Python破解BiliBili滑块验证码的思路详解(完美避开人机识别)
准备工作
B站登录页 https://passport.bilibili.com/login
python3
pip install selenium (webdriver框架)
pip install PIL (图片处理)
chrome driver:http://chromedriver.storage.googleapis.com/index.html
firefox driver:https://github.com/mozilla/geckodriver/releases
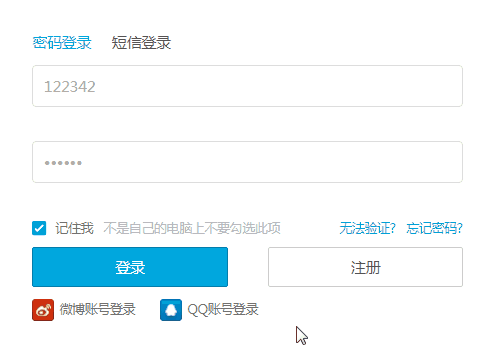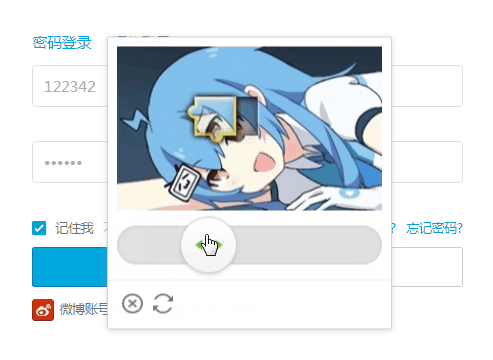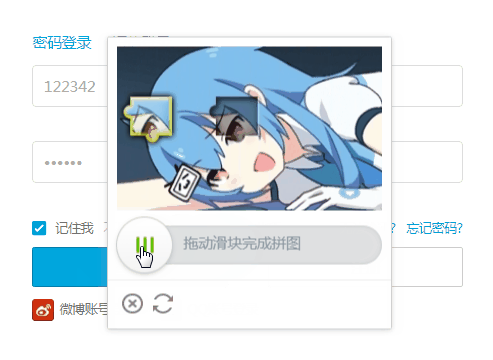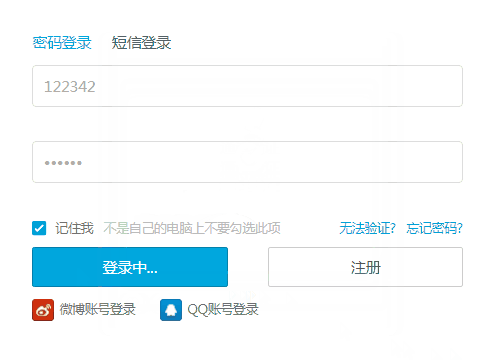
B站的滑块验证码如上。
这类验证码可以使用 selenium 操作浏览器拖拽滑块来进行破解,难点两个,一个如何确定拖拽到的位置,另一个是避开人机识别(反爬虫)。
确定滑块验证码需要拖拽的位移距离
有三种方式
- 人工智能机器学习,确定滑块位置
- 通过完整图片与缺失滑块的图片进行像素对比,确定滑块位置
- 边缘检测算法,确定位置
各有优缺点。人工智能机器学习,确定滑块位置,需要进行训练,比较麻烦,也可以看是否存在在线api可以调用。以下介绍其他两种方式。
对比完整图片与缺失滑块的图片
| 仅介绍,本文不进行实现。对于B站来说,是准确率最高的方式(100%),但不能保证未来B站的滑块验证升级,导致不可用。
B站的滑块验证模块,一共有三张图片:
完整图、缺失滑块图、滑块图,都是由画布绘制出的。类似于:
完整图:

缺失滑块图:

滑块图:

HTML代码类似于:
<div class="geetest_canvas_img geetest_absolute" style="display: block;"> <div class="geetest_slicebg geetest_absolute"> <canvas class="geetest_canvas_bg geetest_absolute" height="160" width="260"></canvas> <canvas class="geetest_canvas_slice geetest_absolute" width="260" height="160"></canvas> </div> <canvas class="geetest_canvas_fullbg geetest_fade geetest_absolute" height="160" width="260" style="display: none;"></canvas> </div>
只需要通过selenium获取画布元素,执行js拿到画布像素,遍历完整图和缺失滑块图的像素,一旦获取到差异(需要允许少许像素误差),像素矩阵x轴方向即是滑块位置。
另外由于滑块图距离画布坐标原点有距离,还需要减去这部分距离。
最后使用 selenium 拖拽即可。
边缘检测算法,确定位置
| 滑块基本上是个方形,通过算法确定方形起始位置即可。

