Python rabbitMQ如何实现生产消费者模式
(一)安装一个消息中间件,如:rabbitMQ
(二)生产者
sendmq.py
import pika
import sys
import time
# 远程rabbitmq服务的配置信息
username = 'admin' # 指定远程rabbitmq的用户名密码
pwd = 'admin'
ip_addr = '10.1.7.7'
port_num = 5672
# 消息队列服务的连接和队列的创建
credentials = pika.PlainCredentials(username, pwd)
connection = pika.BlockingConnection(pika.ConnectionParameters(ip_addr, port_num, '/', credentials))
channel = connection.channel()
# 创建一个名为balance的队列,对queue进行durable持久化设为True(持久化第一步)
channel.queue_declare(queue='balance', durable=True)
message_str = 'Hello World!'
for i in range(100000000):
# n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.basic_publish(
exchange='',
routing_key='balance', # 写明将消息发送给队列balance
body=message_str, # 要发送的消息
properties=pika.BasicProperties(delivery_mode=2, ) # 设置消息持久化(持久化第二步),将要发送的消息的属性标记为2,表示该消息要持久化
) # 向消息队列发送一条消息
print(" [%s] Sent 'Hello World!'" % i)
# time.sleep(0.2)
connection.close() # 关闭消息队列服务的连接
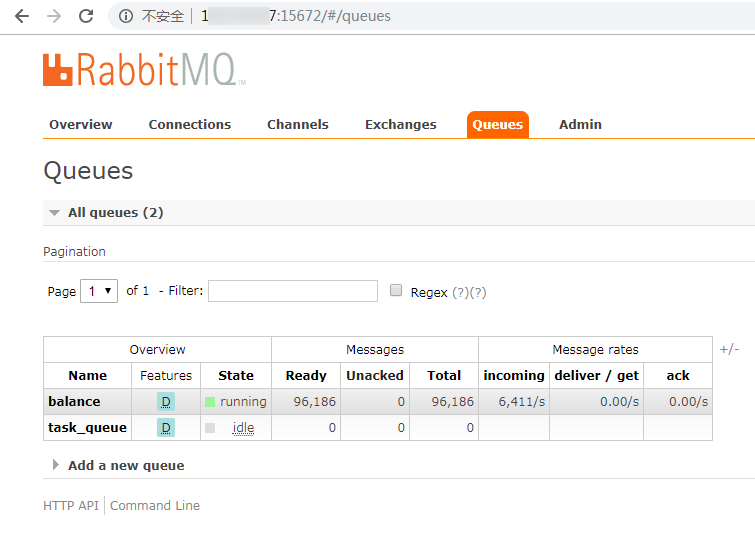
运行sendmq.py文件,可以从以下方法查看队列中的消息数量。
一是,rabbitmq的管理界面,如下图所示:
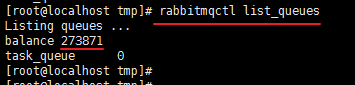
二是,从服务器端命令查看
rabbitmqctl list_queues
(三)消费者
receivemq.py
import pika
import sys
import time
# 远程rabbitmq服务的配置信息
username = 'admin' # 指定远程rabbitmq的用户名密码
pwd = 'admin'
ip_addr = '10.1.7.7'
port_num = 5672
credentials = pika.PlainCredentials(username, pwd)
connection = pika.BlockingConnection(pika.ConnectionParameters(ip_addr, port_num, '/', credentials))
channel = connection.channel()
# 消费成功的回调函数
def callback(ch, method, properties, body):
print(" [%s] Received %r" % (time.time(), body))
# time.sleep(0.2)
# 开始依次消费balance队列中的消息
channel.basic_consume(queue='balance', on_message_callback=callback, auto_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() # 启动消费
运行receivemq.py文件,可以从以下方法查看队列中的消息数量。
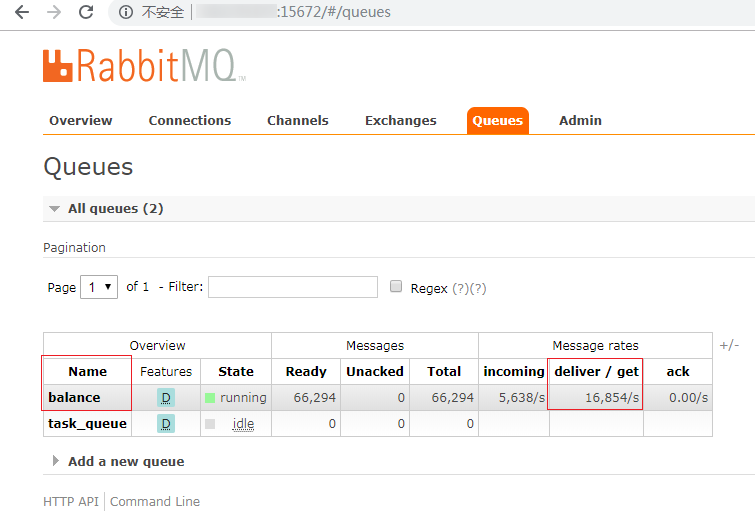
或者
rabbitmqctl list_queues
延伸:
