Mysql误删数据解决方案及kill语句原理
mysql误删数据
- 使用delete语句误删数据行
- 使用drop table或者truncate table误删数据表
- 使用drop database语句误删数据库
- 使用rm误删mysql整个实例
对于误删行
- 使用flashback工具闪回,把数据恢复回来。原理是修改binlog的内容,拿回原库重放,需要确保binlog_format=row和binlog_row_imsge=Full
- 具体恢复时
- 如果是insert,将binlog event类型是write_rows event改为delete_rows event。
- 如果是delete则相反。
- 如果是update,binlog里有数据修改前和修改后的值,对调这两行即可。
- 多个事物也是按照以上原则倒叙执行。
- 预防:把sql_safe_updates参数设置为on。这样一来,如果我们忘记在delete或者update语句中写where条件,或者where条件里面没有包含索引字段的话,这条语句的执行就会报错。
对于误删库/表
需要使用全量备份,加增量日志的方式。要求线上有定期的全量备份吗,并且实时备份binlog。
假如有人中午12点误删了一个库,恢复数据的流程如下:
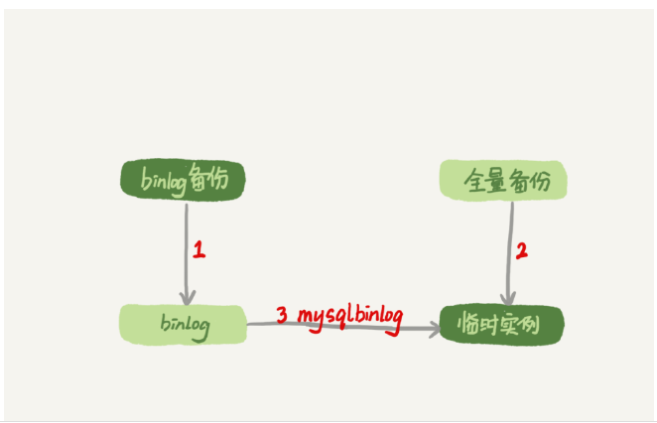
取最近一次全量备份,假设这个库是一天一备,上次备份是当天0点;
用备份恢复出一个临时库;
从日志备份里面,取出凌晨0点之后的日志
把这些日志,除了误删除数据的语句外,全部应用到临时库。
注意:
为了加速数据恢复,如果这个临时库上有多个数据库,你可以在使用mysqlbinlog命令时,加上一个–database参数,用来指定误删表所在的库。这样,就避免了在恢复数据时还要应用其他库日志的情况。
在应用日志的时候,需要跳过12点误操作的那个语句的binlog:
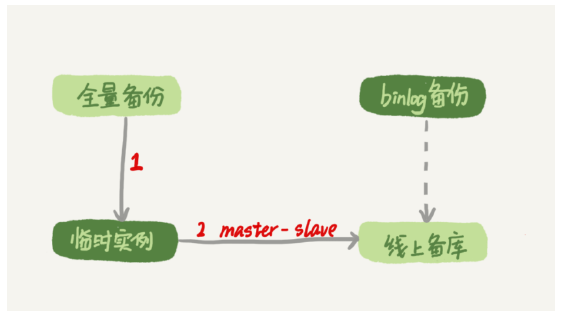
加速恢复的方法:备份恢复出临时实例之后,将这个临时实例设置成线上备库的从库,
一个系统不可能备份无限的日志,你还需要根据成本和磁盘空间资源,设定一个日志保留
的天数。如果你的DBA团队告诉你,可以保证把某个实例恢复到半个月内的任意时间点,这就表示备份系统保留的日志时间就至少是半个月。
虽然“发生这种事,大家都不想的”,但是万一出现了误删事件,能够快速恢复数据,将损失
降到最小,也应该不用跑路了。而如果临时再手忙脚乱地手动操作,最后又误操作了,对业务造成了二次伤害,那就说不过去了。
延迟复制备库
- 如果一个库的备份特别大,或者误操作的时间距离上一个全量备份的时间较长,比如一周一备的实例,在备份之后的第6天发生误操作,那就需要恢复6天的日志,这个恢复时间可能是要按天来计算的。
- 延迟复制的备库是一种特殊的备库,通过 CHANGE MASTER TO MASTER_DELAY = N命令,可以指定这个备库持续保持跟主库有N秒的延迟。
- 比如你把N设置为3600,这就代表了如果主库上有数据被误删了,并且在1小时内发现了这个误操作命令,这个命令就还没有在这个延迟复制的备库执行。这时候到这个备库上执行stopslave,再通过之前介绍的方法,跳过误操作命令,就可以恢复出需要的数据。
对于rm删除数据
只要不是恶意地把整个集群删除,而只是删掉了其中某一个节点的数据的话,HA系统就会开始工作,选出一个新的主库,从而保证整个集群的正常工作。这时,你要做的就是在这个节点上把数据恢复回来,再接入整个集群。
当然了,现在不止是DBA有自动化系统,SA(系统管理员)也有自动化系统,所以也许一个批量下线机器的操作,会让你整个MySQL集群的所有节点都全军覆没。应对这种情况,我的建议只能是说尽量把你的备份跨机房,或者最好是跨城市保存。Kill sql语句
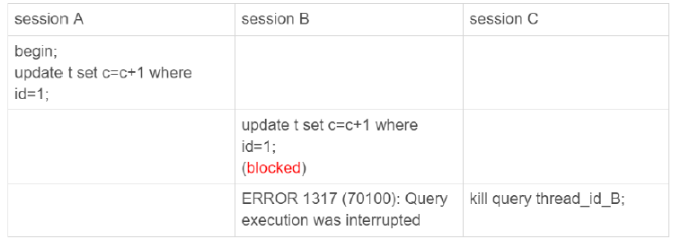
