C++用函数对算法性能进行测试
目录
- 前言
- 工具
- 模板
- 说明
- 测试
前言
“Algorithm+Data Structures=Programs”——瑞士计算机科学家尼古拉斯·沃斯
工具
C/C++库函数中的time.h/ctime库中的clock()函数
模板
#include<iostream>
#include<ctime>
using namespace std;
clock_t start_time = clock();
{ 算 法 代 码 块 };
clock_t end_time = clock();
cout<<(double)(end_time - start_time) / CLOCKS_PER_SEC<<"秒";
说明
clock()函数返回类型为clock_t(实际上是long类型),它返回从开启某个程序进程到再次调用clock()函数之间的CPU时钟计时单元(时钟周期)。
CLOCKS_PER_SEC是标准库中所定义的宏,表示每1秒CPU时钟计时单元(时钟周期)的个数
end_time - start_time 表示该程序执行期间CPU时钟计时单元(时钟周期)的总个数,除以每秒钟CPU时钟计时单元(时钟周期),即可得到程序实际运行时间,返回的单位是毫秒。
测试
分别测试选择排序算法和C++中的sort()函数的算法性能,测试数据由随机数生成。
#include<iostream>
#include<algorithm>
#include<ctime>
using namespace std;
//选择排序
void SelectSort(int a[],int n){
for(int i=0;i<n;i++){
int min_index=i;
for(int j=i+1;j<n;j++)
if(a[j]<a[min_index])
min_index=j;
swap(a[i],a[min_index]);
}
}
//随机数组
int* RandomArray(int n,int rangeL,int rangeR){
int *arr=new int[n];//创建一个大小为n的数组
srand(time(NULL));//以时间为"种子"产生随机数
for(int i=0;i<n;i++){
arr[i]=rand()%(rangeR-rangeL+1)+rangeL;//生成指定区间[rangeL,rangeR]里的数
}
return arr;
}
int main(){
int n;
cout<<"请输入数据规模n: ";cin>>n;
int *arr1,*arr2;
arr1=RandomArray(n,0,10000);
arr2=arr1;
clock_t start_time1=clock();
SelectSort(arr1,n);//选择排序算法
clock_t end_time1=clock();
cout<<"选择排序耗时:"<<(double)(end_time1-start_time1)/CLOCKS_PER_SEC<<"秒"<<endl;
clock_t start_time2=clock();
sort(arr2,arr2+n);//C++中sort()排序函数,底层为优化的快速排序算法
clock_t end_time2=clock();
cout<<"优化快排耗时:"<<(double)(end_time2-start_time2)/CLOCKS_PER_SEC<<"秒"<<endl;
return 0;
}
测试结果
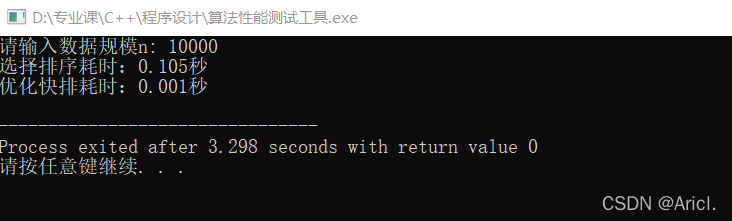

测试结果分析
通过对比可知,在数据规模相同的情况下,C++sort()排序算法的性能远远远远优于选择排序。
我们能从数据上直观的看到数据规模的增长所带来的运行时间的加长,数据规模由10000变为100000,扩大了10倍,那么根据时间复杂度的分析,选择排序的算法时间会扩大100倍左右,而sort()排序函数则会扩大10倍左右,由测试结果看出,确实如此。
因为选择排序算法的时间复杂度为O(n^2),而C++sort()排序函数的底层实现原理是快速排序算法,而且是优化的快速排序,系统会根据数据形式和数据量自动选择合适的排序方法。它每次排序中不只选择一种方法,比如给一个数据量较大的数组排序,开始采用快速排序,分段递归,分段之后每一段的数据量达到一个较小值后它就不继续往下递归,而是选择插入排序,如果递归的太深,他则会选择堆排序,时间复杂度为O(nlogn)。可见C++中sort()排序算法性能之强悍!(呐喊)
到此这篇关于C++用函数对算法性能进行测试的文章就介绍到这了,更多相关C++性能测试内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

浅谈c++性能测试工具google benchmark
一.测试对象 这次测试的对象是标准库的vector,我们将会在vs2019 16.10和Linux + GCC 11.1上进行测试.为了代码写着方便,我还会启用c++17支持. 这次的疑问来自于<A Tour of C++>这本书,最近在重新翻阅本书的时候发现书里第九章给出了一个很有意思的建议:尽量少用reserve方法. 我们都知道reserve会提前分配足够大的内存来容纳元素,这样在push_back时可以减少内存分配和元素移动的次数,从而提高性能.所以习惯上如果我们知道vector中存储
-
浅谈c++性能测试工具之计算时间复杂度
google benchmark已经为我们提供了类似的功能,而且使用相当简单. 具体的解释在后面,我们先来看几个例子,我们人为制造几个时间复杂度分别为O(n), O(logn), O(n^n)的测试用例: // 这里都是为了演示而写成的代码,没有什么实际意义 static void bench_N(benchmark::State& state) { int n = 0; for ([[maybe_unused]] auto _ : state) { for (int i = 0; i <
-
C++用函数对算法性能进行测试
目录 前言 工具 模板 说明 测试 前言 “Algorithm+Data Structures=Programs”——瑞士计算机科学家尼古拉斯·沃斯 工具 C/C++库函数中的time.h/ctime库中的clock()函数 模板 #include<iostream> #include<ctime> using namespace std; clock_t start_time = clock(); { 算 法 代 码 块 }; clock_t end_time = clock()
-
PHP中strtr与str_replace函数运行性能简单测试示例
本文实例讲述了PHP中strtr与str_replace函数运行性能简单测试.分享给大家供大家参考,具体如下: strtr与str_replace函数性能,很简单的一个测试,只是简单的测下,供参考,代码如下: <?php require_once('Timer.php'); $target = 'qwertyuiop[]asdfghjkl;\'zxcvbnm,./qwertyuiop[]asdfghjkl;\'zxcvbnm,./qwertyuiop[]asdfghjkl;\'zxcvbnm,.
