Python描述数据结构学习之哈夫曼树篇
前言
本篇章主要介绍哈夫曼树及哈夫曼编码,包括哈夫曼树的一些基本概念、构造、代码实现以及哈夫曼编码,并用Python实现。
1. 基本概念
哈夫曼树(Huffman(Huffman(Huffman Tree)Tree)Tree),又称为最优二叉树,指的是带权路径长度最小的二叉树。树的带权路径常记作:

其中,nnn为树中叶子结点的数目,wkw_kwk为第kkk个叶子结点的权值,lkl_klk为第kkk个叶子结点与根结点的路径长度。
带权路径长度是带权结点和根结点之间的路径长度与该结点的权值的乘积。有关带权结点、路径长度的概念请参阅这篇博客。
对于含有nnn个叶子结点的哈夫曼树,其共有2n−12n-12n−1个结点。因为在构造哈夫曼树的过程中,每次都是以两颗二叉树为子树创建一棵新的二叉树,因此哈夫曼树中不存在度为1的结点,即n1=0n_1=0n1=0,由二叉树的性质可知,叶子结点数目n0=n2+1n_0=n_2+1n0=n2+1,所以n2=n0−1n_2=n_0-1n2=n0−1,总结点数目为n=n0+n1+n2=n+n−1=2n−1n=n_0+n_1+n_2=n+n-1=2n-1n=n0+n1+n2=n+n−1=2n−1。
2. 构造过程及实现
给定nnn棵仅含根结点的二叉树T1,T2,…,TnT_1,T_2,\dots,T_nT1,T2,…,Tn,它们的权值分别为w1,w2,…,wnw_1,w_2,\dots,w_nw1,w2,…,wn,将它们放入到一个集合FFF中,即F={T1,T2,…,Tn}F=\{T_1,T_2,\dots,T_n\}F={T1,T2,…,Tn};然后在集合FFF中选取两棵权值最小的根结点构造一棵新的二叉树,使新二叉树的根结点的权值等于其左、右子树根结点的权值之和;再然后将选中的那两个结点从集合FFF中删除,将新的二叉树添加到FFF中;继续重复上述操作,直至集合FFF中只剩一棵二叉树为止。
比如F={(A,3),(B,7),(C,2),(D,11),(E,13),(F,15),(G,9)}F=\{(A,3),(B,7),(C,2),(D,11),(E,13),(F,15),(G,9)\}F={(A,3),(B,7),(C,2),(D,11),(E,13),(F,15),(G,9)},它构造出来的哈夫曼树就是下面这棵二叉树:

代码实现:
class HuffmanTreeNode(object): def __init__(self): self.data = '#' self.weight = -1 self.parent = None self.lchild = None self.rchild = None class HuffmanTree(object): def __init__(self, data_list): self.nodes = [] # 按权重从大到小进行排列 for val in data_list: newnode = HuffmanTreeNode() newnode.data = val[0] newnode.weight = val[1] self.nodes.append(newnode) self.nodes = sorted(self.nodes, key=lambda node: node.weight, reverse=True) print([(node.data, node.weight) for node in self.nodes]) def CreateHuffmanTree(self): # 这里注意区分 # TreeNode = self.nodes[:] 变量TreeNode, 这个相当于深拷贝, TreeNode变化不影响nodes # TreeNode = self.nodes 指针TreeNode与nodes共享一个地址, 相当于浅拷贝, TreeNode变化会影响nodes TreeNode = self.nodes[:] if len(TreeNode) > 0: while len(TreeNode) > 