介绍两种方式
- 滑块是方形的,存在垂直的边,该边在缺失滑块图中基本都是灰黑的。遍历像素找到基本都是灰黑的边即可。
- 缺失滑块图中滑块位置是灰黑封闭的。通过算法可以找到封闭区域,大小与滑块相近,即是滑块需要拖拽到的位置。
第二种实现起来有些复杂,不进行实现了。
下面是第一种实现方式,会存在检测不出或错误的情况,使用时需要换一张验证码。也可能存在检测出的边是另一条(因为B站的滑块不是长方形,存在弧形边),那么需要减去滑块宽度
class VeriImageUtil():
def __init__(self):
self.defaultConfig = {
"grayOffset": 20,
"opaque": 1,
"minVerticalLineCount": 30
}
self.config = copy.deepcopy(self.defaultConfig)
def updateConfig(self, config):
# temp = copy.deepcopy(config)
for k in self.config:
if k in config.keys():
self.config[k] = config[k]
def getMaxOffset(self, *args):
# 计算偏移平均值最大的数
av = sum(args) / len(args)
maxOffset = 0
for a in args:
offset = abs(av - a)
if offset > maxOffset:
maxOffset = offset
return maxOffset
def isGrayPx(self, r, g, b):
# 是否是灰度像素点,允许波动offset
return self.getMaxOffset(r, g, b) < self.config["grayOffset"]
def isDarkStyle(self, r, g, b):
# 灰暗风格
return r < 128 and g < 128 and b < 128
def isOpaque(self, px):
# 不透明
return px[3] >= 255 * self.config["opaque"]
def getVerticalLineOffsetX(self, bgImage):
# bgImage = Image.open("./image/bg.png")
# bgImage.im.mode = 'RGBA'
bgBytes = bgImage.load()
x = 0
while x < bgImage.size[0]:
y = 0
# 点》》线,灰度线条数量
verticalLineCount = 0
if x == 258:
print(y)
while y < bgImage.size[1]:
px = bgBytes[x, y]
r = px[0]
g = px[1]
b = px[2]
# alph = px[3]
# print(px)
if self.isDarkStyle(r, g, b) and self.isGrayPx(r, g, b) and self.isOpaque(px):
verticalLineCount += 1
else:
verticalLineCount = 0
y += 1
continue
if verticalLineCount >= self.config["minVerticalLineCount"]:
# 连续多个像素都是灰度像素,直线
# print(x, y)
return x
y += 1
x += 1
pass
if __name__ == '__main__':
bgImage = Image.open("./image/bg.png")
veriImageUtil = VeriImageUtil()
# veriImageUtil.updateConfig({
# "grayOffset": 20,
# "opaque": 0.6,
# "minVerticalLineCount": 10
# })
bgOffsetX = veriImageUtil.getVerticalLineOffsetX(bgImage)
print("bgOffsetX:{} ".format(bgOffsetX))
总结
以上所述是小编给大家介绍的Python破解BiliBili滑块验证码的思路详解(完美避开人机识别),希望对大家有所帮助!
相关推荐
-

