Python创建空列表的字典2种方法详解
如果要在 Python 中创建键值是空列表的字典,有多种方法,但是各种方法之间是否由区别?需要作实验验证,并且分析产生的原因。本文针对两种方法做了实验和分析。
如果要在 Python 中创建一个键值都是列表的字典,类似下面这样,该怎么做?
{1:[], 2:[], 3:[], 4:[]}
方法1,字典构造器
用 dict 构造器生成,构造(key,value)对
> key = [1, 2, 3, 4]
> a = dict([(k,[]) for k in key])
> a
{1: [], 2: [], 3: [], 4: []}
方法2,使用 fromkeys()
用字典的方法fromkeys(key list, default value)
> key = [1, 2, 3, 4]
> b = {}.fromkeys(key,[])
> b
{1: [], 2: [], 3: [], 4: []}
结果对比
这两种方法生成的字典有没有区别?检验一下:
> a[1].append(1)
> a
{1: [1], 2: [], 3: [], 4: []} # 仅影响对应的键值列表
>
> b[1].append(1)
> b
{1: [1], 2: [1], 3: [1], 4: [1]} # 所有键值列表都受影响
上面的结果中,发现使用 fromkeys() 方法生成的空列表,都增加了一个元素。似乎他们是同一个对象。
原因分析
从上面看出,用fromkeys( )方法生成的字典里的空列表其实是同一个对象。为什么会这样?因为传给fromkeys( )函数的参数”[]“是同一个对象,fromkeys( )把这一个对象的浅拷贝放在字典里了。
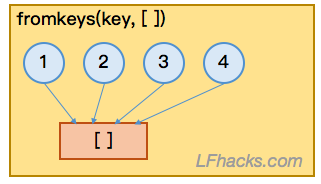
如果这个对象是 mutable 的,就会在后续的操作中出问题。如果创建字典的对象是mutable的,应该避免使用fromkeys( )
更多关于Python创建空列表的字典方法请查看下面的相关链接
相关推荐
-

python DataFrame转dict字典过程详解
这篇文章主要介绍了python DataFrame转dict字典过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 背景:将商品id以及商品类别作为字典的键值映射,生成字典,原为DataFrame # 创建一个DataFrame # 列值类型均为int型 import pandas as pd item = pd.DataFrame({'item_id': [100120, 10024504, 1055460], 'item_categor
-
Python创建字典的八种方式
1.创建空字典 >>> dic = {} >>> type(dic) <type 'dict'> 2.直接赋值创建 >>> dic = {'spam':1, 'egg':2, 'bar':3} >>> dic {'bar': 3, 'egg': 2, 'spam': 1} 3.通过关键字dict和关键字参数创建 >>> dic = dict(spam = 1, egg = 2, bar =3) >&
-
python实现在无须过多援引的情况下创建字典的方法
本文实例讲述了python实现在无须过多援引的情况下创建字典的方法.分享给大家供大家参考.具体实现方法如下: 1.使用itertools模块 import itertools the_key = ['ab','22',33] the_vale = ['aaaa',"dddddddd",'22222222222'] d = dict(itertools.izip(the_key,the_vale)) print d 2.加参数 dict = dict(red = 1,bule = 2,y
-
python 列表、字典和集合的添加和删除操作
在python中,元组不可变,只能查询不能修改,列表.字典和集合的基本操作,各不相同,下面就来比较一下它们的添加和删除操作吧. 添加 一.列表 1."+"号 #两个数组相加,生成一个大数组 a = [1, 2, 3] b = [4, 5, 6] c = a + b print(c) #输出结果:[1, 2, 3, 4, 5, 6] 2.extend方法 #只接受列表参数并将参数的每个元素都添加到原有的列表中 a = [1, 2, 3] b = [4, 5, 6] a.extend(b)
-
Python中创建字典的几种方法总结(推荐)
1.传统的文字表达式: >>> d={'name':'Allen','age':21,'gender':'male'} >>> d {'age': 21, 'name': 'Allen', 'gender': 'male'} 如果你可以事先拼出整个字典,这种方式是很方便的. 2.动态分配键值: >>> d={} >>> d['name']='Allen' >>> d['age']=21 >>> d[
-
python判断变量是否为int、字符串、列表、元组、字典的方法详解
在实际写程序中,经常要对变量类型进行判断,除了用type(变量)这种方法外,还可以用isinstance方法判断: a = 1 b = [1,2,3,4] c = (1,2,3,4) d = {'a':1, 'b':2, 'c':3} e = "abc" if isinstance(a,int): print ("a is int") else: print ("a is not int") if isinstance(b,list): prin
-
Python创建空列表的字典2种方法详解
