Python编程快速上手——PDF文件操作案例分析
本文实例讲述了Python PDF文件操作。分享给大家供大家参考,具体如下:
题目如下:
- 利用第九章的os.walk()函数编写脚本,遍历文件夹中的所有pdf,用命令行提供的命令对这些PDF进行加密,用原来的文件名加上_encrypted.pdf后缀,保存每个加密的PDF。在删除原来的文件之前,尝试用程序读取并解密该文件,确保被正确加密
- 然后编写一个程序,找到文件夹中所有加密的PDF文件,利用提供的口令,创建pdf的解密拷贝,如果口令不对,程序应该打印一条消息,
并继续处理下一个pdf文件
思路如下:
- 程序内函数1需要做以下事情:
找出文件夹中所有PDF文件
对PDF文件进行加密
保存加密的PDF文件
检验是否正确加密
删除源文件
- 程序内函数2需要做以下事情:
遍历文件夹中所有带_encrypted后缀的PDF文件
利用提供的口令进行打开
能够正确打开,则进行口令拷贝保存到txt文件
不能正确打开输出到屏幕
- 代码需要做以下事情:
导入os,PyPDF2,sys,send2trash
生成新文件夹用于保存加密PDF及拷贝文本
- 编写一个加密函数
函数内调用os.walk()遍历文件夹,文件名保存到列表
命令行参数sys.argv()提供加密口令
for循环进行文件加密和保存加密文件操作
decrypt进行解密,确保正确加密,并进行反馈
删除原有文件(send2trash) - 编写一个生成解密拷贝函数
os.walk()遍历,decrypt进行解密,反馈结果,生成密码拷贝txt
try-except进行decrypt控制,解密失败打印消息,continue继续
代码如下:
由于我的代码在命令行运行时提示找不到PyPDF2模块,所以sys.argv命令行参数用的字符串直接放入函数进行代替。
#! python3
import os, sys, PyPDF2,send2trash
os.makedirs(".\\NewPDF")
print("文件夹创建成功!")
path1 = os.path.abspath(".\\NewPDF")
# 文件加密函数
def decryptFile(argv,p = os.path.abspath(".\\New")):
tagFloder = '.\\PDF'
pdfList = []
#当前目录下创建新文件夹
#os.makedirs(".\\NewPDF")
#遍历目标文件夹,将.pdf文件名添加到列表
for foldername, subfolders, filenames in os.walk(tagFloder):
for filename in filenames:
if filename.endswith('.pdf'):
pdfList.append(filename)
print('找到PDF文件:%s' %filename)
else:
continue
#对pdf文件进行加密)
for i in pdfList:
pdfFile = open(os.path.join(foldername,filename),'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFile)
pdfWriter = PyPDF2.PdfFileWriter()
#拷贝
for pageNum in range(pdfReader.numPages):
pdfWriter.addPage(pdfReader.getPage(pageNum))
newName = i[0:-4] #对文件名进行分割
pdfWriter.encrypt(argv) #口令加密
pdfResult = open("{0}\\{1}_encrypted.pdf".format(p,newName),"wb+") #创建新文件名对象
pdfWriter.write(pdfResult) #写入新文件
pdfReader2 = PyPDF2.PdfFileReader(pdfResult,'rb')
#进行加密确认
if pdfReader2.decrypt(argv):
print("正确加密!删除原文件中...")
try:
send2trash.send2trash(os.path.join(foldername,i))
except:
print("删除原文件:%s 失败!"%i)
pdfResult.close()
print("Done!")
# 口令拷贝函数
def copyDcrypt(argv,p = os.path.abspath(".\\New")):
pdfList = []
for foldername, subfolders, filenames in os.walk("."):
print("父文件夹:%s"%foldername)
for filename in filenames:
if filename.endswith(".pdf"):
pdfReader = PyPDF2.PdfFileReader(open(os.path.join(foldername,filename),'rb'))
if pdfReader.isEncrypted:
pdfList.append(filename)
print('找到已加密PDF文件:%s' % filename)
else:
continue
for i in pdfList:
newName = i[0:-4] #对文件名进行分割
try:
if pdfReader.decrypt(argv) == 1:
copyFile = open("{0}\\{1}_PASSWORD.txt" .format(p,newName), 'w')
copyFile.write("Password is : %s" % argv)
copyFile.close()
print("口令正确!拷贝生成成功!")
else:
print("口令错误!")
