selenium 反爬虫之跳过淘宝滑块验证功能的实现代码
在处理问题的之前,给大家个第一个锦囊!
你需要将chorme更新到最新版版本84,下载对应的chorme驱动 链接:http://chromedriver.storage.googleapis.com/index.html
注意 划重点!!一定要做这一步,因为我用的83的chorme他是不行滴,~~~~~~~
问题
1.一周前我的滑块验证代码还是可以OK的,完全没问题!附代码 low一眼
url = "https://login.taobao.com/member/login.jhtml"
browser.get(url)
browser.maximize_window() # 最大化
# 填写用户名密码
user = '*****'
password = '*******'
time.sleep(8)
iframe = browser.find_element_by_xpath('//div[@class="bokmXvaDlH"]//iframe')
print(iframe)
browser.switch_to.frame(iframe)
browser.find_element_by_xpath('//*[@id="fm-login-id"]').send_keys(id)
browser.find_element_by_xpath('//*[@id="fm-login-password"]').send_keys(password)
time.sleep(2)
# 获取滑块的大小
span_background = browser.find_element_by_xpath('//*[@id="nc_1__scale_text"]/span')
span_background_size = span_background.size
print(span_background_size)
# 获取滑块的位置
button = browser.find_element_by_xpath('//*[@id="nc_1_n1z"]')
button_location = button.location
print(button_location)
# 拖动操作:drag_and_drop_by_offset
# 将滑块的位置由初始位置,右移一个滑动条长度(即为x坐标在滑块位置基础上,加上滑动条的长度,y坐标保持滑块的坐标位置)
x_location = span_background_size["width"]
y_location = button_location["y"]
print(x_location, y_location)
action = ActionChains(browser)
source = browser.find_element_by_xpath('//*[@id="nc_1_n1z"]')
action.click_and_hold(source).perform()
action.move_by_offset(300, 0)
action.release().perform()
time.sleep(1)
# 登录
browser.find_element_by_xpath('//*[@id="login-form"]/div[4]/button').click()
print('登录成功\n')
完全可以会很好的进入淘宝,游刃有余
2.淘宝爸爸一周后就给我泼凉水,增加了自己的反爬虫机制,出现如下错误。

刚开始我以为是我频繁登录,导致淘宝的机器人识别我为代码进入。一般之前都是会在30分钟内解封。结果一天之后还是存在这个问题。查阅资料,翻了我的葵花宝典还是没有解决办法。后来看到一个文章,可能是淘宝再次更新了自己对selenium的验证,导致我不在成为漏网之鱼。唉唉唉,导致我3天没有解决。现在我把自己的坑和解决办法给大家分享一哈。成功的再次成为漏网之鱼,哈哈哈!
步骤
1.首先很多熟悉JS的人都知道淘宝会检测window.navigator.webdriver(js检测特征之一),但是即使设置了"undefined"还是败下来,看看
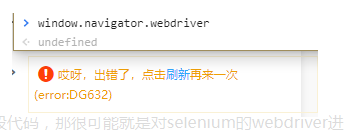
2.这时候细心的就需要观察一下他的全局JS,(这个是我参考别人的思路)你会发现淘宝爸爸在你浏览器内置的JS中有这么一段恐怖的代码

就是这个标黄色的东西,不会容易被发现的东西被检测到你是selenium进入,是不是特别坑!那我们接下来就需要干掉他。
3.这个时候仔细想一下,我们是通过什么打开浏览器呢?是的,知道的都会说webdriver.exe这个驱动。那我们就从他开始下手,当你打开webdriver.exe它后你会发现其中的问题!
注意:划重点!!!怎么打开和修改webdriver.exe。很多人都是乱码,之前我看到Windows系统采用nodepad++去打开就可以了,注意我的不行!你们可以试一下。(有的人是可以的,但是我的老师电脑不可以),然后我就找了一个办法,需要大家会一点vim操作,很简单的!准确的说就是Linux去解决,因为他不存在编码问题,不会像傻Windows,特别蠢!!开发人员最好还是用Linux系统吧!
经过我认真不负努力的搜索,诶找到一个靠谱的文章,哈哈!外国的‘知乎'
文章链接:https://stackoverflow.com/questions/33225947/can-a-website-detect-when-you-are-using-selenium-with-chromedriver
就是他!