systemctl status rabbitmq-server.service # 状态
systemctl restart rabbitmq-server.service # 重启
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python实现RabbitMQ的消息队列的示例代码
最近在研究redis做消息队列时,顺便看了一下RabbitMQ做消息队列的实现.以下是总结的RabbitMQ中三种exchange模式的实现,分别是fanout, direct和topic. base.py: import pika # 获取认证对象,参数是用户名.密码.远程连接时需要认证 credentials = pika.PlainCredentials("admin", "admin") # BlockingConnection(): 实例化连接对象 # C
-

rabbitmq(中间消息代理)在python中的使用详解
在之前的有关线程,进程的博客中,我们介绍了它们各自在同一个程序中的通信方法.但是不同程序,甚至不同编程语言所写的应用软件之间的通信,以前所介绍的线程.进程队列便不再适用了:此种情况便只能使用socket编程了,然而不同程序之间的通信便不再像线程进程之间的那么简单了,要考虑多种情况(比如其中一方断线另一方如何处理:消息群发,多个程序之间的通信等等),如果每遇到一次程序间的通信,便要根据不同情况编写不同的socket,还要维护.完善这个socket这会使得编程人员的工作量大大增加,也使得程序更易崩溃
-
python队列通信:rabbitMQ的使用(实例讲解)
(一).前言 为什么引入消息队列? 1.程序解耦 2.提升性能 3.降低多业务逻辑复杂度 (二).python操作rabbit mq rabbitmq配置安装基本使用参见上节文章,不再复述. 若想使用python操作rabbitmq,需安装pika模块,直接pip安装: pip install pika 1.最简单的rabbitmq producer端与consumer端对话: producer: #Author :ywq import pika auth=pika.PlainCredentia
-
利用Python学习RabbitMQ消息队列
RabbitMQ可以当做一个消息代理,它的核心原理非常简单:即接收和发送消息,可以把它想象成一个邮局:我们把信件放入邮箱,邮递员就会把信件投递到你的收件人处,RabbitMQ就是一个邮箱.邮局.投递员功能综合体,整个过程就是:邮箱接收信件,邮局转发信件,投递员投递信件到达收件人处. RabbitMQ和邮局的主要区别就是RabbitMQ接收.存储和发送的是二进制数据----消息. rabbitmq基本管理命令: 一步启动Erlang node和Rabbit应用:sudo rabbitmq-serv
-
Python队列RabbitMQ 使用方法实例记录
本文实例讲述了Python队列RabbitMQ 使用方法.分享给大家供大家参考,具体如下: 目前的exchange的路由策略是:每个需要队列的服务独享一个队列(queue),消费者(consumer)采用ACK自动应答模式处理队列消息. 如果需要新增一个队列服务,需要做如下开发步骤: 1.创建队列,发送消息 <?php $routingkey = 'key'; //设置你的连接 $conn_args = array('host' => 'localhost', 'port' => '56
-
Python实现RabbitMQ6种消息模型的示例代码
RabbitMQ与Redis对比 RabbitMQ是一种比较流行的消息中间件,之前我一直使用redis作为消息中间件,但是生产环境比较推荐RabbitMQ来替代Redis,所以我去查询了一些RabbitMQ的资料.相比于Redis,RabbitMQ优点很多,比如: 具有消息消费确认机制 队列,消息,都可以选择是否持久化,粒度更小.更灵活. 可以实现负载均衡 RabbitMQ应用场景 异步处理:比如用户注册时的确认邮件.短信等交由rabbitMQ进行异步处理 应用解耦:比如收发消息双方可以使用
-
Python操作rabbitMQ的示例代码
