capital Management
-
python Tkinter的简单入门教程
我们将编写一个英尺和米的转换程序,通过这个程序,我们将会了解一个真正的实用程序该怎么设计和编写,我们也将会了解到 Tk 程序内部的基本样子.不必完全掌握里面的所有知识,更多细节将会在之后的章节中讲到.本节仅要求了解即可,使读者明白如何设计和编写一个 Tk GUI 程序. 设计 我们将要写一个简单的将英尺(feet)转换为米(meters)的 GUI 工具,按照我们的经验,它应该长成下面那个样子: 这个程序会有一个输入框用来输入英尺数,还将会有一个显示框用来显示被转换之后的数字,几个用于显示提示
-
Python Pandas数据结构简单介绍
Series Series 类似一维数组,由一组数据及一组相关数据标签组成.使用pandas的Series类即可创建. import pandas as pd s1 = pd.Series(['a', 'b', 'c,', 'd']) print(s1) #输出: 0 a # 1 b # 2 c # 3 d # dtype: object 上面是传入一个列表实现,上面的0,1,2,3就是数据的默认标签.另外可以通过index属性自定义标签. s2 = pd.Series(['1', '2', '
-
python pandas数据处理教程之合并与拼接
目录 前言 一.join 1.leftjoin 2.rightjoin 3.innerjoin 4.outjoin 二.merge 三.concat 1.纵向合并 2.横向合并 四.append 1.同结构数据追加 2.不同结构数据追加 3.追加合并多个数据集 五.combine_first 六.update 总结 前言 在许多应用中,数据可能来自不同的渠道,在数据处理的过程中常常需要将这些数据集进行组合合并拼接,形成更加丰富的数据集.pandas提供了多种方法完全可以满足数据处理的常用需求.具
-
python中format()函数的简单使用教程
先给大家介绍下python中format函数,在文章下面给大家介绍python.format()函数的简单使用 ---恢复内容开始--- python中format函数用于字符串的格式化 通过关键字 print('{名字}今天{动作}'.format(名字='陈某某',动作='拍视频'))#通过关键字 grade = {'name' : '陈某某', 'fenshu': '59'} print('{name}电工考了{fenshu}'.format(**grade))#通过关键字,可用字典当关键
-
python中的turtle库函数简单使用教程
具体内容如下所示: 参考案例: import turtle d=0 for i in range(4): turtle.fd(200) #或者写成turtle.forward(200) d =d+90 turtle.seth(d) #改变角度,可以写成turtle.setheading(to_angle) 总结 以上所述是小编给大家介绍的python中的turtle库函数简单使用教程,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持! 如
-
python中turtle库的简单使用教程
python的turtle库的简单使用 Python的turtle库是一个直观有趣的图形绘制函数库,是python的标准库之一. 一.绘图坐标体系 turtle库绘制图形的基本框架:通过一个小海龟在坐标系中的爬行轨迹绘制图形,小海龟的初始位置在画布中央. turtle.setup(width,height,startx,starty) 1.width,height:为主窗体的宽和高 2.startx,starty:为窗口距离左侧与屏幕左侧像素距离和窗口顶部与屏幕顶部的像素距离. import t
-
python工具——Mimesis的简单使用教程
Mimesis是一个用于Python的高性能伪数据生成器, 支持多种不同的语言 可以用来生成各种测试数据.假的 API .任意结构的 JSON .XML 数据 安装 pip install mimesis 示例 from mimesis import Person person = Person('zh') print(f'name: {person.surname() + "" + person.name()}') print(f'sex: {person.sex()}') prin
-
Python Pandas高级教程之时间处理
目录 简介 时间分类 Timestamp DatetimeIndex date_range 和 bdate_range origin 格式化 Period DateOffset 作为index 切片和完全匹配 时间序列的操作 Shifting 频率转换 Resampling 重新取样 总结 简介 时间应该是在数据处理中经常会用到的一种数据类型,除了Numpy中datetime64 和 timedelta64 这两种数据类型之外,pandas 还整合了其他python库比如 scikits.ti
-
python编程Flask框架简单使用教程
目录 基础知识 使用框架的优点: Flask常用扩展包: 基本格式: 拓展: return 重定向 取网址参数 content-type cookie\session flask路由 request属性 上下文 注册路由 基础知识 使用框架的优点: 稳定性和可扩展性强 可以降低开发难度,提高了开发效率 Flask诞生于2010年,是Armin ronacher用Python语言基于Werkzeug工具箱编写的轻量级Web开发框架 Flask本身相当于一个内核,其他几乎所有的功能都要用到扩展(邮件