Tensorflow中的图(tf.Graph)和会话(tf.Session)的实现
Tensorflow编程系统

Tensorflow工具或者说深度学习本身就是一个连贯紧密的系统。一般的系统是一个自治独立的、能实现复杂功能的整体。系统的主要任务是对输入进行处理,以得到想要的输出结果。我们之前见过的很多系统都是线性的,就像汽车生产工厂的流水线一样,输入->系统处理->输出。系统内部由很多单一的基本部件构成,这些单一部件具有特定的功能,且需要稳定的特性;系统设计者通过特殊的连接方式,让这些简单部件进行连接,以使它们之间可以进行数据交流和信息互换,来达到相互配合而完成具体工作的目的。
对于任何一个系统来说,都应该拥有稳定、独立、能处理特殊任务的单一部件;且拥有一套良好的内部沟通机制,以让系统可以健康安全的运行。
现实中的很多系统都是线性的,被设计好的、不能进行更改的,比如工厂的流水线,这样的系统并不具备自我调整的能力,无法对外界的环境做出反应,因此也就不具备“智能”。
深度学习(神经网络)之所以具备智能,就是因为它具有反馈机制。深度学习具有一套对输出所做的评价函数(损失函数),损失函数在对神经网络做出评价后,会通过某种方式(梯度下降法)更新网络的组成参数,以期望系统得到更好的输出数据。

由此可见,神经网络的系统主要由以下几个方面组成:
- 输入
- 系统本身(神经网络结构),以及涉及到系统本身构建的问题:如网络构建方式、网络执行方式、变量维护、模型存储和恢复等等问题
- 损失函数
- 反馈方式:训练方式
定义好以上的组成部分,我们就可以用流程化的方式将其组合起来,让系统对输入进行学习,调整参数。因为该系统的反馈机制,所以,组成的方式肯定需要循环。
而对于Tensorflow来说,其设计理念肯定离不开神经网络本身。所以,学习Tensorflow之前,对神经网络有一个整体、深刻的理解也是必须的。如下图:Tensorflow的执行示意。
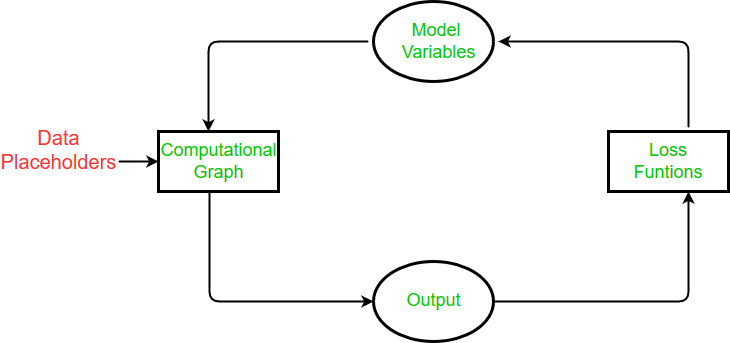
那么对于以上所列的几点,什么才是最重要的呢?我想肯定是有关系统本身所涉及到的问题。即如何构建、执行一个神经网络?在Tensorflow中,用计算图来构建网络,用会话来具体执行网络。深入理解了这两点,我想,对于Tensorflow的设计思路,以及运行机制,也就略知一二了。
图(tf.Graph):计算图,主要用于构建网络,本身不进行任何实际的计算。计算图的设计启发是高等数学里面的链式求导法则的图。我们可以将计算图理解为是一个计算模板或者计划书。
会话(tf.session):会话,主要用于执行网络。所有关于神经网络的计算都在这里进行,它执行的依据是计算图或者计算图的一部分,同时,会话也会负责分配计算资源和变量存放,以及维护执行过程中的变量。
接下来,我们主要从计算图开始,看一看Tensorflow是如何构建、执行网络的。
计算图
在开始之前,我们先复习一下Tensorflow的几种基本数据类型:
tf.constant(value, dtype=None, shape=None, name='Const', verify_shape=False) tf.Variable(initializer, name) tf.placeholder(dtype, shape=None, name=None)
复习完毕。
graph = tf.Graph() with graph.as_default(): img = tf.constant(1.0, shape=[1,5,5,3])
以上代码中定义了一个计算图,在该计算图中定义了一个常量。Tensorflow默认会创建一张计算图。所以上面代码中的前两行,可以省略。默认情况下,计算图是空的。

