使用pandas模块实现数据的标准化操作
如下所示:
| 3σ 原则 | (u-3*σ ,u+3*σ ) |
| 离差标准化 | (x-min)/(max-min) |
| 标准差标准化 | (x-u)/σ |
| 小数定标标准化 |
x/10**k k=np.ceil(log10(max(|x|))) |
1.3σ原则
u 均值
σ 标准差
正太分布的数据基本都分布在(u-3σ,u+3σ)范围内
其他的数据
import pandas as pd
import numpy as np
def three_sigma(se):
"""
自实现3σ原则,进行数据过滤
:param se:传进来的series结构数据
:return:去除异常值之后的series数据
"""
bool_id=((se.mean()-3*se.std())<se) & (se<(se.mean()+3*se.std()))
print(bool_id)
return se[bool_id]
#加载数据
detail=pd.read_excel('./meal_order_detail.xlsx')
#进行异常值处理
res=three_sigma(detail['amounts'])
print(detail.shape)
print(res.shape)
2.离差标准化
(x-min)/(max-min)
import pandas as pd
import numpy as np
def minmax_sca(data):
"""
离差标准化
param data:传入的数据
return:标准化之后的数据
"""
new_data=(data-data.min())/(data.max()-data.min())
return new_data
#加载数据
detail=pd.read_excel('./meal_order_detail.xlsx')
res=minmax_sca(detail[['amounts','counts']])
print(res)
data=res
bool_id=data.loc[:,'count']==1
print(data.loc[bool_id],'counts')
3.标准差标准化
(x-u)/σ
异常值对标准差标准化的影响不大
转化之后的数据--->均值0 标准差1
import pandas as pd
import numpy as np
def stand_sca(data):
"""
标准差标准化
:param data:传入的数据
:return:标准化之后的数据
"""
new_data=(data-data.mean())/data.std()
return new_data
#加载数据
detail=pd.read_excel('./meal_order_detail.xlsx')
res=stand_sca(detail[['amounts','counts']])
print(res)
print('res的均值:',res.mean())
print('res的标准差:',res.std())
4.小数定标标准化
x/(10^k) k=math.ceil(log10(max(|x|)))
以10为底,x的绝对值的最大值的对数 最后进行向上取整
import pandas as pd
import numpy as np
def deci_sca(data):
"""
自实现小数定标标准化
:param data: 传入的数据
:return: 标准化之后的数据
"""
new_data=data/(10**(np.ceil(np.log10(data.abs().max()))))
return new_data
#加载数据
detail = pd.read_excel('./meal_order_detail.xlsx')
res = deci_sca(detail[['amounts', 'counts']])
print(res)
补充:pandas数据处理基础之标准化与标签数值化
fit(): Method calculates the parameters μ and σ and saves them as internal objects.
解释:简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。
transform(): Method using these calculated parameters apply the transformation to a particular dataset.
解释:在fit的基础上,进行标准化,降维,归一化等操作(看具体用的是哪个工具,如PCA,StandardScaler等)。
fit_transform(): joins the fit() and transform() method for transformation of dataset.
