Python解决爬虫程序卡死问题
目录
- 前言:
- 简单粗暴解决问题
- 增加一点点难度的解决方案
- 我们继续给爬虫程序加点料
- 尾声
前言:
之前的文章我们已经开启了爬虫程序的exe之旅,但是我们最终实现的程序存在一个非常大的问题,当进行网络请求的时候,程序卡死,直到数据请求回来之后,程序才会从假死状态解脱出来,今天这篇博客核心将这个问题解决掉。
导致该问题产生的原因是GUI程序在执行高IO操作的时候很容易出现假死和无响应的状态,通用解决办法就是多线程。
如果想扩展开本知识点的学习,可以在搜索引擎搜索 tkinter假死,未响应等关键字即可
简单粗暴解决问题
找到上节课需要修改的代码部分 :

修改成如下代码,立马解决问题:
def thread_down(func, *args):
# 创建线程
t = threading.Thread(target=func, args=args)
t.setDaemon(True)
# 启动
t.start()
# 创建按钮
btn = tk.Button(win,text = '分析下载', command = lambda :thread_down(down_img))
当然记得在头部导入线程模块:
import threading
对于咱们常写爬虫的Coder来说,多线程就不用过多的解释了,非常容易理解,注意下t.setDaemon(True)
通过 t.setDaemon(True) 将子线程设置为守护进程(默认False),主线程结束后,守护子线程随之中止。
以上是最简单的解决办法了,顺着这个思路慢慢的修改你的程序即可
增加一点点难度的解决方案
该方案假设你的爬虫比较复杂一些,用的是类去编写的,那么增加一个类文件即可,该类继承 threading.Thread 类
class MyThread(threading.Thread):
def __init__(self, func, *args):
super().__init__()
self.func = func
self.args = args
self.setDaemon(True)
self.start() # 构造方法中启动线程
def run(self):
self.func(*self.args)
# 创建按钮
btn = tk.Button(win,text = '分析下载', command = lambda :MyThread(down_img))
上述解决办法也比较简单,重点依旧是将I/O耗时操作放置到一个新的线程中去
我们重点注意在上述的代码中tk.Button(win,text = '分析下载', command = lambda :MyThread(down_img))中我们给command绑定值的时候用到的lambda函数
lambda这个大家都知道是匿名函数,在这里的用法注意是tk要求的。
他表示 传参数Button绑定事件,文档中大概意思如下:
我们使用Button传递数值时,需要用:
lambda: 功能函数(var1, var2, ……)
所以大家在使用的时候,注意该问题哦~~
我们继续给爬虫程序加点料
上面已经解决了一个小问题,这些当然是不够的,我们的程序岂止于此,接下来,我们每次访问页面的时候,网页源码的图片规则肯定是不能确定的,所以用户可以自定义正则表达式去匹配数据,就是我们接下来改进的方向啦~
先把程序窗口扩大一些
# 窗体大小设置 width = 800 height = 600
增加一个文本框和一个多行输入框:
lbtip = tk.Label(win, text='请输入正则表达式:') # 添加到窗口中 lbtip.grid(row=1,column=3,pady=20) # 创建一个多行文本框 - 用于输入正则表达式 t1 = tk.Text(win, width=40,height=20) # 添加到窗口中 t1.grid(row=2,column=3,padx=20,columnspan=3)
看看布局,细节可以在调整一下:
获取正则表达式输入框数据:
这个地方一个小知识点需要补充下,在tkiner中有两种文本框,单行和多行,对于里面内容的获取方式也不同
#get()方法获取Entry 文本框的内容:
txt = entry.get()
#get()方法获取Text 文本框的内容:
txt = text.get("0.0", "end")
Text.get(start, end) 的用法:
Text.get("0.0", "end") 解析: 第一个参数‘0.0’是指从第0行第0列开始读取(‘0.3’表示从第0行第3列开始读取),第二个参数end表示最后一个字符
写完测试下:
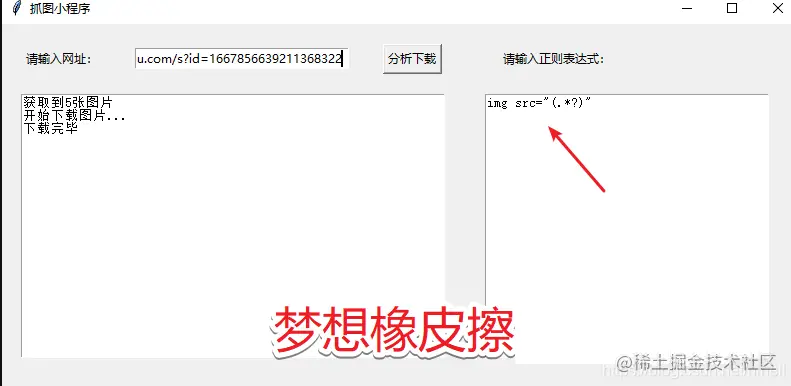
测试完毕:

尾声
tkiner其实写起来慢慢调整还是蛮有意思的,可以用来开发一些不错的小工具
测试连接 http://baijiahao.baidu.com/s?id=1667856639211368322 测试正则 <img class="large" data-loadfunc=0 src="(.*?)"
到此这篇关于Python解决爬虫程序卡死问题的文章就介绍到这了,更多相关Python卡死问题内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
解决python线程卡死的问题
1. top命令和日志方式判定卡死的位置 python代码忽然卡死,日志不输出,通过如下方式可以确定线程确实已经死掉了: # top 命令 top命令可以看到机器上所有线程的执行情况,%CPU和%MEM可以看出线程消耗的资源情况 由于机器上线程数量太多,可能要查看的线程的信息在top命令当前屏幕上显示不出来可以通过如下方式查看 在top命令下输入:u 接下来会提示输入用户名,就可以查看该用户所执行的所有线程 Which user (blank for all): denglinjie 这样就可以
-
解决python tkinter界面卡死的问题
如果点击按钮,运行了一个比较耗时的操作,那么界面会卡死. import tkinter as tk import time def onclick(text, i): time.sleep(3) text.insert(tk.END, '按了第{}个按钮\n'.format(i)) root = tk.Tk() text = tk.Text(root) text.pack() tk.Button(root, text='按钮1', command=lambda :onclick(text,1))
-