except:
continue
# 调用函数
decryptFile("ABCDEFG",path1)
copyDcrypt("ABCDEFG",path1)
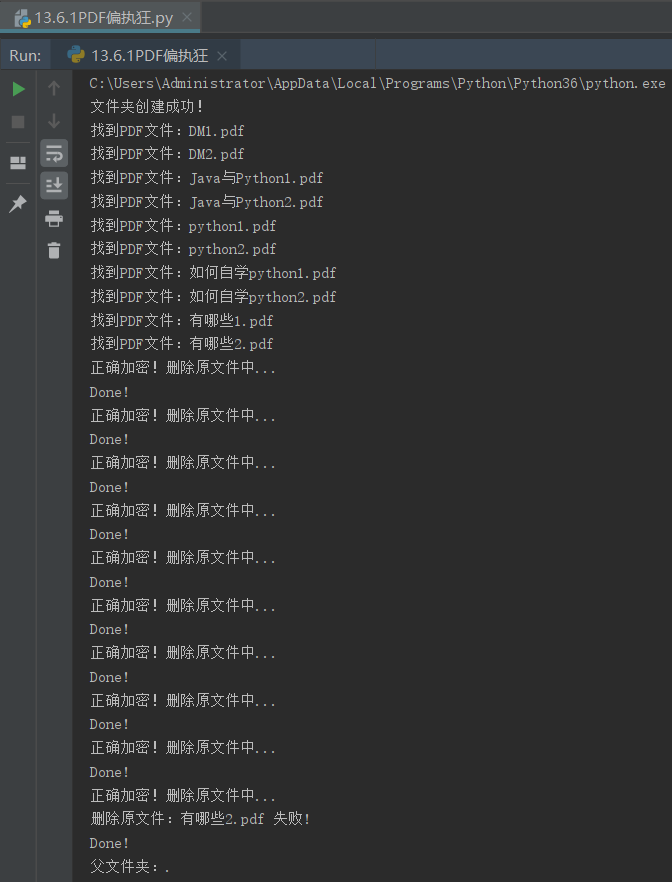
运行结果:
- pycharm界面运行结果:
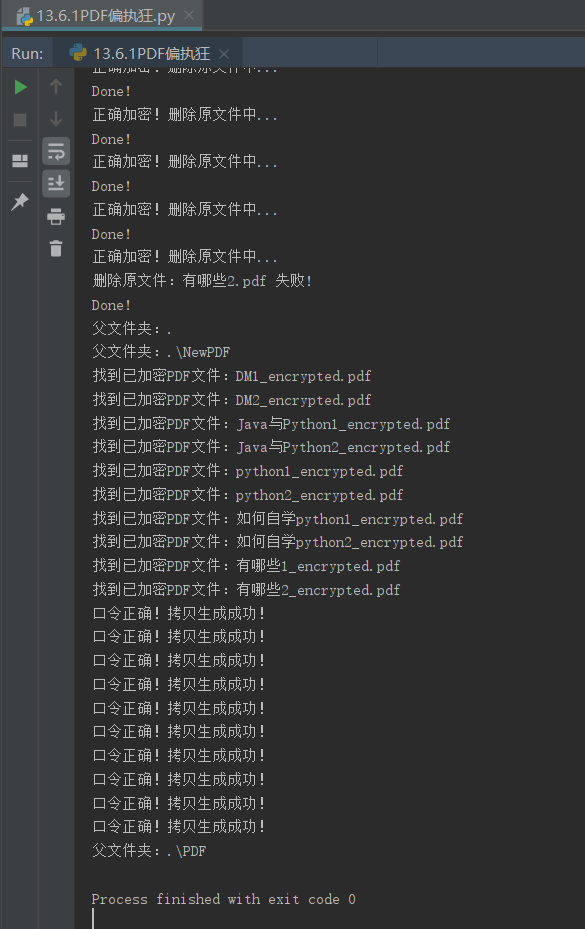
- 原文件夹:
- 新文件夹:

- 拷贝文本文件:

更多Python相关内容感兴趣的读者可查看本站专题:《Python文件与目录操作技巧汇总》、《Python编码操作技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-
Python如何把多个PDF文件合并代码实例
这篇文章主要介绍了Python如何把多个PDF文件合并,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 from PyPDF2 import PdfFileMerger import os files = os.listdir()#列出目录中的所有文件 merger = PdfFileMerger() for file in files: #从所有文件中选出pdf文件合并 if file[-4:] == ".pdf": mer
-
python实现pdf转换成word/txt纯文本文件
本文实例为大家分享了python实现pdf转word/txt,供大家参考,具体内容如下 依赖包:pdfminer3k 可以通过pip安装:也可以到官网下载,解压,进入文件夹,输入命令setup.py install安装软件. 源代码: #!/usr/bin/python # -*- coding: utf-8 -*- import sys import importlib importlib.reload(sys) from pdfminer.pdfparser import PDFParser
-
python3如何将docx转换成pdf文件
本文实例为大家分享了python3将docx转换成pdf文件的具体代码,供大家参考,具体内容如下 直接上代码 # -*- encoding:utf-8 -*- """ author:lgh """ from win32com.client import Dispatch, constants, gencache def doc2pdf(input, output): w = Dispatch('Word.Application') try: #
-

Python解析并读取PDF文件内容的方法
本文实例讲述了Python解析并读取PDF文件内容的方法.分享给大家供大家参考,具体如下: 一.问题描述 利用python,去读取pdf文本内容. 二.效果 三.运行环境 python2.7 四.需要安装的库 pip install pdfminer 五.实现源代码 代码1(win64) # coding=utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time time1=time.time() impor
-
Python 实现加密过的PDF文件转WORD格式
实现方法简介 许多文件都支持转换为PDF格式,诸如Word,Excel,PowerPoint,Cad以及图片格式.所以pdf从学校到职场,都可以看到pdf文件的身影. 为了保证了文件的安全性,正常情况下无法对pdf的内容进行编辑.但是相应的我们就无法修改pdf的内容,也不便于pdf资料的使用.虽然现在市面上有很多 pdf 转 word 软件,比如 wps,但大多数的软件是要收费的,并且价格不菲.前些天就有人叫我帮她把 pdf 文档转成 word 的文档.因为写尽调报告需要去查看各种信评资料,往往
-
Python常见读写文件操作实例总结【文本、json、csv、pdf等】