在执行完img = tf.constant(1.0, shape=[1,5,5,3])以后,计算图中生成了一个node,一个node结点由name, op, input, attrs组成,即结点名称、操作、输入以及一系列的属性(类型、形状、值)等组成,计算图就是由这样一个个的node组成的。对于tf.constant()函数,只会生成一个node,但对于有的函数,如tf.Variable(initializer, name)(注意其第一个参数是初始化器)就会生成多个node结点(后面会讲到)。
那么执行完img = tf.constant(1.0, shape=[1,5,5,3])后,计算图中就多一个node结点。(因为每个node的属性很多,我只表示name,op,input属性)

继续添加代码:
img = tf.constant(1.0, shape=[1,5,5,3]) k = tf.constant(1.0, shape=[3,3,3,1])
代码执行后的计算图如下:

需要注意的是,如果没有对结点进行命名,Tensorflow自动会将其命名为:Const、Const_1、const_2......。其他类型的结点类同。
现在,我们添加一个变量:
img = tf.constant(1.0, shape=[1,5,5,3]) k = tf.constant(1.0, shape=[3,3,3,1]) kernel = tf.Variable(k)
该变量用一个常量作为初始化器。我们先看一下计算图:

如图所示:
执行完tf.Variable()函数后,一共产生了三个结点:
- Variable:变量维护(不存放实际的值)
- Variable/Assign:变量分配
- Variable/read:变量使用
图中只是完成了操作的定义,但并没有执行操作(如Variable/Assign结点的Assign操作,所以,此时候变量依然不可以使用,这就是为什么要在会话中初始化的原因)。
我们继续添加代码:
img = tf.constant(1.0, shape=[1,5,5,3]) k = tf.constant(1.0, shape=[3,3,3,1]) kernel = tf.Variable(k) y = tf.nn.conv2d(img, kernel, strides=[1,2,2,1], padding="SAME")
得到的计算图如下:

可以看出,变量读取是通过Variable/read来进行的。
如果在这里我们直接开启会话,并执行计算图中的卷积操作,系统就会报错。
img = tf.constant(1.0, shape=[1,5,5,3]) k = tf.constant(1.0, shape=[3,3,3,1]) kernel = tf.Variable(k) y2 = tf.nn.conv2d(img, kernel, strides=[1,2,2,1], padding="SAME") with tf.Session() as sess: sess.run(y2)
这段代码错误的原因在于,变量并没有初始化就被使用,而从图中清晰的可以看到,直接执行卷积,是回溯不到变量的值(Const_1)的(箭头方向)。
所以,在执行之前,要进行初始化,代码如下:
img = tf.constant(1.0, shape=[1,5,5,3]) k = tf.constant(1.0, shape=[3,3,3,1]) kernel = tf.Variable(k) y2 = tf.nn.conv2d(img, kernel, strides=[1,2,2,1], padding="SAME") init = tf.global_variables_initializer()
执行完tf.global_variables_initializer()函数以后,计算图如下:

