浅谈MySQL使用笛卡尔积原理进行多表查询
MySQL的多表查询(笛卡尔积原理)
- 先确定数据要用到哪些表。
- 将多个表先通过笛卡尔积变成一个表。
- 然后去除不符合逻辑的数据(根据两个表的关系去掉)。
- 最后当做是一个虚拟表一样来加上条件即可。
注意:列名最好使用表别名来区别。
笛卡尔积
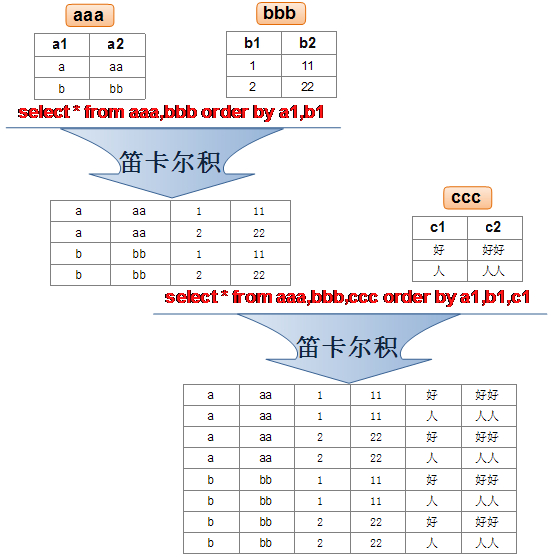
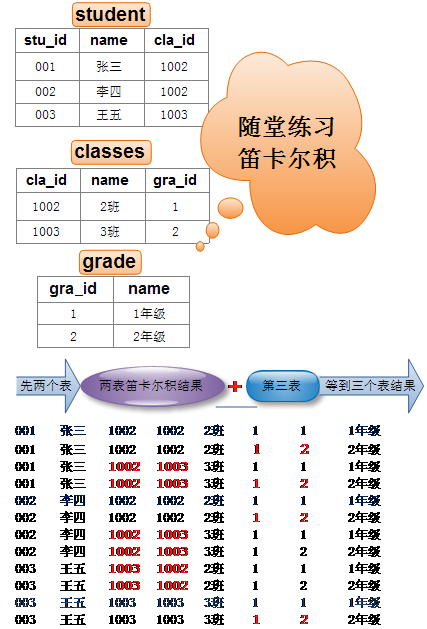
Demo:
左,右连接,内,外连接
l 内连接:
要点:返回的是所有匹配的记录。
select * from a,b where a.x = b.x ////内连接
l 外连接有左连接和右连接两种。
要点:返回的是所有匹配的记录 外加 每行主表外键值为null的一条记录。辅表所有列为null值。
select * from a left join b on a.x=b.x order by a.x //左外连接或称左连接 select * from a right join b on a.x=b.x order by a.x //右外连接或称右连接
select子句顺序
| 子句 | 说明 | 是否必须使用 |
| select | 要返回的列或表示式 | 是 |
| form | 从中检索数据的表 | 仅在从表选择数据时使用 |
| where | 行级过滤 | 否 |
| group by | 分组说明 | 仅在按组计算聚集时使用 |
| having | 组级过滤 | 否 |
| order by | 输出排序顺序 | 否 |
| limit | 要检索的行数 | 否 |
到此这篇关于浅谈MySQL使用笛卡尔积原理进行多表查询的文章就介绍到这了,更多相关MySQL的多表查询内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解MySQL数据库--多表查询--内连接,外连接,子查询,相关子查询
多表查询 使用单个select 语句从多个表格中取出相关的查询结果,多表连接通常是建立在有相互关系的父子表上; 1交叉连接 第一个表格的所有行 乘以 第二个表格中的所有行,也就是笛卡尔积 创建一个消费者与顾客的表格: 代码如下: -- create table customers( -- id int primary key auto_increment, -- name VARCHAR(20)not null, -- address VARCHAR(20)not NULL -- ); -- C
-

MySQL左联多表查询where条件写法示例
复制代码 代码如下: select * from _test a left join _test b on a.id=b.id where a.level='20' and a.month='04' and b.level='20' and b.month='03'; select a.*,b.* from (select * from _test where level='20' and month='04') as a left join (select * from _test where
-
解析Mysql多表查询的实现
查询是数据库的核心,下面就为您介绍Mysql多表查询时如何实现的,如果您在Mysql多表查询方面遇到过问题,不妨一看.Mysql多表查询: 复制代码 代码如下: CREATE TABLE IF NOT EXISTS contact( contact_id int(11) NOT NULL AUTO_INCREMENT, user_name varchar(255), nom varchar(255), prenom varchar(255), mail varchar(64), passcode