session B是直接终止掉线程,什么都不管就直接退出吗?显然,这是不行的。
当对一个表做增删改查操作时,会在表上加MDL读锁。所以,session B虽然处于blocked状态,但还是拿着一个MDL读锁的。如果线程被kill的时候,就直接终止,那之后这个MDL读锁就没机会被释放了。
kill并不是马上停止的意思,而是告诉执行线程说,这条语句已经不需要继续执行了,可以开始“执行停止的逻辑了”。
实际上,当执行kill query thread_id_b,mysql里处理kill命令的线程做了以下事情:
- 把session B的运行状态改为了THD::KILL_QUERY
- 给session B的执行线程发了一个信号。
因为像图1的我们例子里面,session B处于锁等待状态,如果只是把session B的线程状态设置
THD::KILL_QUERY,线程B并不知道这个状态变化,还是会继续等待。发一个信号的目的,就
是让session B退出等待,来处理这个THD::KILL_QUERY状态。
以上包含了三层意思:
- 一个语句执行过程中有多处埋点,在这些“埋点”的地方判断线程状态,如果发现线程状态
- 是THD::KILL_QUERY,才开始进入语句终止逻辑;
- 如果处于等待状态,必须是一个可以被唤醒的等待,否则根本不会执行到“埋点”处;
- 语句从开始进入终止逻辑,到终止逻辑完全完成,是有一个过程的。
一个kill不掉的例子
执行set global innodb_thread_concurrency=2,将InnoDB的并发线程上限数设置为2;然后,执行下面的序列:

可以看到:
sesssion C执行的时候被堵住了;
但是session D执行的kill query C命令却没什么效果,
直到session E执行了kill connection命令,才断开了session C的连接,提示“Lost connection to MySQL server during query”,
但是这时候,如果在session E中执行show processlist,你就能看到下面这个图:

id=12这个线程的Commnad列显示的是Killed。也就是说,客户端虽然断开了连接,但实际上服务端上这条语句还在执行过程中。
在这个例子里,12号线程的等待逻辑是这样的:每10毫秒判断一下是否可以进入InnoDB执
行,如果不行,就调用nanosleep函数进入sleep状态。
也就是说,虽然12号线程的状态已经被设置成了KILL_QUERY,但是在这个等待进入InnoDB的循环过程中,并没有去判断线程的状态,因此根本不会进入终止逻辑阶段。
而当session E执行kill connection 命令时,是这么做的,
- 把12号线程状态设置为KILL_CONNECTION;
- 关掉12号线程的网络连接。因为有这个操作,所以你会看到,这时候session C收到了断开连接的提示。
那为什么执行show processlist的时候,会看到Command列显示为killed呢?其实,这就是因为在执行show processlist的时候,有一个特别的逻辑:
如果一个线程的状态是KILL_CONNECTION,就把Command列显示成Killed。
所以其实,即使是客户端退出了,这个线程的状态仍然是在等待中。只有等到满足进入InnoDB的条件后,session C的查询语句继续执行,然后才有可能判断到线程状态已经变成了KILL_QUERY或者KILL_CONNECTION,再进入终止逻辑阶段。
kill无效的第一类情况,即:线程没有执行到判断线程状态的逻辑。可能也会由于IO压力过大,读写IO的函数一直无法返回,导致不能及时判断线程的状态。
- 第二类情况,终止逻辑耗时较长
- 超大事物执行期间被kill,回滚操作耗时很长。
- 大会滚操作,比如查询过程中生成了很大的临时文件,删除临时文件需要等待IO资源,导致耗时较长。
- DDL执行到最后阶段,如果被kill,需要删除中间过程的临时文件,也需要IO资源。