解释:fit_transform是fit和transform的组合,既包括了训练又包含了转换。 transform()和fit_transform()二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等)
fit_transform(trainData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。
Note:
必须先用fit_transform(trainData),之后再transform(testData)
如果直接transform(testData),程序会报错
如果fit_transfrom(trainData)后,使用fit_transform(testData)而不transform(testData),虽然也能归一化,但是两个结果不是在同一个“标准”下的,具有明显差异。(一定要避免这种情况)
注意:StandardScaler().fit_transform(x,fit_params),fit_params决定标准化的标签数据,就是每个标准化的标杆数据,此参数不同,则每次标准化的过程则不同。
from sklearn import preprocessing # 获取数据 cols = ['OverallQual','GrLivArea', 'GarageCars','TotalBsmtSF', 'FullBath', 'TotRmsAbvGrd', 'YearBuilt'] ##选取列 x = data_train[cols].values y = data_train['SalePrice'].values x_scaled = preprocessing.StandardScaler().fit_transform(x) ##进行归一化 y_scaled = preprocessing.StandardScaler().fit_transform(y.reshape(-1,1))##先将y转换成一列,再进行归一
还有以下形式,和上面的标准化原理一致,都是先fit,再transform。
由ss决定标准化进程的独特性
# 先将数据标准化 from sklearn.preprocessing import StandardScaler ss = StandardScaler() ## #用测试集训练并标准化 ss.fit(missing_age_X_train)##首先fit missing_age_X_train = ss.transform(missing_age_X_train) #进行transform missing_age_X_test = ss.transform(missing_age_X_test)
标签数值化
1.当某列数据不是数值型数据时,将难以标准化,此时要将数据转化成数据型形式。
数据处理前数据显示:
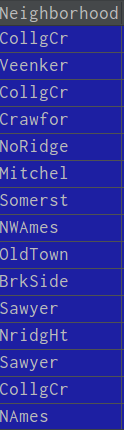
经过标签化数据处理
from sklearn import preprocessing
f_names = ['CentralAir', 'Neighborhood'] ##需要处理的数据标签
for x in f_names:
label = preprocessing.LabelEncoder()
data_train[x] = label.fit_transform(data_train[x]) ##数据标准化
处理之后变成:
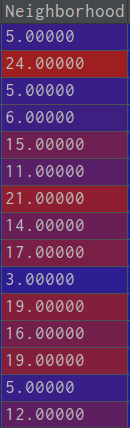
2.当某列有对应的标签值时,即某个量对应相应确定的标签时,例如oldtown就对应1,sawyer就对应2,分类的str转换为序列类这时使用如下:
数据处理之前
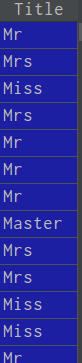
利用转换:
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}#将标签对应数值
train_df['Title'] = train_df['Title'].map(title_mapping)#处理数据
train_df['Title'] = train_df['Title'].fillna(0)##将其余标签填充为0值
处理过后:

3.多个数据标签需要分列采用one_hot形式时,处理之前

处理之后
train_test.loc[train_test["Age"].isnull() ,"age_nan"] = 1 ##将标签转换成1 train_test.loc[train_test["Age"].notnull() ,"age_nan"] = 0##将此标签成为0 train_test = pd.get_dummies(train_test,columns=['age_nan']) ##columns决定哪几行分列处理,prefix参数是每列前缀
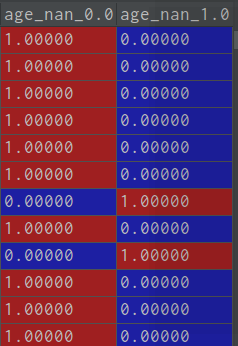
one_hot 形式转变成功。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Pandas 数据处理,数据清洗详解
如下所示: # -*-coding:utf-8-*- from pandas import DataFrame import pandas as pd import numpy as np """ 获取行列数据 """ df = DataFrame(np.random.rand(4, 5), columns=['A', 'B', 'C', 'D', 'E']) print df print df['col_sum'] = df.apply(lam
-
pandas 对每一列数据进行标准化的方法
两种方式 >>> import numpy as np >>> import pandas as pd Backend TkAgg is interactive backend. Turning interactive mode on. >>> np.random.seed(1) >>> df_test = pd.DataFrame(np.random.randn(4,4)* 4 + 3) >>> df_test 0
-

pandas数据处理之 标签列字符转数字的实现
