python爬虫使用正则爬取网站的实现
本文章的所有代码和相关文章, 仅用于经验技术交流分享,禁止将相关技术应用到不正当途径,滥用技术产生的风险与本人无关。
本文章是自己学习的一些记录。欢迎各位大佬点评!
首先
今天是第一天写博客,感受到了博客的魅力,博客不仅能够记录每天的代码学习情况,并且可以当作是自己的学习笔记,以便在后面知识点不清楚的时候前来复习。这是第一次使用爬虫爬取网页,这里展示的是爬取豆瓣电影top250的整个过程,欢迎大家指点。
这里我只爬取了电影链接和电影名称,如果想要更加完整的爬取代码,请联系我。qq 1540741344 欢迎交流
开发工具: pycharm、chrome
分析网页
在开发之前你首先要去你所要爬取的网页提取出你要爬取的网页链接,并且将网页分析出你想要的内容。
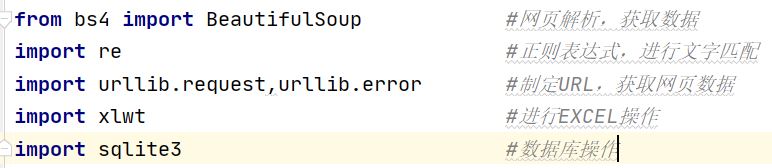
在开发之前首先要导入几个模块,模块描述如下,具体不知道怎么导入包的可以看我下一篇内容
首先定义几个函数,便于将各个步骤的工作分开便于代码管理,我这里是分成了7个函数,分别如下:
@主函数入口
if __name__=="__main__": #程序执行入口 main()
@捕获网页html内容 askURL(url)
这里的head的提取是在chrome中分析网页源码获得的,具体我也不做过多解释,大家可以百度
def askURL(url): #得到指定网页信息的内容 #爬取一个网页的数据
# 用户代理,本质上是告诉服务器,我们是以什么样的机器来访问网站,以便接受什么样的水平数据
head={"User-Agent":"Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 84.0.4147.89 Safari / 537.36"}
request=urllib.request.Request(url,headers=head) #request对象接受封装的信息,通过urllib携带headers访问信息访问url
response=urllib.request.urlopen(request) #用于接收返回的网页信息
html=response.read().decode("utf-8") #通过read方法读取response对象里的网页信息,使用“utf-8”
return html
@将baseurl里的内容进行逐一解析 getData(baseURL)
这里面的findlink和findname是正则表达式,可以首先定义全局变量
findlink=r'<a class="" href="(.*?)"' findname=r'<span class="title">(.*?)</span>'
def getData(baseURL):
dataList=[] #初始化datalist用于存储获取到的数据
for i in range(0,10):
url=baseURL+str(i*25)
html=askURL(url) #保存获取到的源码
soup=BeautifulSoup(html,"html.parser") #对html进行逐一解析,使用html.parser解析器进行解析
for item in soup.find_all("div",class_="item"): #查找符合要求的字符串 ,形成列表,find_all是查找所有的class是item的div
data=[] #初始化data,用于捕获一次爬取一个div里面的内容
item=str(item) #将item数据类型转化为字符串类型
# print(item)
link=re.findall(findlink,item)[0] #使用re里的findall方法根据正则提取item里面的电影链接
data.append(link) #将网页链接追加到data里
name=re.findall(findname,item)[0] #使用re里的findall方法根据正则提取item里面的电影名字
data.append(name) #将电影名字链接追加到data里
# print(link)
# print(name)
dataList.append(data) #将捕获的电影链接和电影名存到datalist里面
return dataList #返回一个列表,里面存放的是每个电影的信息
print(dataList)
@保存捕获的数据到excel saveData(dataList,savepath)
def saveData(dataList,savepath): #保存捕获的内容到excel里,datalist是捕获的数据列表,savepath是保存路径
book=xlwt.Workbook(encoding="utf-8",style_compression=0)#初始化book对象,这里首先要导入xlwt的包
sheet=book.add_sheet("test",cell_overwrite_ok=True) #创建工作表
col=["电影详情链接","电影名称"] #列名
for i in range(0,2):
sheet.write(0,i,col[i]) #将列名逐一写入到excel
for i in range(0,250):
data=dataList[i] #依次将datalist里的数据获取
for j in range(0,2):
sheet.write(i+1,j,data[j]) #将data里面的数据逐一写入
book.save(savepath)
@保存捕获的数据到数据库
def saveDataDb(dataList,dbpath):
initDb(dbpath) #用一个函数初始化数据库
conn=sqlite3.connect(dbpath) #初始化数据库
cur=conn.cursor() #获取游标
for data in dataList:
for index in range(len(data)):
data[index]='"'+data[index]+'" ' #将每条数据都加上""
#每条数据之间用,隔开,定义sql语句的格式
sql='''
insert into test(link,name) values (%s)
'''%','.join (data)
cur.execute(sql) #执行sql语句
conn.commit() #提交数据库操作
conn.close()
print("爬取存入数据库成功!")