ctrl+C,mysql实际上也是启动了一个连接进程发送了kill query命令。
关于客户端连接慢的误解
如果库里面的表很多,连接就会很慢。比如有一个库有上万个表,使用默认参数连接的时候,mysql会提供一个本地库名和表名补全的功能:
- 执行show databases
- 切到db1,执行show tables
- 把这两个命令的结果用于构建一个本地hash表。
第三步是耗时比较长的操作,也就是我们感知到慢不是连接满,也不是服务端慢,而是客户端慢。如果在这个连接中加上 -A,就可以取消自动补全功能,很快返回。
自动补全的效果就是,在输入库名或者表名的时候,将输入前缀,可以使用tab自动补全或者显示提示。实际如果自动补全用的不多,可以每次使用都加-A。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
mysql表物理文件被误删的解决方法
前言 1.该方法只介绍了如何救回这个表名(数据不恢复) 如果想要恢复原来数据 直接用extundelete把文件恢复后放回去即可 2.并且是适用于平时没有全备的情况下 如果有全备 直接那全备的frm和idb文件放回去 就可以了 3.该方法同样适用于数据表迁移(只迁移一个表) 因为discard再import的速度 远比先dump再恢复的速度要快得多 建议: 平时备份一下表结构是非常重要的 -- 如果你直接删除了mysql的表文件 (.frm .idb) 在mysql5.6 可能你就悲剧了
-
mysql 误删除ibdata1之后的恢复方法
mysql 误删除ibdata1之后如何恢复 如果误删除了在线服务器中mysql innodb相关的数据文件ibdata1以及日志文件 ib_logfile*,应该怎样恢复呢? 这时候应该一身冷汗了吧?==================================先抽根烟,冷静一下.==================================再观察一下网站,发现一切都很正常,数据的读取与写入操作都完全正常.这是怎么个情况? 其实,mysqld在运行状态中,会保持这些文件为打开状态,
-
MySQL数据误删除的快速解决方法(MySQL闪回工具)
概述 Binlog2sql是一个Python开发开源的MySQL Binlog解析工具,能够将Binlog解析为原始的SQL,也支持将Binlog解析为回滚的SQL,去除主键的INSERT SQL,是DBA和运维人员数据恢复好帮手. 一.安装配置 1.1 用途 数据快速回滚(闪回) 主从切换后新master丢数据的修复 从binlog生成标准SQL,带来的衍生功能 支持MySQL5.6,5.7 1.2 安装 shell> git clone https://github.com/danfengc
-
mysql误删root用户或者忘记root密码解决方法
解决方法一: 到其他安装了Mysql的服务器(前提是要知道该服务器上Mysql的root用户密码),打开[Mysql的安装目录/var/mysql],将其中的user.frm.user.MYD.user.MYI三个文件拷贝到出问题服务器的[Mysql的安装目录/var/mysql]目录中.然后重启服务器. 解决方法二: 修改你的my.ini或my.cnf文件,在 [mysqld] 节下加入下面一行 skip-grant-tables 然后保存并重启 MySQL 服务. 下面你就可以以任何用户名密
-
关于mysql数据库误删除后的数据恢复操作说明
在日常运维工作中,对于mysql数据库的备份是至关重要的!数据库对于网站的重要性使得我们对mysql数据的管理不容有失! 然后,是人总难免会犯错误,说不定哪天大脑短路了来个误操作把数据库给删除了,怎么办??? 下面,就mysql数据库误删除后的恢复方案进行说明. 一.工作场景 (1)MySQL数据库每晚12:00自动完全备份. (2)某天早上上班,9点的时候,一同事犯晕drop了一个数据库! (3)需要紧急恢复!可利用备份的数据文件以及增量的binlog文件进行数据恢复. 二.数据恢复思路 (1
