Java爬虫框架之WebMagic实战
一、介绍
WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。
二、如何学习
1.查看官网
官网地址为:http://webmagic.io/
官网详细文档:http://webmagic.io/docs/zh/
2.跑通hello world示例(具体可以参考官网,也可以参考博客)
我下面写的单元测试案例,可作为Hello World示例。
注意需要导入Maven依赖:
<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>0.7.3</version> </dependency> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>0.7.3</version> </dependency>
3.带着一个目的
说说我的目的,最近我开发的博客系统,其中有个导入第三方博客的插件,这个插件比较简单就是一个搜索框,在对应的搜索框里面填写URL,点击搜索即可导入到自己的博客。
以导入博客园单篇文章为例:
下面是我的源代码(单篇文章导入,我已经将其封装成一个工具类):
import cn.hutool.core.date.DateUtil;
import com.blog.springboot.dto.CnBlogModelDTO;
import com.blog.springboot.entity.Posts;
import com.blog.springboot.service.PostsService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Selectable;
import javax.annotation.PostConstruct;
/**
* 导入博客园文章工具类
*/
@Component
public class WebMagicCnBlogUtils implements PageProcessor {
@Autowired
private PostsService postService;
public static WebMagicCnBlogUtils magicCnBlogUtils;
@PostConstruct
public void init() {
magicCnBlogUtils = this;
magicCnBlogUtils.postService = this.postService;
}
private Site site = Site.me()
.setDomain("https://www.cnblogs.com/")
.setSleepTime(1000)
.setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36");
@Override
public void process(Page page) {
Selectable obj = page.getHtml().xpath("//div[@class='post']");
Selectable title = obj.xpath("//h1[@class='postTitle']//a");
Selectable content = obj.xpath("//div[@class='blogpost-body']");
System.out.println("title:" + title.replace("<[^>]*>", ""));
System.out.println("content:" + content);
CnBlogModelDTO blog = new CnBlogModelDTO();
blog.setTitle(title.toString());
blog.setContent(content.toString());
Posts post = new Posts();
String date = DateUtil.date().toString();
post.setPostAuthor(1L);
post.setPostTitle(title.replace("<[^>]*>", "").toString());
post.setPostContent(content.toString());
post.setPostExcerpt(content.replace("<[^>]*>", "").toString());
post.setPostDate(date);
post.setPostDate(date);
post.setPostModified(date);
boolean importPost = magicCnBlogUtils.postService.insert(post);