@初始化数据库 initDb(dbpath)
def initDb(dbpath):
conn=sqlite3.connect(dbpath)
cur=conn.cursor()
sql='''
create table test(
id integer primary key autoincrement,
link text,
name varchar
)
'''
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
@main函数,用于调用其他函数 main()
def main(): dbpath="testSpider.db" #用于指定数据库存储路径 savepath="testSpider.xls" #用于指定excel存储路径 baseURL="https://movie.douban.com/top250?start=" #爬取的网页初始链接 dataList=getData(baseURL) saveData(dataList,savepath) saveDataDb(dataList,dbpath)
点击运行就可以看到在左侧已经生成了excel和DB文件
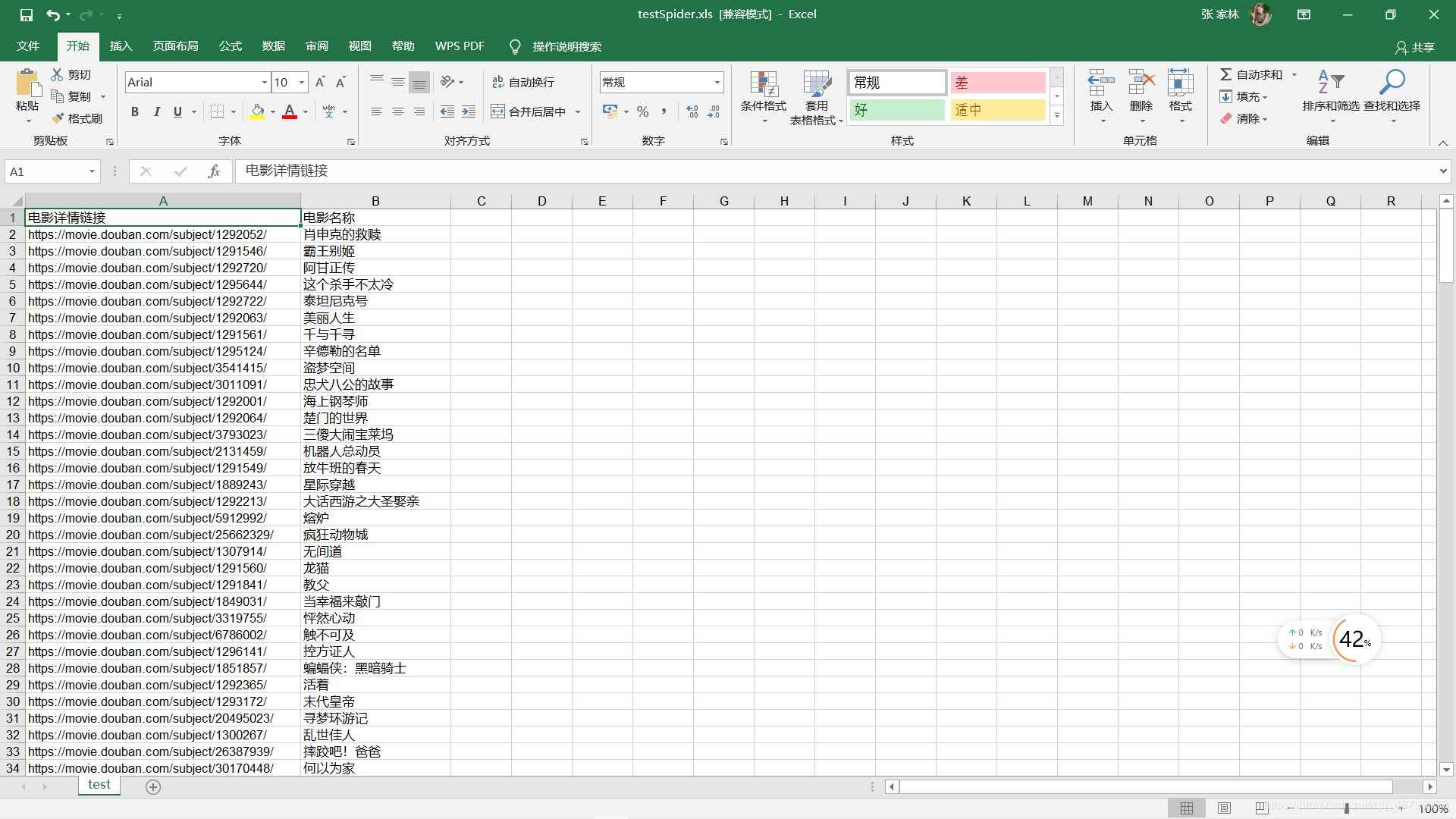
excel可以直接打开
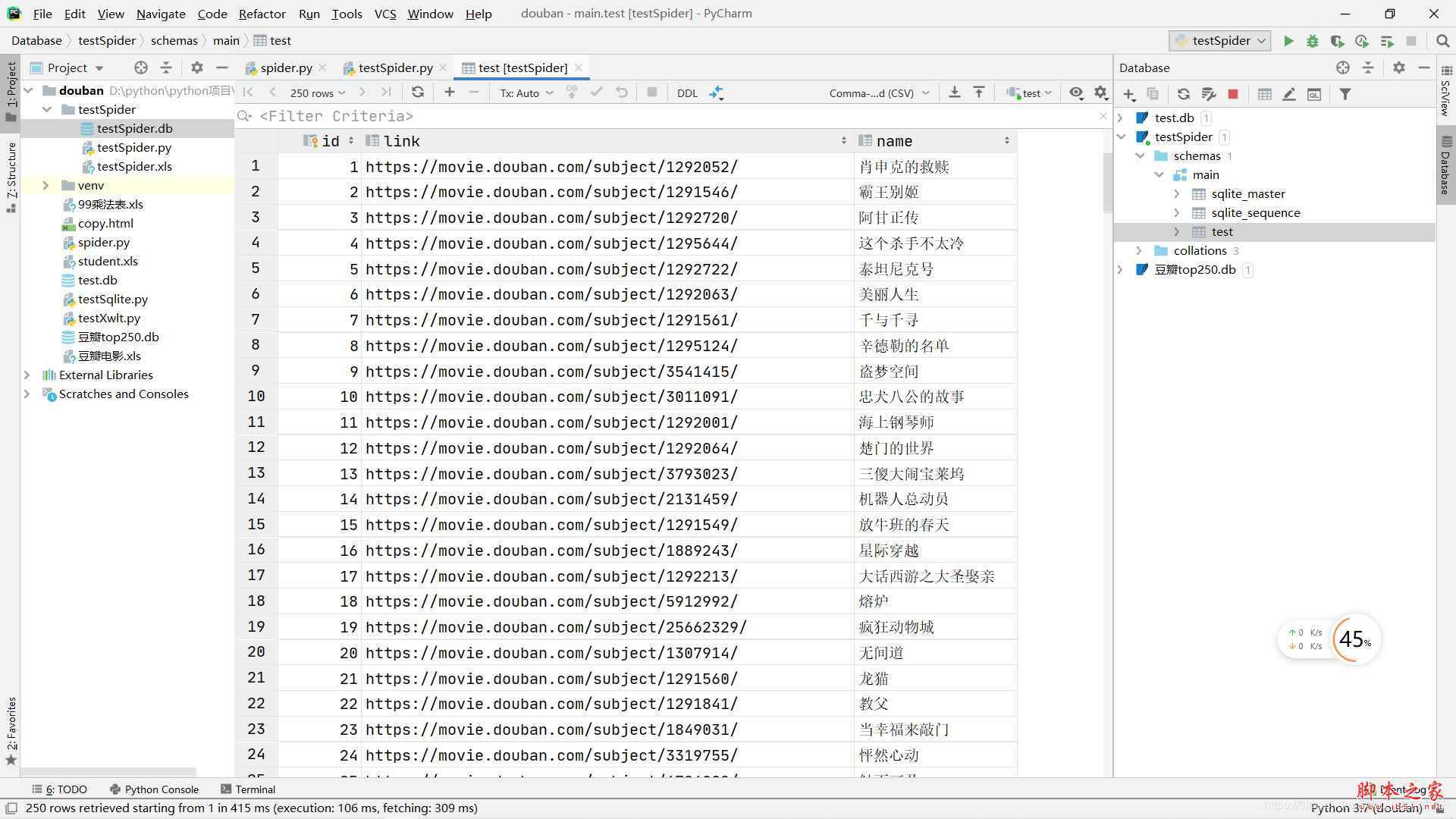
DB文件双击之后会在右边打开
到这里爬虫的基本内容就已经结束了,如果有什么不懂或者想交流的地方可以加我qq 1540741344
以下附上整个代码
import re #网页解析,获取数据
from bs4 import BeautifulSoup #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网页数据
import xlwt
import sqlite3
findlink=r'<a class="" href="(.*?)"'
findname=r'<span class="title">(.*?)</span>'
def main():
dbpath="testSpider.db" #用于指定数据库存储路径
savepath="testSpider.xls" #用于指定excel存储路径
baseURL="https://movie.douban.com/top250?start=" #爬取的网页初始链接
dataList=getData(baseURL)
saveData(dataList,savepath)
saveDataDb(dataList,dbpath)
def askURL(url): #得到指定网页信息的内容 #爬取一个网页的数据
# 用户代理,本质上是告诉服务器,我们是以什么样的机器来访问网站,以便接受什么样的水平数据
head={"User-Agent":"Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 84.0.4147.89 Safari / 537.36"}