1: letfTreeNode = TreeNode.pop() rightTreeNode = TreeNode.pop() newNode = HuffmanTreeNode() newNode.lchild = letfTreeNode newNode.rchild = rightTreeNode newNode.weight = letfTreeNode.weight + rightTreeNode.weight letfTreeNode.parent = newNode rightTreeNode.parent = newNode self.InsertTreeNode(TreeNode, newNode) return TreeNode[0] def InsertTreeNode(self, TreeNode, newNode): length = len(TreeNode) if length > 0: temp = length - 1 while temp >= 0: if newNode.weight < TreeNode[temp].weight: TreeNode.insert(temp+1, newNode) return True temp -= 1 TreeNode.insert(0, newNode)
3. 哈夫曼编码
在数据通信时,假如我们要发送“ABCDEFG”“ABCDEFG”“ABCDEFG”这一串信息,我们并不会直接以这种形式进行发送,而是将其编码成计算机能够识别的二进制形式。根据编码类型可将其分为固定长度编码和可变长度编码,顾名思义,固定长度编码就是编码后的字符长度都相同,可变长度编码就是编码后的字符长度不相同。这两种类型有什么区别呢?我们来举例说明一下:
| AA | BB | CC | DD | EE | FF | GG | |
|---|---|---|---|---|---|---|---|
| 固定长度编码 | 000000 | 001001 | 010010 | 011011 | 100100 | 101101 | 110110 |
| 可变长度编码 | 00 | 11 | 0101 | 1010 | 1111 | 101101 | 110110 |
“ABCDEFG”“ABCDEFG”“ABCDEFG”这条信息使用固定长度编码后的长度为21,使用可变长度编码后的长度为14,报文变短,报文的传输效率会相应的提高。但如果传送的字符为“BD”“BD”“BD”,按可变长度编码后的报文为“111”“111”“111”,但是在译码是就会出现“BBB”,“BD”,“DB”“BBB”,“BD”,“DB”“BBB”,“BD”,“DB”多种结果,因此采用可变长度编码时需要注意任一字符不能是其他字符的前缀,符合这样的可变长度编码称为前缀编码。
报文最短可以引申到二叉树路径最短,即构造前缀编码的实质就是构造一棵哈夫曼树,通过这种形式获得的二进制编码称为哈夫曼编码。这里的权值就是报文中字符出现的概率,出现概率越高的字符我们用越短的字符表示。
以下表中的字符及其出现的概率为例来实现哈夫曼编码:
| 字符 | AA | BB | CC | DD | EE | FF | GG | HH |
|---|---|---|---|---|---|---|---|---|
| 出现概率 | 0.010.01 | 0.430.43 | 0.150.15 | 0.020.02 | 0.030.03 | 0.210.21 | 0.070.07 | 0.08 |
| 哈夫曼编码 | 101010101010 | 00 | 110110 | 101011101011 | 1010010100 | 111111 | 10111011 | 100 |
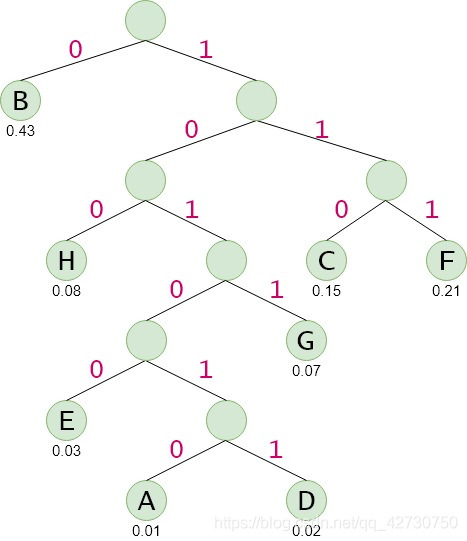
代码实现就是在哈夫曼树的基础上加一个编码的函数:
def HuffmanEncode(self, Root):
TreeNode = self.nodes[:]
code_result = []