Python解决爬虫程序卡死问题
目录 前言: 简单粗暴解决问题 增加一点点难度的解决方案 我们继续给爬虫程序加点料 尾声 前言: 之前的文章我们已经开启了爬虫程序的exe之旅,但是我们最终实现的程序存在一个非常大的问题,当进行网络请求的时候,程序卡死,直到数据请求回来之后,程序才会从假死状态解脱出来,今天这篇博客核心将这个问题解决掉. 导致该问题产生的原因是GUI程序在执行高IO操作的时候很容易出现假死和无响应的状态,通用解决办法就是多线程. 如果想扩展开本知识点的学习,可以在搜索引擎搜索 tkinter假死,未响应等关键字即
-
Python的爬虫程序编写框架Scrapy入门学习教程
1. Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 Scrapy 使用了 Twisted异步网络库来处理网络通讯.整体架构大致如下 Scrapy
-
python如何解决指定代码段超时程序卡死
目录 python解决指定代码段超时程序卡死 python程序运行超过时长强制退出 1.程序内部设置时长,超过退出 2.程序外部控制,超过强制退出 python解决指定代码段超时程序卡死 最近我写的一个程序中遇到了解析网页的代码,对于网页信息比较多的可能会超时,最后解析失败,程序卡死,于是我就找到了一个解决办法 大致模板如下: import eventlet eventlet.monkey_patch() flag_TimeOut = True with eventlet.Timeout(40,
-
Python开发实例分享bt种子爬虫程序和种子解析
看到网上也有开源的代码,这不,我拿来进行了二次重写,呵呵,上代码: 复制代码 代码如下: #encoding: utf-8 import socket from hashlib import sha1 from random import randint from struct import unpack, pack from socket import inet_aton, inet_ntoa from bisect import b
-
详解nodejs爬虫程序解决gbk等中文编码问题
使用nodejs写了一个爬虫的demo,目的是提取网页的title部分. 遇到最大的问题就是网页的编码与nodejs默认编码不一致造成的乱码问题.nodejs支持utf8, ucs2, ascii, binary, base64, hex等编码方式,但是对于汉语言来说编码主要分为三种,utf-8,gb2312,gbk.这里面gbk是完全兼容gb2312的,因此在处理编码的时候主要就分为utf-8以及gbk两大类.(这是在没有考虑到其他国家的编码情况,比如日本的Shift_JIS编码等,同时这里这
-
python 写的一个爬虫程序源码
写爬虫是一项复杂.枯噪.反复的工作,考虑的问题包括采集效率.链路异常处理.数据质量(与站点编码规范关系很大)等.整理自己写一个爬虫程序,单台服务器可以启用1~8个实例同时采集,然后将数据入库. #-*- coding:utf-8 -*- #!/usr/local/bin/python import sys, time, os,string import mechanize import urlparse from BeautifulSoup import BeautifulSoup import
-
一个简单的python爬虫程序 爬取豆瓣热度Top100以内的电影信息
概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web站点的行为来获取有价值的数据.专业的解释:百度百科 分析爬虫需求 确定目标 爬取豆瓣热度在Top100以内的电影的一些信息,包括电影的名称.豆瓣评分.导演.编剧.主演.类型.制片国家/地区.语言.上映日期.片长.IMDb链接等信息. 分析目标 1.借助工具分析目标网页 首先,我们打开豆瓣电影·热门电影,会发现页面总共20部
-
解决Python网页爬虫之中文乱码问题
Python是个好工具,但是也有其固有的一些缺点.最近在学习网页爬虫时就遇到了这样一种问题,中文网站爬取下来的内容往往中文显示乱码.看过我之前博客的同学可能知道,之前爬取的一个学校网页就出现了这个问题,但是当时并没有解决,这着实成了我一个心病.这不,刚刚一解决就将这个方法公布与众,大家一同分享. 首先,我说一下Python中文乱码的原因,Python中文乱码是由于Python在解析网页时默认用Unicode去解析,而大多数网站是utf-8格式的,并且解析出来之后,python竟然再以Unicod
-
Python爬虫程序架构和运行流程原理解析
1 前言 Python开发网络爬虫获取网页数据的基本流程为: 发起请求 通过URL向服务器发起request请求,请求可以包含额外的header信息. 获取响应内容 服务器正常响应,将会收到一个response,即为所请求的网页内容,或许包含HTML,Json字符串或者二进制的数据(视频.图片)等. 解析内容 如果是HTML代码,则可以使用网页解析器进行解析,如果是Json数据,则可以转换成Json对象进行解析,如果是二进制的数据,则可以保存到文件做进一步处理. 保存数据 可以保存到本地文件,也
-
结合Python网络爬虫做一个今日新闻小程序
核心代码 requests.get 下载html网页 bs4.BeautifulSoup 分析html内容 from requests import get from bs4 import BeautifulSoup as bs from datetime import datetime as dt def Today(style=1): date = dt.today() if style!=1: return f'{date.month}月{date.day}日' return f'{dat