聊聊python中令人迷惑的duplicated和drop_duplicates()用法
前言
在算face_track_id map有感:
开始验证
data={'state':[1,1,2,2,1,2,2,2],'pop':['a','b','c','d','b','c','d','d']}
frame=pd.DataFrame(data)
frame

frame.shape $ (8,2)
# 说明duplicated()是对整行进行查重,return 重复了的数据,且只现实n-1条重复的数据(n是重复的次数) frame[frame.duplicated() == True]
一开始还很疑惑,明明(1,b)只出现了1次,哪里duplicate了。其实,人家return的结果是去掉已经出现过一次的行数据了。所以看起来有点confuse,感觉(1,b)并没有重复,但其实人家的函数很简洁呢,返回了重复值而且不冗余。
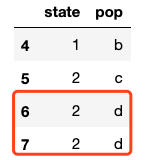
# 说明drop_duplicates()函数是将所有重复的数据都去掉了,且默认保留重复数据的第一条。 # 比如(2,d)出现了3次,在duplicated()中显示了2次,在drop_dupicates()后保留了一个 frame.drop_duplicates().shape $ (4,2)
# 留下了完全唯一的数据行 frame.drop_duplicates()

补充:python的pandas重复值处理(duplicated()和drop_duplicates())
一、生成重复记录数据
import numpy as np import pandas as pd #生成重复数据 df=pd.DataFrame(np.ones([5,2]),columns=['col1','col2']) df['col3']=['a','b','a','c','d'] df['col4']=[3,2,3,2,2] df=df.reindex(columns=['col3','col4','col1','col2']) #将新增的一列排在第一列 df
输出:

二、判断重复记录(行)
#判断重复数据 isDplicated=df.duplicated() #判断重复数据记录 isDplicated
输出:

三、删除重复值
#删除重复值 new_df1=df.drop_duplicates() #删除数据记录中所有列值相同的记录 new_df2=df.drop_duplicates(['col3']) #删除数据记录中col3列值相同的记录 new_df3=df.drop_duplicates(['col4']) #删除数据记录中col4列值相同的记录 new_df4=df.drop_duplicates(['col3','col4']) #删除数据记录中(col3和col4)列值相同的记录 new_df1 new_df2 new_df3 new_df4
输出:


以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pandas.DataFrame.drop_duplicates 用法介绍
如下所示: DataFrame.drop_duplicates(subset=None, keep='first', inplace=False) subset考虑重复发生在哪一列,默认考虑所有列,就是在任何一列上出现重复都算作是重复数据 keep 包含三个参数first, last, False,first是指,保留搜索到的第一个重复数据,之后的都删除:last是指,保留搜索到的最后一个重复数据,之前的搜索到的重复数据都删除,False是指,把所有搜索到的重复数据都删除,一个都不保留,即如果有
-
Python DataFrame使用drop_duplicates()函数去重(保留重复值,取重复值)
摘要 在进行数据分析时,我们经常需要对DataFrame去重,但有时候也会需要只保留重复值. 这里就简单的介绍一下对于DataFrame去重和取重复值的操作. 创建DataFrame 这里首先创建一个包含一行重复值的DataFrame. 2.DataFrame去重,可以选择是否保留重复值,默认是保留重复值,想要不保留重复值的话直接设置参数keep为False即可. 3.取DataFrame重复值.大多时候我们都是需要将数据去重,但是有时候很我们也需要取重复数据,这个时候我们就可以根据刚刚上面我们
-
Pandas之drop_duplicates:去除重复项方法
方法 DataFrame.drop_duplicates(subset=None, keep='first', inplace=False) 参数 这个drop_duplicate方法是对DataFrame格式的数据,去除特定列下面的重复行.返回DataFrame格式的数据. subset : column label or sequence of labels, optional 用来指定特定的列,默认所有列 keep : {'first', 'last', False}, default '
-
详解pandas使用drop_duplicates去除DataFrame重复项参数
Pandas之drop_duplicates:去除重复项 方法 DataFrame.drop_duplicates(subset=None, keep='first', inplace=False) 参数 这个drop_duplicate方法是对DataFrame格式的数据,去除特定列下面的重复行.返回DataFrame格式的数据. subset : column label or sequence of labels, optional 用来指定特定的列,默认所有列 keep : {'firs
-