request=urllib.request.Request(url,headers=head) #request对象接受封装的信息,通过urllib携带headers访问信息访问url
response=urllib.request.urlopen(request) #用于接收返回的网页信息
html=response.read().decode("utf-8") #通过read方法读取response对象里的网页信息,使用“utf-8”
return html #返回捕获的网页内容,此时还是未处理过的
def getData(baseURL):
dataList=[] #初始化datalist用于存储获取到的数据
for i in range(0,10):
url=baseURL+str(i*25)
html=askURL(url) #保存获取到的源码
soup=BeautifulSoup(html,"html.parser") #对html进行逐一解析,使用html.parser解析器进行解析
for item in soup.find_all("div",class_="item"): #查找符合要求的字符串 ,形成列表,find_all是查找所有的class是item的div
data=[] #初始化data,用于捕获一次爬取一个div里面的内容
item=str(item) #将item数据类型转化为字符串类型
# print(item)
link=re.findall(findlink,item)[0] #使用re里的findall方法根据正则提取item里面的电影链接
data.append(link) #将网页链接追加到data里
name=re.findall(findname,item)[0] #使用re里的findall方法根据正则提取item里面的电影名字
data.append(name) #将电影名字链接追加到data里
# print(link)
# print(name)
dataList.append(data) #将捕获的电影链接和电影名存到datalist里面
return dataList #返回一个列表,里面存放的是每个电影的信息
print(dataList)
def saveData(dataList,savepath): #保存捕获的内容到excel里,datalist是捕获的数据列表,savepath是保存路径
book=xlwt.Workbook(encoding="utf-8",style_compression=0)#初始化book对象,这里首先要导入xlwt的包
sheet=book.add_sheet("test",cell_overwrite_ok=True) #创建工作表
col=["电影详情链接","电影名称"] #列名
for i in range(0,2):
sheet.write(0,i,col[i]) #将列名逐一写入到excel
for i in range(0,250):
data=dataList[i] #依次将datalist里的数据获取
