Python如何导出导入所有依赖包详解
导出所有依赖包
整个环境的依赖包导出
进入项目目录,执行以下命令:
pip freeze > requirements.txt
然后在当前目录是可以看到生成 “requirements.txt” 文件,可以打开看看,会发现有很多个包信息,其实这里是把你当前 python 环境的所有包的相关信息导出来了。如果我们只需导出当前项目所需的依赖包,我可以采用另外一种方式。
只导出项目所需的依赖包
进入项目目录,执行以下命令:
pipreqs ./
默认情况下,是没有安装 “pipregs” 插件,所以会提示以下错误:
pipreqs: command not found
因此,我们需要安装这个插件,执行以下命令:
pip install pipreqs

注意: 如果你是多虚拟环境的,需要你进入到指定的虚拟环境来进行安装,否则也是没法使用。
安装好后,我们就执行以下命令来导出依赖包:
pipreqs ./
稍微等一会就可以导出成功:

可以打开 “requirements.tx” 文件看看,会发现少了很多多余的依赖包信息。
导入依赖包
我们可以用上面的“requirements.txt”文件来导入依赖包,快速构建好环境。特别是我们需要把项目迁移到其它环境进行部署,此时就非常方便了。
我自己在我的环境新建一个 python 环境 “my_py37_test" ,将上述的代码工程移到这个环境,先直接运行看看效果,发现是报错,报没有相应库,这个和我们预料一样,我们确实还没有安装相应的库。
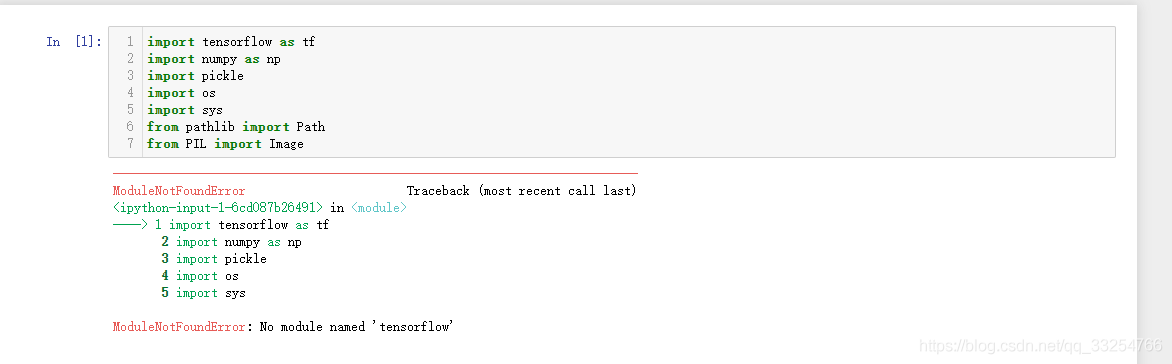
我们可以通过以下命令来执行:
pip install -r requirements.txt

执行完后,我们重新运行代码,可以发现,是没有问题的。
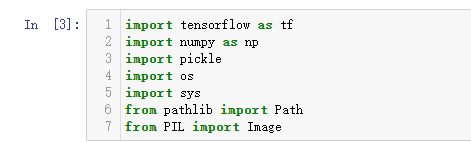
总结
到此这篇关于Python如何导出导入所有依赖包的文章就介绍到这了,更多相关Python导出导入依赖包内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python如何导入依赖包
第一步:打开pycharm:File-->Settings 第二步:Project:(你的项目名)-->Project InterPreter-->点击右边的加号 第三步:在窗口中搜索要下载的依赖-->选中并点击左下角的install package即可导入依赖包 内容扩展: python 导入导出依赖包命令 程序中必须包含一个 requirements.txt 文件,用于记录所有依赖包及其精确的版本号.如果 要在另一台电脑上重新生成虚拟环境,这个文件的重要性就体现出来了,例如部署
-