本文实例讲述了Python常见读写文件操作.分享给大家供大家参考,具体如下: 读写文件 读写文件是最常见的IO操作,python内置了读写文件的函数,用法和c是兼容的. 读写文件前,我们必须了解一下,在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘,所以读写文件就是请求操作系统打开一个文件对象(文件描述),然后,通过操作系统提供的接口从这个文件对象中读取数据(读文件),或者把数据写入这个文件对象(写文件). 1.读文件 要以读文件的模式打开一个文件对象,使用p
-
基于Python实现对PDF文件的OCR识别
最近在做一个项目的时候,需要将PDF文件作为输入,从中输出文本,然后将文本存入数据库中.为此,我找寻了很久的解决方案,最终才确定使用tesseract.所以不要浪费时间了,我们开始吧. 1.安装tesseract 在不同的系统中安装tesseract非常容易.为了简便,我们以Ubuntu为例. 在Ubuntu中你仅仅需要运行以下命令: 这将会安装支持3种不同语言的tesseract. 2.安装PyOCR 现在我们还需要安装tesseract的Python接口.幸运的是,有许多出色的Python接
-
如何使用python进行pdf文件分割
这篇文章主要介绍了如何使用python进行pdf文件分割,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 import os from pyPdf import PdfFileWriter, PdfFileReader def split(pdf_file, delta, output_dir): if not os.path.exists(output_dir): os.makedirs(output_dir) if not os.p
-
Python生成pdf文件的方法
本文实例演示了Python生成pdf文件的方法,是比较实用的功能,主要包含2个文件.具体实现方法如下: pdf.py文件如下: #!/usr/bin/python from reportlab.pdfgen import canvas def hello(): c = canvas.Canvas("helloworld.pdf") c.drawString(100,100,"Hello,World") c.showPage() c.save() hello() di
-
Python2.7读取PDF文件的方法示例
本文实例讲述了Python2.7读取PDF文件的方法.分享给大家供大家参考,具体如下: 这篇文章示例代码采用的Python版本是2.7,需要下载的插件是PDFMiner,下载地址是http://www.unixuser.org/~euske/python/pdfminer/,地址里有安装方法,我就不再细说了,需要说明的是Python2只能使用PDFMiner,Python3不能使用,Python3可以使用PDFMiner3K,下载地址为https://pypi.python.org/pypi/p
-
Python3将jpg转为pdf文件的方法示例
本文实例讲述了Python3将jpg转为pdf文件的方法.分享给大家供大家参考,具体如下: #coding=utf-8 #!/usr/bin/env python """ convert image to pdf file """ #Author: mrbeann import os import sys import glob import platform from reportlab.lib.pagesizes import letter,
-
Python实现简单拆分PDF文件的方法
本文实例讲述了Python实现简单拆分PDF文件的方法.分享给大家供大家参考.具体如下: 依赖pyPdf处理PDF文件 切分pdf文件 使用方法: 1)将要切分的文件放在input_dir目录下 2)在configure.txt文件中设置要切分的份数(如要切分4份,则设置part_num=4) 3)执行程序 4)切分后的文件保存在output_dir目录下 5)运行日志写在pp_log.txt中 P.S. 本程序可以批量切割多个pdf文件 from pyPdf import PdfFileWri