if (importPost) {
System.out.println("success");
} else {
System.out.println("fail");
}
}
@Override
public Site getSite() {
return site;
}
/**
* 导入单篇博客园文章数据
*
* @param url
*/
public static void importSinglePost(String url) {
Spider.create(new WebMagicCnBlogUtils())
.addUrl(url)
.addPipeline(new ConsolePipeline())
.run();
}
}
单元测试代码:
import com.blog.springboot.dto.CnBlogModelDTO;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Selectable;
public class WebMagicJunitTest implements PageProcessor {
private Site site = Site.me()
.setDomain("https://www.cnblogs.com/")
.setSleepTime(1000)
.setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36");
@Override
public void process(Page page) {
Selectable obj = page.getHtml().xpath("//div[@class='post']");
Selectable title = obj.xpath("//h1[@class='postTitle']//a");
Selectable content = obj.xpath("//div[@class='blogpost-body']");
System.out.println("title:" + title.replace("<[^>]*>", ""));
System.out.println("content:" + content);
}
@Override
public Site getSite() {
return site;
}
public static void importSinglePost(String url) {
Spider.create(new WebMagicJunitTest())
.addUrl(url)
.addPipeline(new ConsolePipeline())
.run();
}
public static void main(String[] args) {
WebMagicJunitTest.importSinglePost("https://www.cnblogs.com/youcong/p/9404007.html");
}
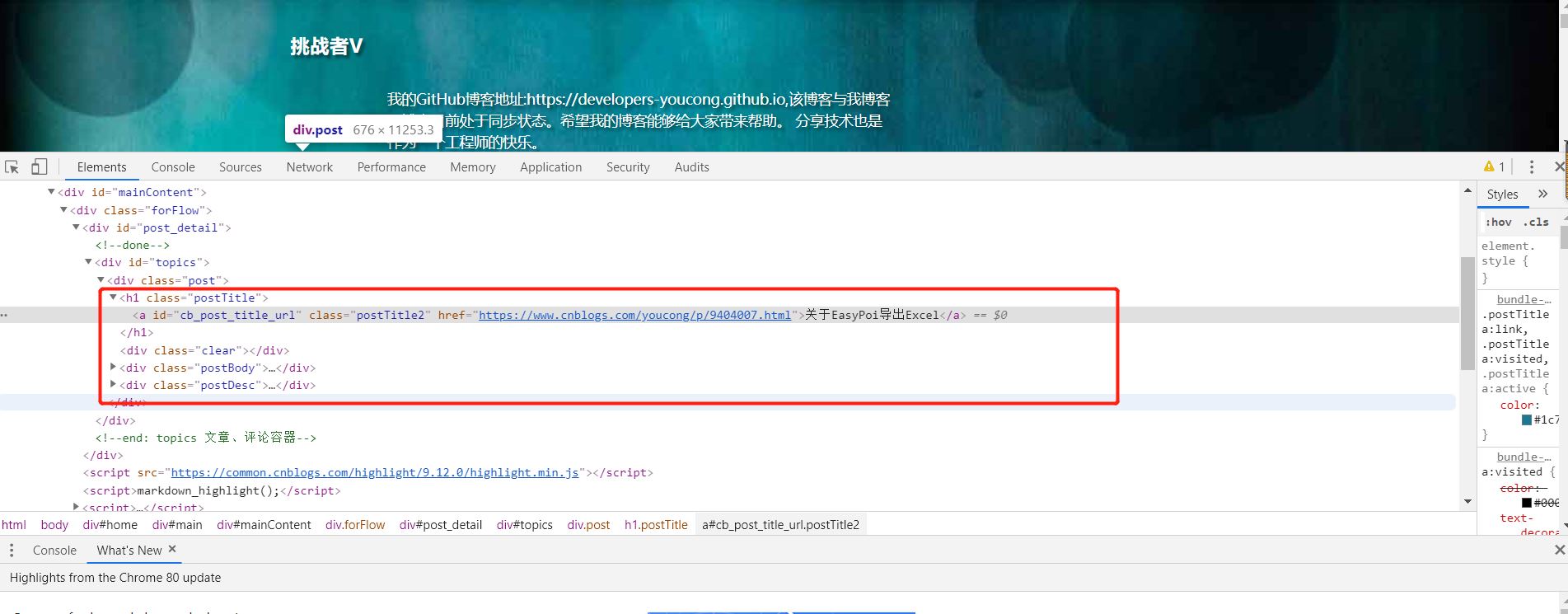
另外我是怎么知道要爬取哪些数据呢?
需求第一,然后通过Chrome或Firefox浏览器检查元素,如图:
到此这篇关于Java爬虫框架之WebMagic实战的文章就介绍到这了,更多相关Java WebMagic内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
springboot+webmagic实现java爬虫jdbc及mysql的方法
前段时间需要爬取网页上的信息,自己对于爬虫没有任何了解,就了解了一下webmagic,写了个简单的爬虫. 一.首先介绍一下webmagic: webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取.页面下载.内容抽取.持久化),支持多线程抓取,分布式抓取,并支持自动重试.自定义UA/cookie等功能. 实现理念: Maven依赖: <dependency> <groupId>us.codecraft</groupId> <artifactId
-

Java爬虫框架之WebMagic实战
一.介绍 WebMagic是一个简单灵活的Java爬虫框架.基于WebMagic,你可以快速开发出一个高效.易维护的爬虫. 二.如何学习 1.查看官网 官网地址为:http://webmagic.io/ 官网详细文档:http://webmagic.io/docs/zh/ 2.跑通hello world示例(具体可以参考官网,也可以参考博客) 我下面写的单元测试案例,可作为Hello World示例. 注意需要导入Maven依赖: <dependency> <groupId>us.