-
mysql 找回误删表的数据方法(必看)
有备份的话很简单,只需要生成一个最近备份的数据 然后用mysqlbinlog找回备份时间点之后的数据 再恢复到现网即可. 要是没有备份 可能就会比较麻烦,找回数据的成本也是非常之高的. 下面介绍下 mysqlbinlog找回备份时间点之后的数据的办法: 做个简单的实验,将mysql的表数据删除之后,然后用mysqlbinlog 找回刚才删除的表的数据. app表的创建时间和数据的插入: 2013-02-04 10:00:00 原理: mysqlbinlog 前提: mysql开启了bin log
-
mysql误删root用户恢复方法
装完数据库清理一些默认账号的时候不小心把root删除了,flush privileges 之后的新 root 忘了grant任何权限,查看mysqld选项里面有个 −−skip-grant-tables 复制代码 代码如下: #/usr/libexec/mysqld --verbos --help mysql5.5手册说明如下 复制代码 代码如下: --skip-grant-tables This option causes the server to start without using t
-
Mysql误删数据解决方案及kill语句原理
mysql误删数据 使用delete语句误删数据行 使用drop table或者truncate table误删数据表 使用drop database语句误删数据库 使用rm误删mysql整个实例 对于误删行 使用flashback工具闪回,把数据恢复回来.原理是修改binlog的内容,拿回原库重放,需要确保binlog_format=row和binlog_row_imsge=Full 具体恢复时 如果是insert,将binlog event类型是write_rows event改为delet
-
mysql误删数据后快速恢复的办法推荐
目录 第一步:保证mysql已经开启binlog,查看命令: 第二步:进入binlog文件目录,找出日志文件 第三步:切换到mysqlbinlog目录 第四步:通过mysqlbinlog工具命令查看数据库增删改查记录(必须切换到mysqlbinlog目录才有效) 第五步:利用第四步输出的sql语句或者txt文本进行语句过滤,重新插入数据或更新数据 总结 手抖不小心把表里的数据删除或修改错误怎么办?该如何快速恢复呢?遇到这样的问题怎么办?希望下面这篇文章能够帮助到你! 第一步:保证mysql已经开
-
MySQL删除数据Delete与Truncate语句使用比较
空mysqll表内容常见的有两种方法:一种delete,一种是truncate . 不带where参数的delete语句可以删除mysql表中所有内容,使用truncate table也可以清空mysql表中所有内容.效率上truncate比delete快,但truncate删除后不记录mysql日志,不可以恢复数据. 其语法结构为: 复制代码 代码如下: TRUNCATE [TABLE] tbl_name 这里简单的给出个示例, 我想删除 friends 表中所有的记录,可以使用如下语句: 复
-
![MySql插入数据成功但是报[Err] 1055错误的解决方案](/assets/blank.gif)
MySql插入数据成功但是报[Err] 1055错误的解决方案
1.问题: 这两天做insert操作,mysql版本是5.7,insert后虽然成功了,但是会报一个[Err] 1055的错误.具体如下: 2.解决方案: linux环境下,vim到my.cnf,添加如下语句: sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES 最后保存退出,重启mysql 3.测试 看一下是否解决 可以看到已经没有error了. 总结 以上所述是小编给大家介绍的MySql插入数据成功但是报[Err] 1055错误的解决方案,