Python爬虫爬取Bilibili弹幕过程解析
先来思考一个问题,B站一个视频的弹幕最多会有多少? 比较多的会有2000条吧,这么多数据,B站肯定是不会直接把弹幕和这个视频绑在一起的. 也就是说,有一个视频地址为https://www.bilibili.com/video/av67946325,你如果直接去requests.get这个地址,里面是不会有弹幕的,回想第一篇说到的携程异步加载数据的方式,B站的弹幕也一定是先加载当前视频的界面,然后再异步填充弹幕的. 接下来我们就可以打开火狐浏览器(平常可以火狐谷歌控制台都使用,因为谷歌里面因为插件
-
Python模拟登录之滑块验证码的破解(实例代码)
模拟登录之滑块验证码的破解,具体代码如下所示: # 图像处理标准库 from PIL import Image # web测试 from selenium import webdriver # 鼠标操作 from selenium.webdriver.common.action_chains import ActionChains # 等待时间 产生随机数 import time, random # 滑块移动轨迹 def get_tracks1(distance): # 初速度 v = 0 #
-
Python爬虫 bilibili视频弹幕提取过程详解
两个重要点 1.获取弹幕的url是以 .xml 结尾 2.弹幕url的所需参数在视频url响应的 javascript 中 先看代码 import requests from lxml import etree import re # 使用手机UA headers = { "User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like
-
python滑块验证码的破解实现
破解滑块验证码的思路主要有2种: 获得一张完整的背景图和一张有缺口的图片,两张图片进行像素上的一一对比,找出不一样的坐标. 获得一张有缺口的图片和需要验证的小图,两张图片进行二极化以及归一化,确定小图在图片中间的坐标. 之后就要使用初中物理知识了,使用直线加速度模仿人手动操作 本次就使用第2种,第一种比较简单.废话不多说,直接上代码: 以下均利用无头浏览器进行获取 获得滑块验证的小图片 def get_image1(self,driver): """ 获取滑块验证缺口小图片
-
python3 破解 geetest(极验)的滑块验证码功能
下面一段代码给大家介绍python破解geetest 验证码功能,具体代码如下所示: from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.action_chains import ActionChains import PIL.Image as image import time,re, random import
-
Python破解BiliBili滑块验证码的思路详解(完美避开人机识别)
准备工作 B站登录页 https://passport.bilibili.com/login python3 pip install selenium (webdriver框架) pip install PIL (图片处理) chrome driver:http://chromedriver.storage.googleapis.com/index.html firefox driver:https://github.com/mozilla/geckodriver/releases B站的滑块验
-
python破解bilibili滑动验证码登录功能
地址:https://passport.bilibili.com/login 左图事完整验证码图,右图是有缺口的验证码图 步骤: 1.准备bilibili账号 2.工具:pycharm selenium chromedriver PIL 3.破解思路: 找到完整验证码和有缺口的验证码图片,然后计算缺口坐标,再利用selenium移动按钮到指定位置,齐活 步骤代码如下: 先导入需要的包和库 from selenium impor
-
Python破解excel进入密码的过程详解
目录 一.excel进入密码 二.密码解除思路 三.python 1.conf.ini 2.crack.py 一.excel进入密码 加密算法cipher Algorithm=“AES” AES加密算法的详细介绍与实现 二.密码解除思路 通过排列组合的方式进行查找 注意:此方法比较考验对密码字典的选取,且耗费时间较长,仅供参考学习!! 文件夹如图所示: 将待破解的文件放到excel文件夹中. 三.python 1.conf.ini 将准备好的密码字典添加到conf.ini中password后面,
-
基于Numpy.convolve使用Python实现滑动平均滤波的思路详解
1.滑动平均概念 滑动平均滤波法(又称递推平均滤波法),时把连续取N个采样值看成一个队列 ,队列的长度固定为N ,每次采样到一个新数据放入队尾,并扔掉原来队首的一次数据.(先进先出原则) 把队列中的N个数据进行算术平均运算,就可获得新的滤波结果.N值的选取:流量,N=12:压力:N=4:液面,N=4~12:温度,N=1~4 优点: 对周期性干扰有良好的抑制作用,平滑度高 适用于高频振荡的系统 缺点: 灵敏度低 对偶然出现的脉冲性干扰的抑制作用较差 不易消除由于脉冲干扰所引起的采样
-
python通过http上传文件思路详解
这里主要是解决multipart/form-data这种格式的文件上传,基本现在http协议上传文件基本上都是通过这种格式上传 1 思路 一般情况下,如果我们往一个地址上传文件,则必须要登陆,登陆成功后,拿到cookies,然后在上传文件的请求携带这个cookies. 然后我们就需要通过浏览器在网站上传文件,这个时候我们需要打开浏览器的开发者工具或者fiddler,然后按照抓到包组装我们的上传文件的post请求 大家把握一个原则就是:在post请求中,用files参数来接受文件对象相关的参数,通
-
基于Pytorch版yolov5的滑块验证码破解思路详解
前言 本文将使用pytorch框架的目标识别技术实现滑块验证码的破解.我们这里选择了yolov5算法 例:输入图像 输出图像 可以看到经过检测之后,我们能很准确的定位到缺口的位置,并且能得到缺口的坐标,这样一来我们就能很轻松的实现滑动验证码的破解. 一.前期工作 yolov系列是常用的目标检测算法,yolov5不仅配置简单,而且在速度上也有不小的提升,我们很容易就能训练我们自己的数据集. YOLOV5 Pytorch版本GIthub网址感谢这位作者的代码. 下载之后,是这样的格式 ---data
-
使用 Python 破解压缩文件的密码的思路详解
经常遇到百度网盘的压缩文件加密了,今天我们就破解它! 实现思路 上篇文章给大家介绍了爆破密码的思路,感兴趣的朋友可以了解下. 其实都大同小异:无非就是字典爆破,就看你是有现成密码字典,还是自己生成密码字典,然后进行循环输入密码,直到输入正确位置.现在很多都有防爆破限制,根本无法进行暴力破解,但是似乎zip这种大家都是用比较简单的密码而且没有什么限制. 因此 实现思路就是 生成字典->输入密码->成功解压 实现过程 1. 生成字典 生成密码字典其实就是一个字符组合的过程.小伙伴们可别用列表去组
-
Python爬虫爬验证码实现功能详解
主要实现功能: - 登陆网页 - 动态等待网页加载 - 验证码下载 很早就有一个想法,就是自动按照脚本执行一个功能,节省大量的人力--个人比较懒.花了几天写了写,本着想完成验证码的识别,从根本上解决问题,只是难度太高,识别的准确率又太低,计划再次告一段落. 希望这次经历可以与大家进行分享和交流. Python打开浏览器 相比与自带的urllib2模块,操作比较麻烦,针对于一部分网页还需要对cookie进行保存,很不方便.于是,我这里使用的是Python2.7下的selenium模块进行网页上的操
-
使用 Python 在京东上抢口罩的思路详解
全国抗"疫"这么久终于见到曙光,在家待了将近一个月,现在终于可以去上班了,可是却发现出门必备的口罩却一直买不到.最近看到京东上每天都会有口罩的秒杀活动,试了几次却怎么也抢不到,到了抢购的时间,浏览器的页面根本就刷新不出来,等刷出来秒杀也结束了.现在每天只放出一万个,却有几百万人在抢,很想知道别人是怎么抢到的,于是就在网上找了大神公开出来的抢购代码.看了下代码并不复杂,现在我们就报着学习的态度一起看看. 使用模块 首先打开项目中 requirements.txt 文件,看下它都需要哪些模