python机器学习基础线性回归与岭回归算法详解
目录
- 一、什么是线性回归
- 1.线性回归简述
- 2.数组和矩阵
- 数组
- 矩阵
- 3.线性回归的算法
- 二、权重的求解
- 1.正规方程
- 2.梯度下降
- 三、线性回归案例
- 1.案例概述
- 2.数据获取
- 3.数据分割
- 4.数据标准化
- 5.模型训练
- 6.回归性能评估
- 7.梯度下降与正规方程区别
- 四、岭回归Ridge
- 1.过拟合与欠拟合
- 2.正则化
一、什么是线性回归
1.线性回归简述
线性回归,是一种趋势,通过这个趋势,我们能预测所需要得到的大致目标值。线性关系在二维中是直线关系,三维中是平面关系。
我们可以使用如下模型来表示线性回归:y = wx+b(w是权重,x是特征,b是偏置项)
当有多个特征时,线性关系模型如下图所示:


2.数组和矩阵
数组
数组可以是多维的,各个维度的数组表示如下:
0维:5
1维:[1,2,5,5,4,8]
2维:[[1,4,5],[1,4,7]]
3维:[[[1,4,5],[1,4,7]],[[1,4,5],[1,4,7]]]
数组运算有加法,乘法。具体计算可以在python中尝试,数组是ndarray类型。3.
矩阵
矩阵特点:必须是二维,矩阵的运算满足了特定的需求。我们可以仅仅通过1步的矩阵乘法,就得出w1*x1+w2*x2+w3*x3这样模型的结果。
矩阵乘法的要求会涉及到矩阵的形状要求:m*n的矩阵 * n*p的矩阵,结果是m*p的矩阵
也就是说,第一个矩阵的列数,必须要和第二个矩阵的行数相同。
3.线性回归的算法
线性回归是一种迭代的算法。我们需要建立一个函数,对于每一个特征x(i)都有一个对应的权重w(i),两者相乘,并最终把所有的特征权重乘积求和,就是我们的目标结果。但如何寻找到最佳的权重,从而使得模型能够最好地拟合我们的样本呢?
线性回归的迭代算法的每次迭代,都会更新权重w(i)的值,使模型往靠近样本点的地方更加靠近,而损失函数,就是我们用来求得最佳权重的函数。
损失函数定义如下:

损失意思就是预测的各个目标值,与各个原目标值的差的平方和(误差平方和)。损失越小也就是预测值与原值越接近,效果越好。该方法也称为最小二乘法。当损失函数达到最小值时,所对应的权重w,就是我们的目标权重。
二、权重的求解
1.正规方程
是求权重w的一种方法,适用于特征少的数据。用的比较少。

2.梯度下降
该方法通过指定学习率,并利用梯度,迭代更新权重。通常都使用这个方法。

正规方程API:sklearn.linear_model.LinearRegression()
梯度下降API:sklearn.linear_model.SGDRegressor()
两个算法都可以通过.coef_得到回归系数,学习率是一个超参数,也可使用网格交叉验证进行调优。
三、线性回归案例
1.案例概述
通过从sklearn中获取的“波士顿房价预测”数据进行房价预测,特征有很多,比如该镇的人均犯罪率、一氧化氮浓度、低收入人群占比等。我们对每一个特征都给出一个权重,通过算法,求得最佳的权重即可。
2.数据获取
导入数据代码:
from sklearn.datasets import load_boston lb = load_boston()
3.数据分割
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
4.数据标准化
此处的数据,需要对特征数据以及目标值数据都进行标准化,并且需要用不同的标准。
导入标准化方法:from sklearn.preprocessing import StandardScaler
x实例化方法:std_x = StandardScaler()
y实例化方法:std_y = StandardScaler()
标准化:
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
y_train = std_y.fit_transform(y_train)
y_test = std_y.transform(y_test)
5.模型训练
注意,训练后得出的目标值,是标准化后的,因此需要使用StandardScaler中的inverse_transform进行转换回原来的值。
实例化算法:lr = LinearRegressor()
将数据转为二维:y_train = y_train.reshape(-1,1)
训练算法:lr.fit(x_train, y_train)
预测结果:y_predict = lr.predict(x_test)
结果转为正常结果:y_lr_predict = std.inverse_transform(y_predict)
6.回归性能评估