引入 RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现. rabbitMQ是一款基于AMQP协议的消息中间件,它能够在应用之间提供可靠的消息传输.在易用性,扩展性,高可用性上表现优秀.使用消息中间件利于应用之间的解耦,生产者(客户端)无需知道消费者(服务端)的存在.而且两端可以使用不同的语言编写,大大提供了灵活性. 中文文档 安装 # 安装配置epel源 rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-
-
python RabbitMQ 使用详细介绍(小结)
上节回顾 主要讲了协程.进程.异步IO多路复用. 协程和IO多路复用都是单线程的. epoll 在linux下通过这个模块libevent.so实现 gevent 在底层也是用了libevent.so gevent可以理解为一个更上层的封装. 使用select或者selectors,每接收或发送数据一次都要select一次 twisted异步网络框架,强大又庞大,不支持python3 (代码量python中排top3).几乎把所有的网络服务都重写了一遍. 一.RabbitMQ 消息队列介绍
-
Python RabbitMQ消息队列实现rpc
上个项目中用到了ActiveMQ,只是简单应用,安装完成后直接是用就可以了.由于新项目中一些硬件的限制,需要把消息队列换成RabbitMQ. RabbitMQ中的几种模式和机制比ActiveMQ多多了,根据业务需要,使用RPC实现功能,其中踩过的一些坑,有必要记录一下了. 上代码,目录结构分为 c_server.c_client.c_hanlder: c_server: #!/usr/bin/env python # -*- coding:utf-8 -*- import pika import
-
Python rabbitMQ如何实现生产消费者模式
(一)安装一个消息中间件,如:rabbitMQ (二)生产者 sendmq.py import pika import sys import time # 远程rabbitmq服务的配置信息 username = 'admin' # 指定远程rabbitmq的用户名密码 pwd = 'admin' ip_addr = '10.1.7.7' port_num = 5672 # 消息队列服务的连接和队列的创建 credentials = pika.PlainCredentials(username,
-
生产消费者模式实现方式和线程安全问题代码示例
生产者消费者模式的几种实现方式 拿我们生活中的例子来说,工厂生产出来的产品总是要输出到外面使用的,这就是生产与消费的概念. 在我们实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是类.函数.线程.进程等). 产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者. 第一种:采用wait-notify实现生产者消费者模式 1. 一生产者与一消费者: 2. 一生产者与多消费者: 第二种: 采用阻塞队列实现生产者消费者
-
Java多线程中不同条件下编写生产消费者模型方法介绍
简介: 生产者.消费者模型是多线程编程的常见问题,最简单的一个生产者.一个消费者线程模型大多数人都能够写出来,但是一旦条件发生变化,我们就很容易掉进多线程的bug中.这篇文章主要讲解了生产者和消费者的数量,商品缓存位置数量,商品数量等多个条件的不同组合下,写出正确的生产者消费者模型的方法. 欢迎探讨,如有错误敬请指正 生产消费者模型 生产者消费者模型具体来讲,就是在一个系统中,存在生产者和消费者两种角色,他们通过内存缓冲区进行通信,生产者生产消费者需要的资料,消费者把资料做成产品.生产消费者模式
-
Java多线程Queue、BlockingQueue和使用BlockingQueue实现生产消费者模型方法解析
Queue是什么 队列,是一种数据结构.除了优先级队列和LIFO队列外,队列都是以FIFO(先进先出)的方式对各个元素进行排序的.无论使用哪种排序方式,队列的头都是调用remove()或poll()移除元素的.在FIFO队列中,所有新元素都插入队列的末尾. Queue中的方法 Queue中的方法不难理解,6个,每2对是一个也就是总共3对.看一下JDKAPI就知道了: 注意一点就好,Queue通常不允许插入Null,尽管某些实现(比如LinkedList)是允许的,但是也不建议. Blocking