就是这段翻译后的操作。
注意 划重点 !!采用Linux系统的vim进去后你看到的也是乱码!!哈哈,but和Windows的乱码是不一样的,他会让你找到“$cdc_asdjflasutopfhvcZLmcfl_”这个字符串的,神奇吧。这就是Linux的强大!!
不会Linux命令的童鞋可以自己搜索一下,很简单的。修改后记得要保存哦!
4.可能大家觉得到这里就可以了,NO NO NO 这样子你还是登录不掉的。需要最后一个锦囊妙计!!
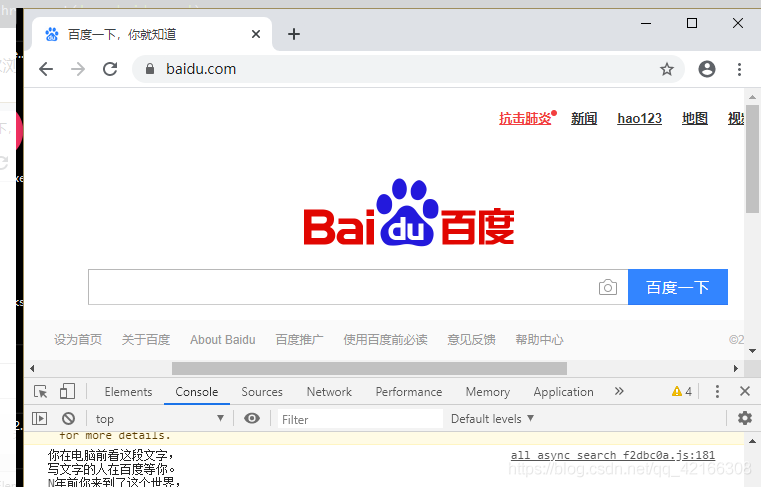
具体就是 你需要关闭chorme开发者模式,关闭自动测试状态,还需要将大家都熟知的把window.navigator.webdriver设为"undefined"。可能说的不太明白,图片帮你理解

# chrome_options 初始化选项
chrome_options = webdriver.ChromeOptions()
# 设置浏览器初始 位置x,y & 宽高x,y
chrome_options.add_argument(f'--window-position={217},{172}')
chrome_options.add_argument(f'--window-size={1200},{1000}')
# 关闭自动测试状态显示 // 会导致浏览器报:请停用开发者模式
# window.navigator.webdriver还是返回True,当返回undefined时应该才可行。
chrome_options.add_experimental_option("excludeSwitches", ['enable-automation'])
加上这个代码会关闭“正受到自动测试软件的控制“的显示
# 通过浏览器的dev_tool在get页面钱将.webdriver属性改为"undefined"
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})""",
})
加上这个代码可以关闭开发者模式
# 通过浏览器的dev_tool在get页面钱将.webdriver属性改为"undefined"
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})""",
})
最后我们通过提前运行js的方法,把window.navigator.webdriver设为"undefined"!
OK !!大功告成!!通过这么一步步下来,你会发现 我的天居然没有滑块!开森!!
总结
到此这篇关于selenium 反爬虫之跳过淘宝滑块验证(2020/8)的文章就介绍到这了,更多相关selenium 跳过淘宝滑块验证内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
利用selenium爬虫抓取数据的基础教程
写在前面 本来这篇文章该几个月前写的,后来忙着忙着就给忘记了. ps:事多有时候反倒会耽误事. 几个月前,记得群里一朋友说想用selenium去爬数据,关于爬数据,一般是模拟访问某些固定网站,将自己关注的信息进行爬取,然后再将爬出的数据进行处理. 他的需求是将文章直接导入到富文本编辑器去发布,其实这也是爬虫中的一种. 其实这也并不难,就是UI自动化的过程,下面让我们开始吧. 准备工具/原料 1.java语言 2.IDEA开发工具 3.jdk1.8 4.selenium-server-standa
-
使用selenium模拟登录解决滑块验证问题的实现
本次主要是使用selenium模拟登录网页端的TX新闻,本来最开始是模拟请求的,但是某一天突然发现,部分账号需要经过滑块验证才能正常登录,如果还是模拟请求,需要的参数太多了,找的心累.不过好在TX的滑块验证是他们自己开发的,没有极验那么复杂,当然相反的,想要模拟就得自己去一点点探索了,毕竟对极验滑块的破解,网上已经可以找到现成的代码来用了.下面说一下模拟的实现过程和我遇见的问题. 1.登录入口 我是通过点击打开链接来当做登录入口的 部分代码实现: driver = webdriver.Chrom
-
selenium 反爬虫之跳过淘宝滑块验证功能的实现代码
在处理问题的之前,给大家个第一个锦囊! 你需要将chorme更新到最新版版本84,下载对应的chorme驱动 链接:http://chromedriver.storage.googleapis.com/index.html 注意 划重点!!一定要做这一步,因为我用的83的chorme他是不行滴,~~~~~~~ 问题 1.一周前我的滑块验证代码还是可以OK的,完全没问题!附代码 low一眼 url = "https://login.taobao.com/member/login.jhtml&quo
-