如果要在 Python 中创建键值是空列表的字典,有多种方法,但是各种方法之间是否由区别?需要作实验验证,并且分析产生的原因.本文针对两种方法做了实验和分析. 如果要在 Python 中创建一个键值都是列表的字典,类似下面这样,该怎么做? {1:[], 2:[], 3:[], 4:[]} 方法1,字典构造器 用 dict 构造器生成,构造(key,value)对 > key = [1, 2, 3, 4] > a = dict([(k,[]) for k in key]) > a {1:
-
python解析命令行参数的三种方法详解
这篇文章主要介绍了python解析命令行参数的三种方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 python解析命令行参数主要有三种方法:sys.argv.argparse解析.getopt解析 方法一:sys.argv -- 命令行执行:python test_命令行传参.py 1,2,3 1000 # test_命令行传参.py import sys def para_input(): print(len(sys.argv)) #
-
Python中提取人脸特征的三种方法详解
目录 1.直接使用dlib 2.使用深度学习方法查找人脸,dlib提取特征 3.使用insightface提取人脸特征 安装InsightFace 提取特征 1.直接使用dlib 安装dlib方法: Win10安装dlib GPU过程详解 思路: 1.使用dlib.get_frontal_face_detector()方法检测人脸的位置. 2.使用 dlib.shape_predictor()方法得到人脸的关键点. 3.使用dlib.face_recognition_model_v1()方法提取
-
Python比较两个日期的两种方法详解
目录 datetime strptime 之前我们曾经分享过:Python获取某一日期是“星期几”的6种方法!实际上,在我们使用Python处理日期/时间的时候,经常会遇到各种各样的问题.今天我们就来探讨另一个问题,如何用Python比较两个日期? datetime 如果需要用Python处理日期和时间,大家肯定会先想到datetime.time.calendar等模块.在这其中,datetime模块主要是用来表示日期时间的,就是我们常说的年月日/时分秒. datetime模块中常用的类: 类名
-
Python识别二维码的两种方法详解
目录 前言 pyzbar + PIL cv2 前言 最近在搜寻资料时,发现了一则10年前的新闻:二维码将成线上线下关键入口.从今天的移动互联网来看,支付收款码/健康码等等与我们息息相关,二维码确实成为了我们生活中不可或缺的一部分. 在学习Python处理二维码的过程中,我们看到的大多是“用python生成酷炫二维码”.“用Python制作动图二维码”之类的文章.而关于使用Python批量识别二维码的教程,并不多见.所以今天我会给大家分享两种批量识别二维码的Python技巧! pyzbar + P
-
利用Python代码实现数据可视化的5种方法详解
前言 数据科学家并不逊色于艺术家.他们用数据可视化的方式绘画,试图展现数据内隐藏的模式或表达对数据的见解.更有趣的是,一旦接触到任何可视化的内容.数据时,人类会有更强烈的知觉.认知和交流. 数据可视化是数据科学家工作中的重要组成部分.在项目的早期阶段,你通常会进行探索性数据分析(Exploratory Data Analysis,EDA)以获取对数据的一些理解.创建可视化方法确实有助于使事情变得更加清晰易懂,特别是对于大型.高维数据集.在项目结束时,以清晰.简洁和引人注目的方式展现最终结果是非常
-
python中对列表的删除和添加方法详解
目录 删除 1.pop(index) 2.remove(item) 3.dellist[index] 4.clear() 添加 1.append(obj) 2.extend(obj) 3.insert(index,obj) 总结 删除 1.pop(index) 删除列表中指定索引处的元素,默认删除列表中最后一个元素,返回删除值. list1 = [1, 2, 3, 5, 8, '3'] print(list1.pop(3)) print(list1) print(list1.pop()) pri
-
python创建关联数组(字典)的方法
本文实例讲述了python创建关联数组(字典)的方法.分享给大家供大家参考.具体分析如下: 关联数组在python中叫字典,非常有用,下面是定义字典的两种方法 # Dictionary with quoted or variable keys d1 = {"name":"donuts","type":"chocolate","quantity":10} # Dictionary with fixed key
-
python中list列表复制的几种方法(赋值、切片、copy(),deepcopy())
目录 1.浅拷贝和深拷贝 2.直接赋值 3.for循环 4.切片 5.copy()方法 (1)list.copy()方法 (2)copy.copy()方法 6.deepcopy()方法 1.浅拷贝和深拷贝 浅拷贝复制指向某个对象的地址(指针),而不复制对象本身,新对象和原对象共享同一内存. 深拷贝会额外创建一个新的对象,新对象跟原对象并不共享内存,修改新对象不会影响到原对象. 赋值其实就是引用了原对象.两者指向同一内存,两个对象是联动的,无论哪个对象发生改变都会影响到另一个. 2.直接赋值 使用
-
对python列表里的字典元素去重方法详解
如下所示: def list_dict_duplicate_removal(): data_list = [{"a": "123", "b": "321"}, {"a": "123", "b": "321"}, {"b": "321", "a": "123"}] run