聊聊python中令人迷惑的duplicated和drop_duplicates()用法
前言 在算face_track_id map有感: 开始验证 data={'state':[1,1,2,2,1,2,2,2],'pop':['a','b','c','d','b','c','d','d']} frame=pd.DataFrame(data) frame frame.shape $ (8,2) # 说明duplicated()是对整行进行查重,return 重复了的数据,且只现实n-1条重复的数据(n是重复的次数) frame[frame.duplicated() == True]
-
聊聊Python中的pypy
PyPy是一个虚拟机项目,主要分为两部分:一个Python的实现和 一个编译器 PyPy的第一部分: 用Python实现的Python 其实这么说并不准确,准确得说应该是用rPython实现的Python,rPython是Python的一个子集,虽然rPython不是完整的Python,但用rPython写的这个Python实现却是可以解释完整的Python语言. PyPy的第二部分:编译器 这是一个编译rPython的编译器,或者说这个编译器有一个rPython的前端,目前也只有这么一个前端,
-
聊聊python中的异常嵌套
在Python中,异常也可以嵌套,当内层代码出现异常时,指定异常类型与实际类型不符时,则向外传,如果与外面的指定类型符合,则异常被处理,直至最外层,运用默认处理方法进行处理,即停止程序,并抛出异常信息.如下代码: try: try: raise IndexError except TypeError: print('get handled') except SyntaxError: print('ok') 运行程序: Traceback (most recent call last): File
-
聊聊python中的循环遍历
python之循环遍历 关于循环遍历大家都知道,不外乎for和while,今天我在这写点不一样的循环和遍历.在实践中有时会遇到删除列表中的元素,那么循环遍历列表删除指定元素该怎么做呢? 还是直接上代码看案例吧: import time # 删除下面列表中所有张姓元素,输出的结果应该是['李老大','李老二'] lst = ['张老大', '张老二', '李老大', '张老三', '李老二']*10000 # 直接for循环遍历列表,remove需要删除的元素 def del1(lst): for
-
python中map、any、all函数用法分析
本文实例讲述了python中map.any.all函数用法.分享给大家供大家参考.具体分析如下: 最近想学python,就一直比较关注python,昨天在python吧看到有个帖子提问怎么在python中怎么判断密码是否符合规范,回帖中有很多用循环的,除此外还有一个没有用循环,代码非常简练,下面是代码: def volid(pwd): a = any(map(str.isupper,pwd)) b = any(map(str.islower,pwd)) c = any(map(str.isdig
-
Python中的异常处理try/except/finally/raise用法分析
本文实例分析了Python中的异常处理try/except/finally/raise用法.分享给大家供大家参考,具体如下: 异常发生在程序执行的过程中,如果python无法正常处理程序就会发生异常,导致整个程序终止执行,python中使用try/except语句可以捕获异常. try/except 异常的种类有很多,在不确定可能发生的异常类型时可以使用Exception捕获所有异常: try: pass except Exception, e: print Exception, ":"
-
对Python中class和instance以及self的用法详解
一. Python 的类和实例 在面向对象中,最重要的概念就是类(class)和实例(instance),类是抽象的模板,而实例是根据类创建出来的一个个具体的 "对象". 就好比,学生是个较为抽象的概念,同时拥有很多属性,可以用一个 Student 类来描述,类中可定义学生的分数.身高等属性,但是没有具体的数值.而实例是类创建的一个个具体的对象, 每一个对象都从类中继承有相同的方法,但是属性值可能不同,如创建一个实例叫 hansry 的学生,其分数为 93,身高为 176,则这个实例拥
-
Python中字典与恒等运算符的用法分析
本文实例讲述了Python中字典与恒等运算符的用法.分享给大家供大家参考,具体如下: 字典 字典是可变数据类型,其中存储的是唯一键到值的映射. elements = {"hydrogen": 1, "helium": 2, "carbon": 6} 字典的键可以是任何不可变类型,例如整数或元组,而不仅仅是字符串.甚至每个键都不一定要是相同的类型! print(elements["helium"]) # 2 我们可以使用方括号并
-
python中的 zip函数详解及用法举例
python中zip()函数用法举例 定义:zip([iterable, ...]) zip()是Python的一个内建函数,它接受一系列可迭代的对象作为参数,将对象中对应的元素打包成一个个tuple(元组),然后返回由这些tuples组成的list(列表).若传入参数的长度不等,则返回list的长度和参数中长度最短的对象相同.利用*号操作符,可以将list unzip(解压),看下面的例子就明白了: 示例1 x = [1, 2, 3] y = [4, 5, 6] z = [7, 8, 9] x
-
python中的split、rsplit、splitlines用法说明
split(分隔符,分割几次)从左向右寻找,以某个元素为中心将左右分割成两个元素并放入列表中,该分隔符丢弃 rsplit(分隔符,分割几次)从右向左寻找,以某个元素为中心将左右分割成两个元素并放入列表中,该分隔符丢弃 splitlines(分隔符,分割几次)根据换行符(\n)分割并将元素放入列表中,该分隔符丢弃 从左向右寻找,以寻找到的第一个"l"为中心将左右分割成两个元素并放入列表中 a = "dlrblist" a1 = a.split("l"