for index in range(len(TreeNode)):
temp = TreeNode[index]
code_leaf = [temp.data]
code = ''
while temp is not Root:
if temp.parent.lchild is temp:
# 左分支
code = '0' + code
else:
# 右分支
code = '1' + code
temp = temp.parent
code_leaf.append(code)
code_result.append(code_leaf)
return code_result
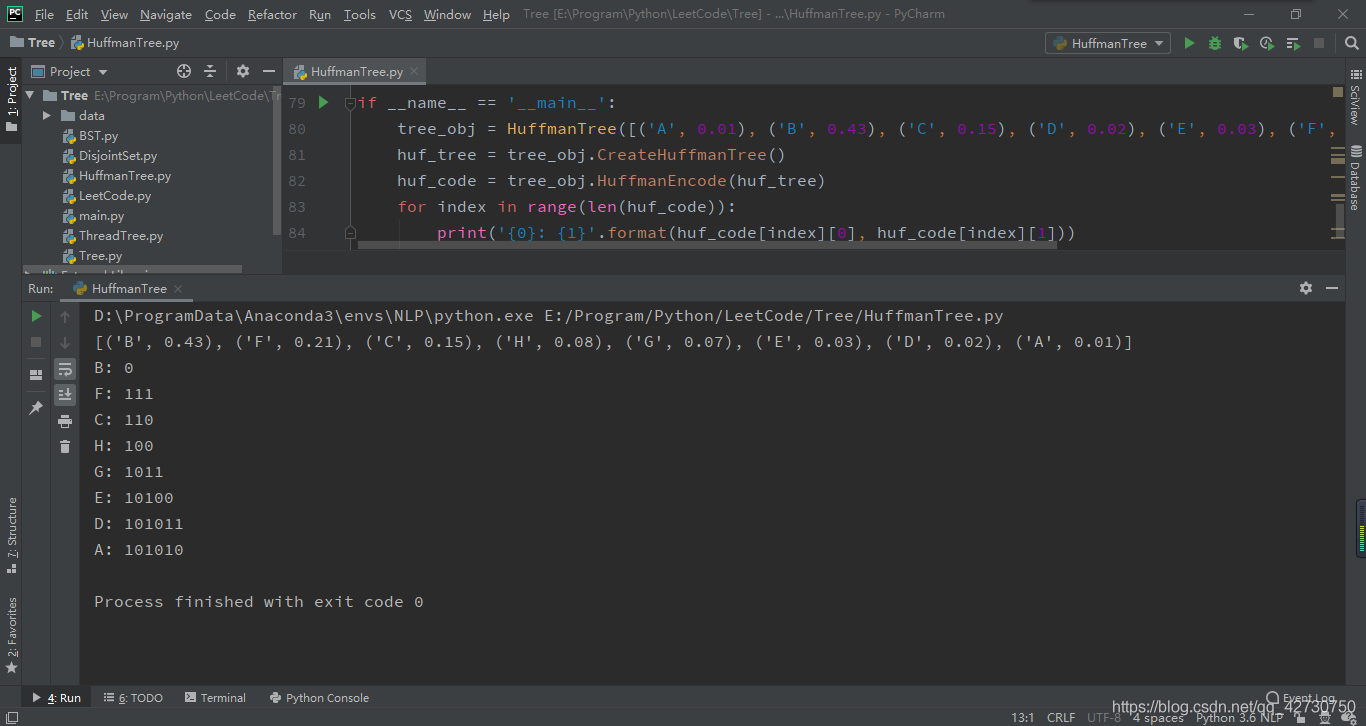
测试结果如下:
if __name__ == '__main__':
tree_obj = HuffmanTree([('A', 0.01), ('B', 0.43), ('C', 0.15), ('D', 0.02), ('E', 0.03), ('F', 0.21), ('G', 0.07), ('H', 0.08)])
huf_tree = tree_obj.CreateHuffmanTree()
huf_code = tree_obj.HuffmanEncode(huf_tree)
for index in range(len(huf_code)):
print('{0}: {1}'.format(huf_code[index][0], huf_code[index][1]))
总结
到此这篇关于Python描述数据结构学习之哈夫曼树篇的文章就介绍到这了,更多相关Python数据结构之哈夫曼树内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python数据结构之哈夫曼树定义与使用方法示例
本文实例讲述了Python数据结构之哈夫曼树定义与使用方法.分享给大家供大家参考,具体如下: HaffMan.py #coding=utf-8 #考虑权值的haff曼树查找效率并非最高,但可以用于编码等使用场景下 class TreeNode: def __init__(self,data): self.data=data self.left=None self.right=None self.parent=None class HaffTree: def __init__(self): sel
-
Python完成哈夫曼树编码过程及原理详解
哈夫曼树原理 秉着能不写就不写的理念,关于哈夫曼树的原理及其构建,还是贴一篇博客吧. https://www.jb51.net/article/97396.htm 其大概流程 哈夫曼编码代码 # 树节点类构建 class TreeNode(object): def __init__(self, data): self.val = data[0] self.priority = data[1] self.leftChild = None self.rightChild = None self.co
-
Python描述数据结构学习之哈夫曼树篇
前言 本篇章主要介绍哈夫曼树及哈夫曼编码,包括哈夫曼树的一些基本概念.构造.代码实现以及哈夫曼编码,并用Python实现. 1. 基本概念 哈夫曼树(Huffman(Huffman(Huffman Tree)Tree)Tree),又称为最优二叉树,指的是带权路径长度最小的二叉树.树的带权路径常记作: 其中,nnn为树中叶子结点的数目,wkw_kwk为第kkk个叶子结点的权值,lkl_klk为第kkk个叶子结点与根结点的路径长度. 带权路径长度是带权结点和根结点之间的路径长度与该结点的权值的乘
-
C++数据结构与算法之哈夫曼树的实现方法