机器学习中,当我们在进行数据预处理的时候,对于标签列非字符的数据,我们往往需要将其转换成字符,因为有的算法可能不支持非数字类型来做特征. 那么怎么快捷地来着这个转换呢,请看我的示例: 1.构建测试数据 import pandas as pd array = ['good','bad','well','bad','good','good','well','good'] 2.数据转换下,并获取标签列的字典 df = pd.DataFrame(array,columns=['status']) sta
-
pandas数据处理进阶详解
一.pandas的统计分析 1.关于pandas 的数值统计(统计detail 中的 单价的相关指标) import pandas as pd # 加载数据 detail = pd.read_excel("./meal_order_detail.xlsx") print("detail :\n", detail) print("detail 的列索引名称:\n", detail.columns) print("detail 的形状:\n
-
使用pandas模块实现数据的标准化操作
如下所示: 3σ 原则 (u-3*σ ,u+3*σ ) 离差标准化 (x-min)/(max-min) 标准差标准化 (x-u)/σ 小数定标标准化 x/10**k k=np.ceil(log10(max(|x|))) 1.3σ原则 u 均值 σ 标准差 正太分布的数据基本都分布在(u-3σ,u+3σ)范围内 其他的数据 import pandas as pd import numpy as np def three_sigma(se): """ 自实现3σ原则,进行数据过滤
-
Python Pandas模块实现数据的统计分析的方法
一.groupby函数 Python中的groupby函数,它主要的作用是进行数据的分组以及分组之后的组内的运算,也可以用来探索各组之间的关系,首先我们导入我们需要用到的模块 import pandas as pd 首先导入我们所需要用到的数据集 customer = pd.read_csv("Churn_Modelling.csv") marketing = pd.read_csv("DirectMarketing.csv") 我们先从一个简单的例子着手来看, c
-
Windows下Python使用Pandas模块操作Excel文件的教程
安装Python环境 ANACONDA是一个Python的发行版本,包含了400多个Python最常用的库,其中就包括了数据分析中需要经常使用到的Numpy和Pandas等.更重要的是,不论在哪个平台上,都可以一键安装,自动配置好环境,不需要用户任何的额外操作,非常方便.因此,安装Python环境就只需要到ANACONDA网站上下载安装文件,双击安装即可. ANACONDA官方下载地址:https://www.continuum.io/downloads 安装完成之后,使用windows + r
-
Python3使用pandas模块读写excel操作示例
本文实例讲述了Python3使用pandas模块读写excel操作.分享给大家供大家参考,具体如下: 前言 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,能使我们快速便捷地处理数据.本文介绍如何用pandas读写excel. 1. 读取excel 读取excel主要通过read_excel函数实现,除了pandas
-
使用pandas实现连续数据的离散化处理方式(分箱操作)
Python实现连续数据的离散化处理主要基于两个函数,pandas.cut和pandas.qcut,前者根据指定分界点对连续数据进行分箱处理,后者则可以根据指定箱子的数量对连续数据进行等宽分箱处理,所谓等宽指的是每个箱子中的数据量是相同的. 下面简单介绍一下这两个函数的用法: # 导入pandas包 import pandas as pd ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32] # 待分箱数据 bins = [18, 25,
-
分享20个Pandas短小精悍的数据操作
目录 1. ExcelWriter 2. pipe 3. factorize 4. explode 5. squeeze 6. between 7. T 8. pandas styler 9. Pandas options 10. convert_dtypes 11. select_dtypes 12. mask 13. 列轴的min.max 14. nlargest.nsmallest 15. idmax.idxmin 16. value_counts 17. clip 18. at_time
-
Pandas处理时间序列数据操作详解
目录 前言 一.获取时间 二.时间索引 三.时间推移 前言 一般从数据库或者是从日志文件读出的数据均带有时间序列,做时序数据处理或者实时分析都需要对其时间序列进行归类归档.而Pandas是处理这些数据很好用的工具包.此篇博客基于Jupyter之上进行演示,本篇博客的愿景是希望我或者读者通过阅读这篇博客能够学会方法并能实际运用.希望读者看完能够提出问题或者看法,博主会长期维护博客做及时更新.纯分享,希望大家喜欢. 一.获取时间 python自带datetime库,通过调用此库可以获取本地时间 fr
-
Python利用pandas处理Excel数据的应用详解
最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做自动化测试的时候,如果涉及到数据的读取和存储,那么而利用pandas就会非常高效,基本上3行代码可以搞定你20行代码的操作!该教程仅仅限于结合柠檬班的全栈自动化测试课程来讲解下pandas在项目中的应用,这仅仅只是冰山一角,希望大家可以踊跃的去尝试和探索! 一.安装环境: 1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令
-
Python3.5 Pandas模块缺失值处理和层次索引实例详解
本文实例讲述了Python3.5 Pandas模块缺失值处理和层次索引.分享给大家供大家参考,具体如下: 1.pandas缺失值处理 import numpy as np import pandas as pd from pandas import Series,DataFrame df3 = DataFrame([ ["Tom",np.nan,456.67,"M"], ["Merry",34,345.56,np.nan], [np.nan,np