通过对预测值也真实值计算均方误差可得,API中,输入真实目标值,以及预测目标值即可(注意:输入的都是标准化之前的值。
API:sklearn.metrics.mean_squared_error(y_true, y_pred)
线性回归性能评估:mean_squared_error(y_test, y_lr_predict)
以上为使用线性回归算法,对房价进行的预测。其他的算法,具体操作基本一致。
7.梯度下降与正规方程区别
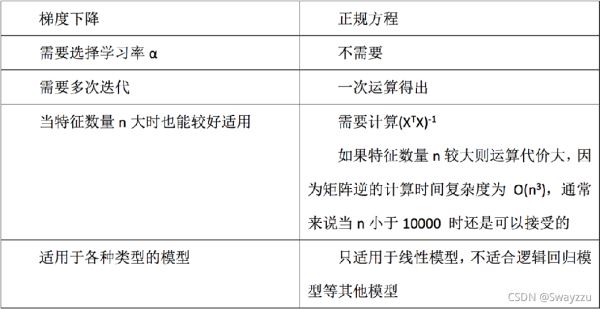
特点:线性回归器是最为简单、易用的回归模型。 从某种程度上限制了使用,尽管如此,在不知道特征之间关系的前提下,我们仍然使用线性回归器作为大多数系统的首要选择。
小规模数据可以使用LinearRegression(不能解决拟合问题)以及其它
大规模数据需要使用梯度下降法,SGDRegressor
四、岭回归Ridge
1.过拟合与欠拟合
欠拟合:一个假设在训练数据上不能获得更好的拟合, 但是在训练数据外的数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
解决方法:增加特征
过拟合:一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
解决方法:正则化
2.正则化
L2正则化是通过减少权重的方式,对模型进行优化,以解决过拟合的问题。该方法可以使得权重的每个元素都非常接近于0,参数变小,则模型变简单。从而达到解决过拟合问题的效果。
岭回归就是带有正则化的线性回归。
岭回归API:sklearn.linear_model.Ridge

正则化中,alpha(或者lambda)越大,说明对参数的惩罚越大,参数就越趋近于0。
岭回归优点:回归得到的回归系数更符合实际,更可靠。另外,能让估计参数的波动范围变小,变的更稳定。在存在病态数据偏多的研究中有较大的实用价值。
以上就是python机器学习基础线性回归与岭回归算法详解的详细内容,更多关于python线性回归与岭回归算法的资料请关注我们其它相关文章!
相关推荐
-