for j in range(0,2):
sheet.write(i+1,j,data[j]) #将data里面的数据逐一写入
book.save(savepath) #保存excel文件
def saveDataDb(dataList,dbpath):
initDb(dbpath) #用一个函数初始化数据库
conn=sqlite3.connect(dbpath) #初始化数据库
cur=conn.cursor() #获取游标
for data in dataList:
for index in range(len(data)):
data[index]='"'+data[index]+'" ' #将每条数据都加上""
#每条数据之间用,隔开,定义sql语句的格式
sql='''
insert into test(link,name) values (%s)
'''%','.join (data)
cur.execute(sql) #执行sql语句
conn.commit() #提交数据库操作
conn.close()
print("爬取存入数据库成功!")
def initDb(dbpath):
conn=sqlite3.connect(dbpath)
cur=conn.cursor()
sql='''
create table test(
id integer primary key autoincrement,
link text,
name varchar
)
'''
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
if __name__=="__main__": #程序执行入口
main()
到此这篇关于python爬虫使用正则爬取网站的实现的文章就介绍到这了,更多相关python正则爬取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python3使用正则表达式爬取内涵段子示例
本文实例讲述了Python3使用正则表达式爬取内涵段子的方法.分享给大家供大家参考,具体如下: 似乎正则在爬虫中用的不是很广泛,但是也是基本功需要我们去掌握. 先将内涵段子网页爬取下来,之后利用正则进行匹配,匹配完成后将匹配的段子写入文本文档内.代码如下: # -*- coding:utf-8 -*- from urllib import request as urllib2 import re # 利用正则表达式爬取内涵段子 url = r'http://www.neihanpa.com/ar
-
python爬虫 正则表达式使用技巧及爬取个人博客的实例讲解
这篇博客是自己<数据挖掘与分析>课程讲到正则表达式爬虫的相关内容,主要简单介绍Python正则表达式爬虫,同时讲述常见的正则表达式分析方法,最后通过实例爬取作者的个人博客网站.希望这篇基础文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵.真的太忙了,太长时间没有写博客了,抱歉~ 一.正则表达式 正则表达式(Regular Expression,简称Regex或RE)又称为正规表示法或常规表示法,常常用来检索.替换那些符合某个模式的文本,它首先设定好了一些特殊的字及字符组合,通过组合的&