Python如何导出导入所有依赖包详解
导出所有依赖包 整个环境的依赖包导出 进入项目目录,执行以下命令: pip freeze > requirements.txt 然后在当前目录是可以看到生成 "requirements.txt" 文件,可以打开看看,会发现有很多个包信息,其实这里是把你当前 python 环境的所有包的相关信息导出来了.如果我们只需导出当前项目所需的依赖包,我可以采用另外一种方式. 只导出项目所需的依赖包 进入项目目录,执行以下命令: pipreqs ./ 默认情况下,是没有安装 "pi
-
MongoDB 导出导入备份恢复数据详解及实例
数据库备份和数据恢复的重要性,我想大家都知道,这里就举例说明如何操作数据备份,数据恢复的实例: 创建测试数据 创建db:testdb,collection:user,插入10条记录 mongo MongoDB shell version: 3.0.2 connecting to: test > use testdb switched to db testdb > db.user.insert({id:1,name:"用户1"}); WriteResult({ "n
-
Python实现多线程爬表情包详解
目录 课程亮点 环境介绍 模块使用 流程 一. 分析我们想要的数据内容 是可以从哪里获取 二. 代码实现步骤 导入模块 单线程爬取10页数据 多进程爬取10页数据 课程亮点 系统分析目标网页 html标签数据解析方法 海量图片数据一键保存 环境介绍 python 3.8 pycharm 模块使用 requests >>> pip install requests parsel >>> pip install parsel time 时间模块 记录运行时间 流程 一. 分
-
Python基于Flask框架配置依赖包信息的项目迁移部署
一般在本机上完成基于Flask框架的代码编写后,如果有接口或者数据操作方面需求需要把代码部署到指定服务器上. 一般情况下,使用Flask框架开发者大多数都是选择Python虚拟环境来运行项目,不同的虚拟环境中配置依赖包信息不同.如果重新迁移到一个新的虚拟环境后,又重新来一个一个的配置依赖包,那将会很浪费时间. 下面介绍一个简单易用的技巧,也是我自己在书本上看到的,以防每次配置需要翻阅书籍的麻烦,所以单自写一篇文章作记录,方便自己以后查看,也希望给其他学习的同学有点帮助. 完成项目相关代码编写后,
-
Python爬虫进阶之Beautiful Soup库详解
一.Beautiful Soup库简介 BeautifulSoup4 是一个 HTML/XML 的解析器,主要的功能是解析和提取 HTML/XML 的数据.和 lxml 库一样. lxml 只会局部遍历,而 BeautifulSoup4 是基于 HTML DOM 的,会加载整个文档,解析 整个 DOM 树,因此内存开销比较大,性能比较低. BeautifulSoup4 用来解析 HTML 比较简单,API 使用非常人性化,支持 CSS 选择器,是 Python 标准库中的 HTML 解析器,也支
-
利用Python多处理库处理3D数据详解
今天我们将介绍处理大量数据时非常方便的工具.我不会只告诉您可能在手册中找到的一般信息,而是分享一些我发现的小技巧,例如tqdm与 multiprocessingimap一起使用.并行处理档案.绘制和处理 3D 数据以及如何搜索如果您有点云,则用于对象网格中的类似对象. 那么我们为什么要求助于并行计算呢?如今,如果您处理任何类型的数据,您可能会面临与"大数据"相关的问题.每次我们有不适合 RAM 的数据时,我们都需要一块一块地处理它.幸运的是,现代编程语言允许我们生成在多核处理器
-
Python中__init__.py文件的作用详解
__init__.py 文件的作用是将文件夹变为一个Python模块,Python 中的每个模块的包中,都有__init__.py 文件. 通常__init__.py 文件为空,但是我们还可以为它增加其他的功能.我们在导入一个包时,实际上是导入了它的__init__.py文件.这样我们可以在__init__.py文件中批量导入我们所需要的模块,而不再需要一个一个的导入. # package # __init__.py import re import urllib import sys impo
-
Python编程使用NLTK进行自然语言处理详解
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向.自然语言工具箱(NLTK,NaturalLanguageToolkit)是一个基于Python语言的类库,它也是当前最为流行的自然语言编程与开发工具.在进行自然语言处理研究和应用时,恰当利用NLTK中提供的函数可以大幅度地提高效率.本文就将通过一些实例来向读者介绍NLTK的使用. NLTK NaturalLanguageToolkit,自然语言处理工具包,在NLP领域中,最常使用的一个Python库. NLTK是一个开源的项目,包含:P
-
用 Python 连接 MySQL 的几种方式详解
尽管很多 NoSQL 数据库近几年大放异彩,但是像 MySQL 这样的关系型数据库依然是互联网的主流数据库之一,每个学 Python 的都有必要学好一门数据库,不管你是做数据分析,还是网络爬虫,Web 开发.亦或是机器学习,你都离不开要和数据库打交道,而 MySQL 又是最流行的一种数据库,这篇文章介绍 Python 操作 MySQL 的几种方式,你可以在实际开发过程中根据实际情况合理选择. 1.MySQL-python MySQL-python 又叫 MySQLdb,是 Python 连接 M
-
对Python 窗体(tkinter)树状数据(Treeview)详解
如下所示: import tkinter from tkinter import ttk #导入内部包 win=tkinter.Tk() tree=ttk.Treeview(win) #参数:parent, index, iid=None, **kw (父节点,插入的位置,id,显示出的文本) myid=tree.insert("",0,"中国",text="中国China",values=("1")) # "&qu