tf.global_variables_initializer()产生了一个名为init的node,该结点将所有的Variable/Assign结点作为输入,以达到对整张计算图中的变量进行初始化。
所以,在开启会话后,执行的第一步操作,就是变量初始化(当然变量初始化的方式有很多种,我们也可以显示调用tf.assign()来完成对单个结点的初始化)。
完整代码如下:
img = tf.constant(1.0, shape=[1,5,5,3]) k = tf.constant(1.0, shape=[3,3,3,1]) kernel = tf.Variable(k) y2 = tf.nn.conv2d(img, kernel, strides=[1,2,2,1], padding="SAME") init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) # do someting....
会话
在上述代码中,我已经使用会话(tf.session())来执行计算图了。在tf.session()中,我们重点掌握无所不能的sess.run()。
一个session()中包含了Operation被执行,以及Tensor被evaluated的环境。
tf.Session().run()函数的定义:
run( fetches, feed_dict=None, options=None, run_metadata=None )
tf.Session().run()函数的功能为:执行fetches参数所提供的operation操作或计算其所提供的Tensor。
run()函数每执行一步,都会执行与fetches有关的图中的所有结点的计算,以完成fetches中的任务。其中,feed_dict提供了部分数据输入的功能。(和tf.Placeholder()搭配使用,很舒服)
参数说明:
- fetches:可以是图中的一个结点,也可以是一个List或者字典,此时候返回值与fetches格式一致;该参数还可以是一个Operation,此时候返回值为None。
- feed_dict:字典格式。给模型输入其计算过程中所需要的值。
当我们把模型的计算图构建好以后,就可以利用会话来进行执行训练了。
在明白了计算图是如何构建的,以及如何被会话正确的执行以后,我们就可以愉快的开始Tensorflow之旅啦。
参考链接
https://danijar.com/what-is-a-tensorflow-session/
到此这篇关于Tensorflow中的图(tf.Graph)和会话(tf.Session)的实现的文章就介绍到这了,更多相关Tensorflow tf.Graph tf.Session内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
TensorFlow梯度求解tf.gradients实例
我就废话不多说了,直接上代码吧! import tensorflow as tf w1 = tf.Variable([[1,2]]) w2 = tf.Variable([[3,4]]) res = tf.matmul(w1, [[2],[1]]) grads = tf.gradients(res,[w1]) with tf.Session() as sess: tf.global_variables_initializer().run() print sess.run(res) print se
-
Tensorflow中tf.ConfigProto()的用法详解
参考Tensorflow Machine Leanrning Cookbook tf.ConfigProto()主要的作用是配置tf.Session的运算方式,比如gpu运算或者cpu运算 具体代码如下: import tensorflow as tf session_config = tf.ConfigProto( log_device_placement=True, inter_op_parallelism_threads=0, intra_op_parallelism_threads=0,
-
浅谈tensorflow 中tf.concat()的使用
concat()是将tensor沿着指定维度连接起来.其中tensorflow1.3版中是这样定义的: concat(values,axis,name='concat') 一.对于2维来说,0表示行,1表示列 t1 = [[1, 2, 3], [4, 5, 6]] t2 = [[7, 8, 9], [10, 11, 12]] with tf.Session() as sess: print(sess.run(tf.concat([t1, t2], 0) )) 结果为:[[1, 2, 3], [4
-
TensorFlow tf.nn.max_pool实现池化操作方式
max pooling是CNN当中的最大值池化操作,其实用法和卷积很类似 有些地方可以从卷积去参考[TensorFlow] tf.nn.conv2d实现卷积的方式 tf.nn.max_pool(value, ksize, strides, padding, name=None) 参数是四个,和卷积很类似: 第一个参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape 第
-
tensorflow之变量初始化(tf.Variable)使用详解
默认本系列的的读者已经初步熟悉tensorflow. 我们通过tf.Variable构造一个variable添加进图中,Variable()构造函数需要变量的初始值(是一个任意类型.任意形状的tensor),这个初始值指定variable的类型和形状.通过Variable()构造函数后,此variable的类型和形状固定不能修改了,但值可以用assign方法修改. 如果想修改variable的shape,可以使用一个assign op,令validate_shape=False. 通过Varia
-
关于Tensorflow中的tf.train.batch函数的使用
这两天一直在看tensorflow中的读取数据的队列,说实话,真的是很难懂.也可能我之前没这方面的经验吧,最早我都使用的theano,什么都是自己写.经过这两天的文档以及相关资料,并且请教了国内的师弟.今天算是有点小感受了.简单的说,就是计算图是从一个管道中读取数据的,录入管道是用的现成的方法,读取也是.为了保证多线程的时候从一个管道读取数据不会乱吧,所以这种时候 读取的时候需要线程管理的相关操作.今天我实验室了一个简单的操作,就是给一个有序的数据,看看读出来是不是有序的,结果发现是有序的,所以
-