-
python使用BeautifulSoup与正则表达式爬取时光网不同地区top100电影并对比
前言 还有一年多就要毕业了,不准备考研的我要着手准备找实习及工作了,所以一直没有更新. 因为Python是自学不久,发现很久不用的话以前学过的很多方法就忘了,今天打算使用简单的BeautifulSoup和一点正则表达式的方法来爬一下top100电影,当然,我们并不仅是使用爬虫爬取数据,这样的话,数据中存在很多的对人有用的信息则被忽略了.所以,爬取数据只是开头,对这些数据根据意愿进行分析,或许能有额外的收获. 注:本人还是Python菜鸟,若有错误欢迎指正 本次我们爬取时光网(http://www
-
python正则爬取某段子网站前20页段子(request库)过程解析
首先还是谷歌浏览器抓包对该网站数据进行分析,结果如下: 该网站地址:http://www.budejie.com/text 该网站数据都是通过html页面进行展示,网站url默认为第一页,http://www.budejie.com/text/2为第二页,以此类推 对网站的内容段子所处位置进行分析,发现段子内容都是在一个 a 标签中 坑还是有的,这是我第一次写的正则: content_list = re.findall(r'<a href="/detail-.*" rel=&qu
-
python正则表达式爬取猫眼电影top100
用正则表达式爬取猫眼电影top100,具体内容如下 #!/usr/bin/python # -*- coding: utf-8 -*- import json # 快速导入此模块:鼠标先点到要导入的函数处,再Alt + Enter进行选择 from multiprocessing.pool import Pool #引入进程池 import requests import re import csv from requests.exceptions import RequestException
-
Python通过正则库爬取淘宝商品信息代码实例
使用正则库爬取淘宝商品的商品信息,首先我们需要确定想要爬取的对象 我们在淘宝里搜索"python",出来的结果 从url连接中可以得到搜索商品的关键字是"q=",所以我们要用的起始url为:https://s.taobao.com/search?q=python 然后翻页,经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44) 所以可以根据关键字"s=",来设置爬取的深度(爬取多少页)
-
Python如何使用正则表达式爬取京东商品信息