-
MySQL多表查询实例详解【链接查询、子查询等】
本文实例讲述了MySQL多表查询.分享给大家供大家参考,具体如下: 准备工作:准备两张表,部门表(department).员工表(employee) create table department( id int, name varchar(20) ); create table employee( id int primary key auto_increment, name varchar(20), sex enum('male','female') not null default 'ma
-
MySQL 多表查询实现分析
我们继续使用前面的例子.前面建立的表中包含了员工的一些基本信息,如姓名.性别.出生日期.出生地.我们再创建一个表,该表用于描述员工所发表的文章,内容包括作者姓名.文章标题.发表日期. 1.查看第一个表 mytable 的内容: mysql> select * from mytable; +----------+------+------------+-----------+ | name | sex | birth | birthaddr | +----------+------+-------
-
浅谈MySQL使用笛卡尔积原理进行多表查询
MySQL的多表查询(笛卡尔积原理) 先确定数据要用到哪些表. 将多个表先通过笛卡尔积变成一个表. 然后去除不符合逻辑的数据(根据两个表的关系去掉). 最后当做是一个虚拟表一样来加上条件即可. 注意:列名最好使用表别名来区别. 笛卡尔积 Demo: 左,右连接,内,外连接 l 内连接: 要点:返回的是所有匹配的记录. select * from a,b where a.x = b.x ////内连接 l 外连接有左连接和右连接两种. 要点:返回的是所有匹配的记录 外加 每行主表外键值为null的
-
浅谈mysql join底层原理
目录 join算法 驱动表和非驱动表的区别 1.Simple Nested-Loop Join,简单嵌套-无索引的情况 2.Index Nested-Loop Join-有索引的情况 3.Block Nested-Loop Join ,join buffer缓冲区 缓冲区大小 数据量大的表和数据量小的表如何选择连接顺序 细节 join算法 mysql只支持一种join算法:Nested-Loop Join(嵌套循环连接),但Nested-Loop Join有三种变种: Simple Nested
-
浅谈MySQL如何优雅的做大表删除
随着时间的推移或者业务量的增长,数据库空间使用率也不断的呈稳定上升状态,当数据库空间将要达到瓶颈的时候,可能我们才会发现数据库有那么一两张的超级大表!他们堆积了从业务开始到现在的全部数据,但是90%的数据都是没有业务价值的,这时候该如何处理这些大表? 既然是没有价值的数据,我们通常一般会选择直接删除或者归档后删除两种,对于数据删除的操作方式来说又可分为两大类: 通过truncate直接删除表中全部数据 通过delete删除表中满足条件记录 一.Truncate操作 从逻辑意义上来讲,trunca
-
浅谈MySQL之浅入深出页原理
一.页的概览 我们往 MySQL 插入的数据最终都是存在页中的.在 InnoDB 中的设计中,页与页之间是通过一个双向链表连接起来. 而存储在页中的一行一行的数据则是通过单链表连接起来的. 上图中的 User Records 的区域就是用来存储行数据的.那 InnoDB 为什么要这么设计?假设我们没有页这个概念,那么当我们查询时,成千上万的数据要如何做到快速的查询出结果?众所周知,MySQL 的性能是不错的,而如果没有页,我们剩下的只能是逐条逐条的遍历数据了. 那页是如何做到快速查询的呢?在当前