本文实例讲述了C++数据结构与算法之哈夫曼树的实现方法.分享给大家供大家参考,具体如下: 哈夫曼树又称最优二叉树,是一类带权路径长度最短的树. 对于最优二叉树,权值越大的结点越接近树的根结点,权值越小的结点越远离树的根结点. 前面一篇图文详解JAVA实现哈夫曼树对哈夫曼树的原理与java实现方法做了较为详尽的描述,这里再来看看C++实现方法. 具体代码如下: #include <iostream> using namespace std; #if !defined(_HUFFMANTREE_H
-
使用C语言详解霍夫曼树数据结构
1.基本概念 a.路径和路径长度 若在一棵树中存在着一个结点序列 k1,k2,--,kj, 使得 ki是ki+1 的双亲(1<=i<j),则称此结点序列是从 k1 到 kj 的路径. 从 k1 到 kj 所经过的分支数称为这两点之间的路径长度,它等于路径上的结点数减1. b.结点的权和带权路径长度 在许多应用中,常常将树中的结点赋予一个有着某种意义的实数,我们称此实数为该结点的权,(如下面一个树中的蓝色数字表示结点的权) 结点的带权路径长度规定为从树根结点到该结点之间的路径长度与该结点上权的乘
-
C++数据结构之文件压缩(哈夫曼树)实例详解
C++数据结构之文件压缩(哈夫曼树)实例详解 概要: 项目简介:利用哈夫曼编码的方式对文件进行压缩,并且对压缩文件可以解压 开发环境:windows vs2013 项目概述: 1.压缩 a.读取文件,将每个字符,该字符出现的次数和权值构成哈夫曼树 b.哈夫曼树是利用小堆构成,字符出现次数少的节点指针存在堆顶,出现次数多的在堆底 c.每次取堆顶的两个数,再将两个数相加进堆,直到堆被取完,这时哈夫曼树也建成 d.从哈夫曼树中获取哈夫曼编码,然后再根据整个字符数组来获取出现了得字符的编
-
浅谈Python描述数据结构之KMP篇
前言 本篇章主要介绍串的KMP模式匹配算法及其改进,并用Python实现KMP算法. 1. BF算法 BF算法,即Bruce−ForceBruce-ForceBruce−Force算法,又称暴力匹配算法.其思想就是将主串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和T的第二个字符:若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果. 假设主串S=ABACABABS=ABACABABS=ABACABAB,模式串T=AB
-
Java数据结构之哈夫曼树概述及实现
一.与哈夫曼树相关的概念 概念 含义 1. 路径 从树中一个结点到另一个结点的分支所构成的路线 2. 路径长度 路径上的分支数目 3. 树的路径长度 长度从根到每个结点的路径长度之和 4. 带权路径长度 结点具有权值, 从该结点到根之间的路径长度乘以结点的权值, 就是该结点的带权路径长度 5. 树的带权路径长度 树中所有叶子结点的带权路径长度之和 二.什么是哈夫曼树 定义: 给定n个权值作为n个叶子结点, 构造出的一棵带权路径长度(WPL)最短的二叉树,叫哈夫曼树(), 也被称为最最优二叉树.
-
java数据结构图论霍夫曼树及其编码示例详解
目录 霍夫曼树 一.基本介绍 二.霍夫曼树几个重要概念和举例说明 构成霍夫曼树的步骤 霍夫曼编码 一.基本介绍 二.原理剖析 注意: 霍夫曼编码压缩文件注意事项 霍夫曼树 一.基本介绍 二.霍夫曼树几个重要概念和举例说明 构成霍夫曼树的步骤 举例:以arr = {1 3 6 7 8 13 29} public class HuffmanTree { public static void main(String[] args) { int[] arr = { 13, 7, 8
-
图文详解JAVA实现哈夫曼树
前言 我想学过数据结构的小伙伴一定都认识哈夫曼,这位大神发明了大名鼎鼎的"最优二叉树",为了纪念他呢,我们称之为"哈夫曼树".哈夫曼树可以用于哈夫曼编码,编码的话学问可就大了,比如用于压缩,用于密码学等.今天一起来看看哈夫曼树到底是什么东东. 概念 当然,套路之一,首先我们要了解一些基本概念. 1.路径长度:从树中的一个结点到另一个结点之间的分支构成这两个结点的路径,路径上的分支数目称为路径长度. 2.树的路径长度:从树根到每一个结点的路径长度之和,我们所说的完全