Android仿淘宝搜索联想功能的示例代码
现在不少应用都提供了搜索功能,有些还提供了搜索联想.对于一个搜索联想功能,最基本的实现流程为:客户端通过监听输入框内容的变化,当输入框发生变化之后就会回调afterTextChanged方法,客户端利用当前输入框内的文字向服务器发起请求,服务器返回与该搜索文字关联的结果给客户端进行展示.服务器那边,一般要做内存缓存池,就是把有可能的结果都放在内存中. 效果图 APP这边也有几个重要的问题需要我们思考 当搜索词为空时,不应该发起网络请求. 在用户连续输入的情况下,可能会发起某些不必要的请求.例如用
-
python2.7+selenium2实现淘宝滑块自动认证功能
本文为大家分享了python2.7+selenium2实现淘宝滑块自动认证的具体代码,供大家参考,具体内容如下 1.编译环境 操作系统:win7:语言:python2.7+selenium2:ide:pycharm:浏览器:IE10,chrome 2.1意外开始 今天登录淘宝时候发现吧密码搞忘了,选择找回密码时淘宝居然加了滑块认证. 恰巧自己也在学习selenium,就想试一试能不能实现自动拖动滑块. 2.2 度娘查找 由于自己没多少思路,第一选择就是问度娘,终于找到一篇文章,该文章使用C#实现
-
Python进阶之使用selenium爬取淘宝商品信息功能示例
本文实例讲述了Python进阶之使用selenium爬取淘宝商品信息功能.分享给大家供大家参考,具体如下: # encoding=utf-8 __author__ = 'Jonny' __location__ = '西安' __date__ = '2018-05-14' ''' 需要的基本开发库文件: requests,pymongo,pyquery,selenium 开发流程: 搜索关键字:利用selenium驱动浏览器搜索关键字,得到查询后的商品列表 分析页码并翻页:得到商品页码数,模拟翻页
-
python 爬虫一键爬取 淘宝天猫宝贝页面主图颜色图和详情图的教程
实例如下所示: import requests import re,sys,os import json import threading import pprint class spider: def __init__(self,sid,name): self.id = sid self.headers = { "Accept":"text/html,application/xhtml+xml,application/xml;", "Accept-Enc
-
PHP正则+Snoopy抓取框架实现的抓取淘宝店信誉功能实例
本文实例讲述了PHP正则+Snoopy抓取框架实现的抓取淘宝店信誉功能.分享给大家供大家参考,具体如下: <?php header("Content-Type:text/html;charset=gbk"); include "Snoopy.class.php"; $snoopy = new Snoopy; $snoopy->fetch("http://rate.taobao.com/user-rate-f01d9cb1245a22fcea47
-
原生JS实现仿淘宝网左侧商品分类菜单效果代码
本文实例讲述了原生JS实现仿淘宝网左侧商品分类菜单效果代码.分享给大家供大家参考.具体如下: 这是一款原生JS实现的仿淘宝网左侧商品分类菜单效果代码,JavaScript技术实现,兼容各主流浏览器.自己再修改一下CSS菜单,它会变得更漂亮. 运行效果截图如下: 在线演示地址如下: http://demo.jb51.net/js/2015/js-f-taobao-pro-menu-style-codes/ 具体代码如下: <!DOCTYPE html> <head> <titl
-
jquery实现类似淘宝星星评分功能实例
本文实例讲述了jquery实现类似淘宝星星评分功能的方法,分享给大家供大家参考之用.具体方法如下: html部分代码如下: <body> <div id="div"> <ul> <li>☆</li> <li>☆</li> <li>☆</li> <li>☆</li> <li>☆</li> </ul> </div>
-
python,Django实现的淘宝客登录功能示例
本文实例讲述了python,Django实现的淘宝客登录功能.分享给大家供大家参考,具体如下: 在整理python,django资料的时候,发现了这个东西,也许是当初某位网友或者朋友发过来参考或者一起探讨修改的东西,现在不记得了,也许taobao的接口都变了也有可能,但总体来说还是有参考价值的,主要是做淘宝客客或者返利网会用到taobao登录而用的. 参考代码如下: #!/usr/bin/python #coding:utf-8 import datetime, urllib, base64,
-
vue仿淘宝滑动验证码功能(样式模仿)
我们知道验证码的目的 是为了验证到底是人还是机器. 淘宝滑动验证码会采集用户的操作数据,环境数据等等,通过算法加密成一个字符串,提交到服务器分析,判断是不是人工在操作. 我这里写的只是模仿了样式,并没有进行那些复杂的操作,所以并不安全(不能判断人还是机器). 因为touch事件和mouse事件不同,和获取clientX在移动端和pc端也不同!!!所以分两端 下面有PC端和移动端!!!(2019-03-12更新) 本文基于vue,引入下面组件 可以直接使用 1.实际效果 2.PC端!!! vue组