-
python操作RabbitMq的三种工作模式
一.简介: RabbitMq 是实现了高级消息队列协议(AMQP)的开源消息代理中间件.消息队列是一种应用程序对应用程序的通行方式,应用程序通过写消息,将消息传递于队列,由另一应用程序读取 完成通信.而作为中间件的 RabbitMq 无疑是目前最流行的消息队列之一. RabbitMq 应用场景广泛: 系统的高可用:日常生活当中各种商城秒杀,高流量,高并发的场景.当服务器接收到如此大量请求处理业务时,有宕机的风险.某些业务可能极其复杂,但这部分不是高时效性,不需要立即反馈给用户,我们可以将这部
-
详解Python 模拟实现生产者消费者模式的实例
详解Python 模拟实现生产者消费者模式的实例 散仙使用python3.4模拟实现的一个生产者与消费者的例子,用到的知识有线程,队列,循环等,源码如下: Python代码 import queue import time import threading import random q=queue.Queue(5) #生产者 def pr(): name=threading.current_thread().getName() print(name+"线程启动......") for
-
python 的生产者和消费者模式
目录 python 的生产者和消费者模式 一.生产者消费者模式概述 二.为什么使用生产者消费者模式 三.什么是生产者消费者模式 四.代码案例 1.定义一个生产者 2.定义一个消费者 3.定义一个队列 python 的生产者和消费者模式 一.生产者消费者模式概述 在并发编程中使用生产者和消费者模式能够解决大不多的并发问题.该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度. 二.为什么使用生产者消费者模式 在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程.在多
-
Python教程之生产者消费者模式解析
为什么使用生产者消费者模式 在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程.在多线程开发中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完才能继续生产数据.同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者.为了解决这个问题引入了生产者和消费者模式. 什么是生产者消费者模式 生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题.生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用通
-
Python Asyncio模块实现的生产消费者模型的方法
asyncio的关键字说明 event_loop事件循环:程序开启一个无限循环,把一些函数注册到事件循环上,当满足事件发生的时候,调用相应的协程函数 coroutine协程:协程对象,指一个使用async关键字定义的函数,它的调用不会立即执行函数,而是会返回一个协程对象,协程对象需要注册到事件循环,由事件循环调用. task任务:一个协程对象就是一个原生可以挂起的函数,任务则是对协程进一步封装,其中包含了任务的各种状态 future:代表将来执行或没有执行的任务结果.它和task上没有本质上的区
-
Python爬虫程序中使用生产者与消费者模式时进程过早退出的问题
之前写爬虫程序的时候,采用生产者和消费者的模式,利用Queue作为生产者进程和消费者进程之间的同步队列. 执行程序时,总是秒退,加了断点也无法中断,加打印也无法输出,我知道肯定是进程退出了,但还是百思不得解,为什么会这么快就退出. 一开始以为是我的进程代码写的有问题,在某个地方崩溃导致程序提前退出,排查了一遍又一遍,并没有发现什么明显的问题,后来走读代码,看到主模块中消费者和生产者进程的启动后,发现了问题,原因是我通过start()方法启动进程后,使用join()的方式有问题.消费者进程必须执行