-
浅谈Mysql大数据分页查询解决方案
目录 1.简介 2.分页插件使用 3.sql测试与分析 3.1 limit现象分析 3.2 解决之道 4 测试时走过的坑 4.1 百万数据内容都一样 4.2 写sql时,把"77"写成了77: 4.3 一个有趣的现象 总结 1.简介 之前,面阿里的时候,有个面试官问我有没有使用过分页查询,我说有,他说分页查询是有问题的,怎么解决:后来这个问题我没有回答出来:本着学习的态度,今天来解决一下这个问题: 2.分页插件使用 1.pom文件 <dependency> <grou
-
分析Mysql大量数据导入遇到的问题以及解决方案
在项目中,经常会碰到往数据库中导入大量数据,以便利用sql进行数据分析.在导入数据的过程中会碰到一些需要解决的问题,这里结合导入一个大约4G的txt数据的实践,把碰到的问题以及解决方法展现出来,一方面自己做个总结记录,另一方面希望对那些碰到相同问题的朋友有个参考. 我导入的数据是百科的txt文件,文件大小有4G多,数据有6500万余条,每条数据通过换行符分隔.每条数据包含三个字段,字段之间通过Tab分隔.将数据取出来的方法我采用的是用一个TripleData类来存放这三个字段,字段都用Strin
-
Python增量循环删除MySQL表数据的方法
需求场景: 有一业务数据库,使用MySQL 5.5版本,每天会写入大量数据,需要不定期将多表中"指定时期前"的数据进行删除,在SQL SERVER中很容易实现,写几个WHILE循环就搞定,虽然MySQL中也存在类似功能,怎奈自己不精通,于是采用Python来实现 话不多少,上脚本: # coding: utf-8 import MySQLdb import time # delete config DELETE_DATETIME = '2016-08-31 23:59:59' DELE
-
查找MySQL中查询慢的SQL语句方法
如何在mysql查找效率慢的SQL语句呢?这可能是困然很多人的一个问题,MySQL通过慢查询日志定位那些执行效率较低的SQL 语句,用--log-slow-queries[=file_name]选项启动时,mysqld 会写一个包含所有执行时间超过long_query_time 秒的SQL语句的日志文件,通过查看这个日志文件定位效率较低的SQL .下面介绍MySQL中如何查询慢的SQL语句 一.MySQL数据库有几个配置选项可以帮助我们及时捕获低效SQL语句 1,slow_query_log 这
-
如何让docker中的mysql启动时自动执行sql语句
在用docker创建mysql容器的时,有时候我们期望容器启动后数据库和表已经自动建好,初始化数据也已自动录入,也就是说容器启动后我们就能直接连上容器中的数据库,使用其中的数据了. 其实mysql的官方镜像是支持这个能力的,在容器启动的时候自动执行指定的sql脚本或者shell脚本,我们一起来看看mysql官方镜像的Dockerfile,如下图: 已经设定了ENTRYPOINT,里面会调用/entrypoint.sh这个脚本,我们把mysql:8这个镜像pull到本地,再用docker run启
-
mysql存储过程之游标(DECLARE)原理与用法详解
本文实例讲述了mysql存储过程之游标(DECLARE)原理与用法.分享给大家供大家参考,具体如下: 我们在处理存储过程中的结果集时,可以使用游标,因为游标允许我们迭代查询返回的一组行,并相应地处理每行.mysql的游标为只读,不可滚动和敏感三种模式,我们来看下: 只读:无法通过光标更新基础表中的数据. 不可滚动:只能按照select语句确定的顺序获取行.不能以相反的顺序获取行. 此外,不能跳过行或跳转到结果集中的特定行. 敏感:有两种游标:敏感游标和不敏感游标.敏感游标指向实际数据,不敏感游标