京东(JD.com)是中国最大的自营式电商企业,2015年第一季度在中国自营式B2C电商市场的占有率为56.3%.如此庞大的一个电商网站,上面的商品信息是海量的,小编今天就带小伙伴利用正则表达式,并且基于输入的关键词来实现主题爬虫. 首先进去京东网,输入自己想要查询的商品,小编在这里以关键词"狗粮"作为搜索对象,之后得到后面这一串网址: https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其实参数%
-
python爬虫使用正则爬取网站的实现
本文章的所有代码和相关文章, 仅用于经验技术交流分享,禁止将相关技术应用到不正当途径,滥用技术产生的风险与本人无关. 本文章是自己学习的一些记录.欢迎各位大佬点评! 首先 今天是第一天写博客,感受到了博客的魅力,博客不仅能够记录每天的代码学习情况,并且可以当作是自己的学习笔记,以便在后面知识点不清楚的时候前来复习.这是第一次使用爬虫爬取网页,这里展示的是爬取豆瓣电影top250的整个过程,欢迎大家指点. 这里我只爬取了电影链接和电影名称,如果想要更加完整的爬取代码,请联系我.qq 1540741
-
Python爬虫DOTA排行榜爬取实例(分享)
1.分析网站 打开开发者工具,我们观察到排行榜的数据并没有在doc里 doc文档 在Javascript里我么可以看到下面代码: ajax的post方法异步请求数据 在 XHR一栏里,我们找到所请求的数据 json存储的数据 请求字段为: post请求字段 2.伪装浏览器,并将json数据存入excel里面 获取信息 将数据保存到excel中 3.结果展示 以上这篇Python爬虫DOTA排行榜爬取实例(分享)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python爬虫小例子——爬取51job发布的工作职位
概述 不知从何时起,Python和爬虫就如初恋一般,情不知所起,一往而深,相信很多朋友学习Python,都是从爬虫开始,其实究其原因,不外两方面:其一Python对爬虫的支持度比较好,类库众多.其二Pyhton的语法简单,入门容易.所以两者形影相随,不离不弃,本文主要以一个简单的小例子,简述Python在爬虫方面的简单应用,仅供学习分享使用,如有不足之处,还请指正. 涉及知识点 本例主要爬取51job发布的工作职位,用到的知识点如下: 开发环境及工具:主要用到Python3.7 ,IDE为PyC
-
Python爬虫进阶之爬取某视频并下载的实现
这几天在家闲得无聊,意外的挖掘到了一个资源网站(你懂得),但是网速慢广告多下载不了种种原因让我突然萌生了爬虫的想法. 下面说说流程: 一.网站分析 首先进入网站,F12检查,本来以为这种低端网站很好爬取,是我太低估了web主.可以看到我刷新网页之后,出现了很多js文件,并且响应获取的代码与源代码不一样,这就不难猜到这个网站是动态加载页面. 目前我知道的动态网页爬取的方法只有这两种:1.从网页响应中找到JS脚本返回的JSON数据:2.使用Selenium对网页进行模拟访问.源代码问题好解决,重要的
-
Python爬虫UA伪装爬取的实例讲解