-
分享一个简单的java爬虫框架
反复给网站编写不同的爬虫逻辑太麻烦了,自己实现了一个小框架 可以自定义的部分有: 请求方式(默认为Getuser-agent为谷歌浏览器的设置),可以通过实现RequestSet接口来自定义请求方式 储存方式(默认储存在f盘的html文件夹下),可以通过SaveUtil接口来自定义保存方式 需要保存的资源(默认为整个html页面) 筛选方式(默认所有url都符合要求),通过实现ResourseChooser接口来自定义需要保存的url和资源页面 实现的部分有: html页面的下载方式,通过Htt
-
springboot+WebMagic+MyBatis爬虫框架的使用
目录 1.添加maven依赖 2.项目配置文件 application.properties 3.数据库表结构 4.实体类 5.mapper接口 6.CrawlerMapper.xml文件 7.知乎页面内容处理类ZhihuPageProcessor 8.知乎数据处理类ZhihuPipeline 9.知乎爬虫任务类ZhihuTask 10.Spring boot程序启动类 WebMagic是一个开源的java爬虫框架.WebMagic框架的使用并不是本文的重点,具体如何使用请参考官方文档:http
-
JAVA爬虫实现自动登录淘宝
目的 想通过JAVA代码实现淘宝网的自动登录,通过获取设置的登录信息自动填写并提交.目前这个代码是小编测试过的,可以通过,后期不知道淘宝会不会有相应的封堵策略. 代码分享: package util; import org.openqa.selenium.By; import org.openqa.selenium.WebElement; import org.openqa.selenium.firefox.FirefoxDriver; import org.openqa.selenium.fi
-
基于Vert.x和RxJava 2构建通用的爬虫框架的示例
最近由于业务需要监控一些数据,虽然市面上有很多优秀的爬虫框架,但是我仍然打算从头开始实现一套完整的爬虫框架. 在技术选型上,我没有选择Spring来搭建项目,而是选择了更轻量级的Vert.x.一方面感觉Spring太重了,而Vert.x是一个基于JVM.轻量级.高性能的框架.它基于事件和异步,依托于全异步Java服务器Netty,并扩展了很多其他特性. github地址:https://github.com/fengzhizi715/NetDiscovery 一. 爬虫框架的功能 爬虫框架包含爬
-
Python爬虫框架Scrapy实战之批量抓取招聘信息
网络爬虫抓取特定网站网页的html数据,但是一个网站有上千上万条数据,我们不可能知道网站网页的url地址,所以,要有个技巧去抓取网站的所有html页面.Scrapy是纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便- Scrapy 使用wisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求.整体架构如下图所示: 绿线是数据流向,首先从初始URL 开始,Scheduler 会将其
-
半小时实现Java手撸网络爬虫框架(附完整源码)
最近在做一个搜索相关的项目,需要爬取网络上的一些链接存储到索引库中,虽然有很多开源的强大的爬虫框架,但本着学习的态度,自己写了一个简单的网络爬虫,以便了解其中的原理.今天,就为小伙伴们分享下这个简单的爬虫程序!! 首先介绍每个类的功能: DownloadPage.java的功能是下载此超链接的页面源代码. FunctionUtils.java 的功能是提供不同的静态方法,包括:页面链接正则表达式匹配,获取URL链接的元素,判断是否创建文件,获取页面的Url并将其转换为规范的Url,截取网页网页源
-
Java 实现网络爬虫框架详细代码
目录 Java 实现网络爬虫框架 一.每个类的功能介绍 二.每个类的源代码 Java 实现网络爬虫框架 最近在做一个搜索相关的项目,需要爬取网络上的一些链接存储到索引库中,虽然有很多开源的强大的爬虫框架,但本着学习的态度,自己写了一个简单的网络爬虫,以便了解其中的原理.今天,就为小伙伴们分享下这个简单的爬虫程序!! 一.每个类的功能介绍 DownloadPage.java的功能是下载此超链接的页面源代码. FunctionUtils.java 的功能是提供不同的静态方法,包括:页面链接正则表达式
-
python爬虫框架scrapy实战之爬取京东商城进阶篇
前言 之前的一篇文章已经讲过怎样获取链接,怎样获得参数了,详情请看python爬取京东商城普通篇,本文将详细介绍利用python爬虫框架scrapy如何爬取京东商城,下面话不多说了,来看看详细的介绍吧. 代码详解 1.首先应该构造请求,这里使用scrapy.Request,这个方法默认调用的是start_urls构造请求,如果要改变默认的请求,那么必须重载该方法,这个方法的返回值必须是一个可迭代的对象,一般是用yield返回. 代码如下: def start_requests(self): fo