Tensorflow 利用tf.contrib.learn建立输入函数的方法
在实际的业务中,可能会遇到很大量的特征,这些特征良莠不齐,层次不一,可能有缺失,可能有噪声,可能规模不一致,可能类型不一样,等等问题都需要我们在建模之前,先预处理特征或者叫清洗特征.那么这清洗特征的过程可能涉及多个步骤可能比较复杂,为了代码的简洁,我们可以将所有的预处理过程封装成一个函数,然后直接往模型中传入这个函数就可以啦~~~ 接下来我们看看究竟如何做呢? 1. 如何使用input_fn自定义输入管道 当使用tf.contrib.learn来训练一个神经网络时,可以将特征,标签数据直接输入到
-
TensorFlow入门使用 tf.train.Saver()保存模型
关于模型保存的一点心得 saver = tf.train.Saver(max_to_keep=3) 在定义 saver 的时候一般会定义最多保存模型的数量,一般来说,如果模型本身很大,我们需要考虑到硬盘大小.如果你需要在当前训练好的模型的基础上进行 fine-tune,那么尽可能多的保存模型,后继 fine-tune 不一定从最好的 ckpt 进行,因为有可能一下子就过拟合了.但是如果保存太多,硬盘也有压力呀.如果只想保留最好的模型,方法就是每次迭代到一定步数就在验证集上计算一次 accurac
-
Tensorflow中的图(tf.Graph)和会话(tf.Session)的实现
Tensorflow编程系统 Tensorflow工具或者说深度学习本身就是一个连贯紧密的系统.一般的系统是一个自治独立的.能实现复杂功能的整体.系统的主要任务是对输入进行处理,以得到想要的输出结果.我们之前见过的很多系统都是线性的,就像汽车生产工厂的流水线一样,输入->系统处理->输出.系统内部由很多单一的基本部件构成,这些单一部件具有特定的功能,且需要稳定的特性:系统设计者通过特殊的连接方式,让这些简单部件进行连接,以使它们之间可以进行数据交流和信息互换,来达到相互配合而完成具体工作的目的
-
Tensorflow中k.gradients()和tf.stop_gradient()用法说明
上周在实验室开荒某个代码,看到中间这么一段,对Tensorflow中的stop_gradient()还不熟悉,特此周末进行重新并总结. y = xx + K.stop_gradient(rounded - xx) 这代码最终调用位置在tensoflow.python.ops.gen_array_ops.stop_gradient(input, name=None),关于这段代码为什么这样写的意义在文末给出. [stop_gradient()意义] 用stop_gradient生成损失函数w.r.
-
tensorflow中tf.slice和tf.gather切片函数的使用
tf.slice(input_, begin, size, name=None):按照指定的下标范围抽取连续区域的子集 tf.gather(params, indices, validate_indices=None, name=None):按照指定的下标集合从axis=0中抽取子集,适合抽取不连续区域的子集 输出: input = [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]], [[5, 5, 5], [6, 6, 6]]] tf.slice(
-
对tensorflow中tf.nn.conv1d和layers.conv1d的区别详解
在用tensorflow做一维的卷积神经网络的时候会遇到tf.nn.conv1d和layers.conv1d这两个函数,但是这两个函数有什么区别呢,通过计算得到一些规律. 1.关于tf.nn.conv1d的解释,以下是Tensor Flow中关于tf.nn.conv1d的API注解: Computes a 1-D convolution given 3-D input and filter tensors. Given an input tensor of shape [batch, in_wi
-
Tensorflow中的降维函数tf.reduce_*使用总结
在使用tensorflow时常常会使用到tf.reduce_*这类的函数,在此对一些常见的函数进行汇总 1.tf.reduce_sum tf.reduce_sum(input_tensor , axis = None , keep_dims = False , name = None , reduction_indices = None) 参数: input_tensor:要减少的张量.应该有数字类型. axis:要减小的尺寸.如果为None(默认),则缩小所有尺寸.必须在范围[-rank(in
-
tensorflow中tf.reduce_mean函数的使用
tf.reduce_mean 函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值. reduce_mean(input_tensor, axis=None, keep_dims=False, name=None, reduction_indices=None) 第一个参数input_tensor: 输入的待降维的tensor; 第二个参数axis: 指定的轴,如果不指定,则计算所有元素的均值; 第三个参数keep_d
-
TensorFlow中tf.batch_matmul()的用法
TensorFlow中tf.batch_matmul()用法 如果有两个三阶张量,size分别为 a.shape = [100, 3, 4] b.shape = [100, 4, 5] c = tf.batch_matmul(a, b) 则c.shape = [100, 3, 5] //将每一对 3x4 的矩阵与 4x5 的矩阵分别相乘.batch_size不变 100为张量的batch_size.剩下的两个维度为数据的维度. 不过新版的tensorflow已经移除了上面的函数,使用时换为tf.