-
Java遍历集合方法分析(实现原理、算法性能、适用场合)
概述 Java语言中,提供了一套数据集合框架,其中定义了一些诸如List.Set等抽象数据类型,每个抽象数据类型的各个具体实现,底层又采用了不同的实现方式,比如ArrayList和LinkedList. 除此之外,Java对于数据集合的遍历,也提供了几种不同的方式.开发人员必须要清楚的明白每一种遍历方式的特点.适用场合.以及在不同底层实现上的表现.下面就详细分析一下这一块内容. 数据元素是怎样在内存中存放的? 数据元素在内存中,主要有2种存储方式: 1.顺序存储,Random Access(Di
-
C++ 数据结构之kmp算法中的求Next()函数的算法
C++ 数据结构之kmp算法中的求Next()函数的算法 实例代码: #include <iostream> using namespace std; void preKmp(char *c, int m, int Next[]) { int i=1,j=-1; Next[0]=-2; while(i<m) { if(j==-2) { Next[i]=-1; i++; j=-1; } ++j; if(i==m) return; if(c[i]==c[j]) { Next[i]=j; ++
-
MySQL系列之十五 MySQL常用配置和性能压力测试
一.MySQL常用配置 以下所有配置参数以32G内存的服务器为基 1.打开独立的表空间 innodb_file_per_table = 1 2.MySQL服务所允许的同时会话数的上限,默认为151,经常出现Too Many Connections的错误提示,则需要增大此值 max_connections = 8000 3.操作系统在监听队列中所能保持的连接数 back_log = 300 4.每个客户端连接最大的错误允许数量,当超过该次数,MYSQL服务器将禁止此主机的连接请求,直到MYSQL服
-
每天练一练Java函数与算法Math函数总结与字符串转换整数
题目 请你来实现一个 myAtoi(string s) 函数,使其能将字符串转换成一个 32 位有符号整数(类似 C/C++ 中的 atoi 函数). 函数 myAtoi(string s) 的算法如下: 读入字符串并丢弃无用的前导空格 . 检查下一个字符(假设还未到字符末尾)为正还是负号,读取该字符(如果有). 确定最终结果是负数还是正数.如果两者都不存在,则假定结果为正. 读入下一个字符,直到到达下一个非数字字符或到达输入的结尾.字符串的其余部分将被忽略. 将前面步骤读入的这些数字转换为整数
-
java理论基础Stream性能论证测试示例
目录 一.粉丝的反馈 二.所有性能测试结论都是片面的 三.动手测试Stream的性能 3.1.环境 3.2.测试用例与测试结论 3.2.1.测试用例一 3.2.2测试用例二 3.2.3测试用例三 四.最终测试结论 五.测试代码 测试用例一: 测试用例二: 测试用例三: 一.粉丝的反馈 问:stream比for循环慢5倍,用这个是为了啥? 答:互联网是一个新闻泛滥的时代,三人成虎,以假乱真的事情时候发生.作为一个技术开发者,要自己去动手去做,不要人云亦云. 的确,这位粉丝说的这篇文章我也看过,我就
-
详解关于JSON.parse()和JSON.stringify()的性能小测试
JSON.parse(JSON.stringify(obj))我们一般用来深拷贝,其过程说白了,就是利用 JSON.stringify 将js对象序列化(JSON字符串),再使用JSON.parse来反序列化(还原)js对象.至于这行代码为什么能实现深拷贝,以及它有什么局限性等等,不是本文要介绍的.本文要探究的是,这行代码的执行效率如何?如果随意使用会不会造成一些问题? 先上两个js性能测试的依赖函数 /** * 一个简单的断言函数 * @param value {Boolean} 断言条件 *
-
PHP中对各种加密算法、Hash算法的速度测试对比代码
PHP 的Hash算法是比较常用的,现在的MD5有时候不太安全,就得用到Hash_algos()中的其它算法,下面进行了一个性能的比较. php代码: define('testtime', 50000); $algos = hash_algos(); foreach($algos as $algo) { $st = microtime(); for($i = 0; $i < testtime; $i++) { hash($algo, microtime().$i); } $et = microt
-
MySQL两种表存储结构MyISAM和InnoDB的性能比较测试
MySQL支持的两种主要表存储格式MyISAM,InnoDB,上个月做个项目时,先使用了InnoDB,结果速度特别慢,1秒钟只能插入10几条.后来换成MyISAM格式,一秒钟插入上万条.当时决定这两个表的性能也差别太大了吧.后来自己推测,不应该差别这么慢,估计是写的插入语句有问题,决定做个测试:测试环境:Redhat Linux9,4CPU,内存2G,MySQL版本为4.1.6-gamma-standard测试程序:Python+Python-MySQL模块.测试方案:1.MyISAM格式分别测