-
浅谈MySQL和Lucene索引的对比分析
MySQL和Lucene都可以对数据构建索引并通过索引查询数据,一个是关系型数据库,一个是构建搜索引擎(Solr.ElasticSearch)的核心类库.两者的索引(index)有什么区别呢?以前写过一篇<Solr与MySQL查询性能对比>,只是简单的对比了下查询性能,对于内部原理却没有解释,本文简单分析下两者的索引区别. MySQL索引实现 在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式. M
-
浅谈MySQL 统计行数的 count
MySQL count() 函数我们并不陌生,用来统计每张表的行数.但如果你的表越来越大,且是 InnoDB 引擎的话,会发现计算的速度会越来越慢.在这篇文章里,会先介绍 count() 实现的原理及原因,然后是 count 不同用法的性能分析,最后给出需要频繁改变并需要统计表行数的解决方案. Count() 的实现 InnoDB 和 MyISAM 是 MySQL 常用的数据引擎,由于两者实现的不同,导致 count() 操作计算的效率也不同. 对于 MyISAM 来说,它把每个表的总行数都存在
-
浅谈MySQL中的自增主键用完了怎么办
在面试中,大家应该经历过如下场景 面试官:"用过mysql吧,你们是用自增主键还是UUID?" 你:"用的是自增主键" 面试官:"为什么是自增主键?" 你:"因为采用自增主键,数据在物理结构上是顺序存储,性能最好,blabla-" 面试官:"那自增主键达到最大值了,用完了怎么办?" 你:"what,没复习啊!!" (然后,你就可以回去等通知了!) 这个问题是一个粉丝给我提的,我觉得
-
浅谈MySQL与redis缓存的同步方案
本文介绍MySQL与Redis缓存的同步的两种方案 方案1:通过MySQL自动同步刷新Redis,MySQL触发器+UDF函数实现 方案2:解析MySQL的binlog实现,将数据库中的数据同步到Redis 一.方案1(UDF) 场景分析:当我们对MySQL数据库进行数据操作时,同时将相应的数据同步到Redis中,同步到Redis之后,查询的操作就从Redis中查找 过程大致如下: 在MySQL中对要操作的数据设置触发器Trigger,监听操作 客户端(NodeServer)向MySQL中写入数
-
浅谈mysql执行过程以及顺序
前言:mysql在我们的开发中基本每天都要面对的,作为开发中的数据的来源,mysql承担者存储数据和读写数据的职责.因为学习和了解mysql是至关重要的,那么当我们在客户端发起一个sql到出现详细的查询数据,这其中究竟经历了什么样的过程?mysql服务端是如何处理请求的,又是如何执行sql语句的?本篇博客将来探讨这个问题: 一:mysql执行过程 mysql整体的执行过程如下图所示: 1.1:连接器 连接器的主要职责就是: ①负责与客户端的通信,是半双工模式,这就意味着某一固定时刻只能由客户端向
-
浅谈MySQL表空间回收的正确姿势
目录 前置说明 问题重现 删除数据原理 数据的复用 哪些操作会造成数据空洞 如何收缩表空间 小结 不知道大家有没有遇到这样的一种情况,线上业务在MySQL表上做增删改查操作,随着时间的推移,表里面的数据越来越多,表数据文件越来越大,数据库占用的空间自然也逐渐增长 为了缩小磁盘上表数据文件占用的空间,我们在最大的一张业务表中用delete命令删除了一半儿的旧数据,删除之后,磁盘上表数据文件并没有缩小,即使删除整张表的数据,文件依然没有变小,这是为什么呢? 本文将详细的分析上述问题,并给出正确回收表