在使用python爬取网站信息时,查看爬取完后的数据发现,数据并没有被爬取下来,这是因为网站中有UA这种请求载体的身份标识,如果不是基于某一款浏览器爬取则是不正常的请求,所以会爬取失败.本文介绍Python爬虫采用UA伪装爬取实例. 一.python爬取失败原因如下: UA检测是门户网站的服务器会检测对应请求的载体身份标识,如果检测到请求的载体身份标识为某一款浏览器,说明该请求是一个正常的请求.如果检测到请求的载体身份标识不是基于某一款浏览器的.则表示该请求为不正常的请求,则服务器端就很有可能会
-
Python爬虫实战之爬取某宝男装信息
目录 知识点介绍 实现步骤 1. 分析目标网站 2. 获取单个商品界面 3. 获取多个商品界面 4. 获取商品信息 5. 保存到MySQL数据库 完整代码 知识点介绍 本次爬取用到的知识点有: 1. selenium 2. pymysql 3 pyquery 实现步骤 1. 分析目标网站 1. 打开某宝首页, 输入"男装"后点击"搜索", 则跳转到"男装"的搜索界面. 2. 空白处"右击"再点击"检查"审
-
Python爬虫利用多线程爬取 LOL 高清壁纸
目录 页面分析 抓取思路 数据采集 程序运行 总结 前言: 随着移动端的普及出现了很多的移动 APP,应用软件也随之流行起来. 最近又捡起来了英雄联盟手游,感觉还行,PC 端英雄联盟可谓是爆火的游戏,不知道移动端的英雄联盟前途如何,那今天我们使用到多线程的方式爬取 LOL 官网英雄高清壁纸. 页面分析 目标网站:英雄联盟 官网界面如图所示,显而易见,一个小图表示一个英雄,我们的目的是爬取每一个英雄的所有皮肤图片,全部下载下来并保存到本地. 次级页面 上面的页面我们称为主页面,次级页面也就是每一个
-
Python爬虫简单运用爬取代理IP的实现
功能1: 爬取西拉ip代理官网上的代理ip 环境:python3.8+pycharm 库:requests,lxml 浏览器:谷歌 IP地址:http://www.xiladaili.com/gaoni/ 分析网页源码: 选中div元素后右键找到Copy再深入子菜单找到Copy Xpath点击一下就复制到XPath 我们复制下来的Xpth内容为:/html/body/div/div[3]/div[2]/table/tbody/tr[50]/td[1] 虽然可以查出来ip,但不利于程序自动爬取所有
-
Python爬虫实战之爬取携程评论
一.分析数据源 这里的数据源是指html网页?还是Aajx异步.对于爬虫初学者来说,可能不知道怎么判断,这里辰哥也手把手过一遍. 提示:以下操作均不需要登录(当然登录也可以) 咱们先在浏览器里面搜索携程,然后在携程里面任意搜索一个景点:长隆野生动物世界,这里就以长隆野生动物世界为例,讲解如何去爬取携程评论数据. 页面下方则是评论数据 从上面两张图可以看出,点击评论下一页,浏览器的链接没有变化,说明数据是Ajax异步请求.因此我们就找到了数据是异步加载过来的,这时候需要去network里面是查
-
Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session