python机器学习之线性回归详解
一.python机器学习–线性回归 线性回归是最简单的机器学习模型,其形式简单,易于实现,同时也是很多机器学习模型的基础. 对于一个给定的训练集数据,线性回归的目的就是找到一个与这些数据最吻合的线性函数. 二.OLS线性回归 2.1 Ordinary Least Squares 最小二乘法 一般情况下,线性回归假设模型为下,其中w为模型参数 线性回归模型通常使用MSE(均方误差)作为损失函数,假设有m个样本,均方损失函数为:(所有实例预测值与实际值误差平方的均值) 由于模型的训练目标为找到使得损
-
python实现机器学习之元线性回归
一.理论知识准备 1.确定假设函数 如:y=2x+7 其中,(x,y)是一组数据,设共有m个 2.误差cost 用平方误差代价函数 3.减小误差(用梯度下降) 二.程序实现步骤 1.初始化数据 x.y:样本 learning rate:学习率 循环次数loopNum:梯度下降次数 2.梯度下降 循环(循环loopNum次): (1)算偏导(需要一个for循环遍历所有数据) (2)利用梯度下降数学式子 三.程序代码 import numpy as np def linearRegression(d
-
python机器基础逻辑回归与非监督学习
目录 一.逻辑回归 1.模型的保存与加载 2.逻辑回归原理 ①逻辑回归的输入 ②sigmoid函数 ③逻辑回归的损失函数 ④逻辑回归特点 3.逻辑回归API 4.逻辑回归案例 ①案例概述 ②具体流程 5.逻辑回归总结 二.非监督学习 1.k-means聚类算法原理 2.k-means API 3.聚类性能评估 ①性能评估原理 ②性能评估API 一.逻辑回归 1.模型的保存与加载 模型训练好之后,可以直接保存,需要用到joblib库.保存的时候是pkl格式,二进制,通过dump方法保存.加载的时候
-
python实现机器学习之多元线性回归
总体思路与一元线性回归思想一样,现在将数据以矩阵形式进行运算,更加方便. 一元线性回归实现代码 下面是多元线性回归用Python实现的代码: import numpy as np def linearRegression(data_X,data_Y,learningRate,loopNum): W = np.zeros(shape=[1, data_X.shape[1]]) # W的shape取决于特征个数,而x的行是样本个数,x的列是特征值个数 # 所需要的W的形式为 行=特征个数,列=1 这
-
8种用Python实现线性回归的方法对比详解
前言 说到如何用Python执行线性回归,大部分人会立刻想到用sklearn的linear_model,但事实是,Python至少有8种执行线性回归的方法,sklearn并不是最高效的. 今天,让我们来谈谈线性回归.没错,作为数据科学界元老级的模型,线性回归几乎是所有数据科学家的入门必修课.抛开涉及大量数统的模型分析和检验不说,你真的就能熟练应用线性回归了么?未必! 在这篇文章中,文摘菌将介绍8种用Python实现线性回归的方法.了解了这8种方法,就能够根据不同需求,灵活选取最为高效的方法实现线
-
python机器学习基础线性回归与岭回归算法详解
目录 一.什么是线性回归 1.线性回归简述 2.数组和矩阵 数组 矩阵 3.线性回归的算法 二.权重的求解 1.正规方程 2.梯度下降 三.线性回归案例 1.案例概述 2.数据获取 3.数据分割 4.数据标准化 5.模型训练 6.回归性能评估 7.梯度下降与正规方程区别 四.岭回归Ridge 1.过拟合与欠拟合 2.正则化 一.什么是线性回归 1.线性回归简述 线性回归,是一种趋势,通过这个趋势,我们能预测所需要得到的大致目标值.线性关系在二维中是直线关系,三维中是平面关系. 我们可以使用如下模
-
python机器学习创建基于规则聊天机器人过程示例详解
目录 聊天机器人 基于规则的聊天机器人 创建语料库 创建一个聊天机器人 总结 还记得这个价值一个亿的AI核心代码? while True: AI = input('我:') print(AI.replace("吗", " ").replace('?','!').replace('?','!')) 以上这段代码就是我们今天的主题,基于规则的聊天机器人 聊天机器人 聊天机器人本身是一种机器或软件,它通过文本或句子模仿人类交互. 简而言之,可以使用类似于与人类对话的软件进
-
Python 25行代码实现的RSA算法详解
本文实例讲述了Python 25行代码实现的RSA算法.分享给大家供大家参考,具体如下: 网络上很多关于RSA算法的原理介绍,但是翻来翻去就是没有一个靠谱的算法实现,即使有代码介绍,也都是直接调用JDK或者Python代码包中的API实现,或者即使有代码也都写得特别烂.无形中让人感觉RSA加密算法竟然这么高深,然后就看不下去了.还有我发现对于"大整数的幂次乘方取模"竟然采用直接计算的幂次的值,再取模,类似于(2 ^ 1024) ^ (2 ^ 1024),这样的计算就直接去计算了,我不知
-
python机器学习包mlxtend的安装和配置详解
今天看到了mlxtend的包,看了下example集成得非常简洁.还有一个吸引我的地方是自带了一些data直接可以用,省去了自己造数据或者找数据的处理过程,所以决定安装体验一下. 依赖环境 首先,sudo pip install mlxtend 得到基础环境. 然后开始看看系统依赖问题的解决.大致看了下基本都是python科学计算用的那几个经典的包,主要是numpy,scipy,matplotlib,sklearn这些. LINUX环境下的话,一般这些都比较好装pip一般都能搞定. 这里要说的一
-
Python编程基础之构造方法和析构方法详解
目录 一.本讲学习目标 二.构造方法 (一)概述 (二)案例演示 三.析构方法 (一)概述 (二)案例演示 四.self的使用 (一)self概述 (二)案例演示 总结 一.本讲学习目标 1.掌握构造方法的使用 2.掌握析构方法的使用 3.掌握self变量的使用 二.构造方法 (一)概述 构造方法指的是__init__()方法. 当创建类的实例的时候,系统会自动调用构造方法,从而实现对类进行初始化的操作. (二)案例演示 编写程序 - 演示构造方法.py 构造方法第一个参数 必须是self,表示
-
python机器学习基础K近邻算法详解KNN
目录 一.k-近邻算法原理及API 1.k-近邻算法原理 2.k-近邻算法API 3.k-近邻算法特点 二.k-近邻算法案例分析案例信息概述 第一部分:处理数据 1.数据量缩小 2.处理时间 3.进一步处理时间 4.提取并构造时间特征 5.删除无用特征 6.签到数量少于3次的地点,删除 7.提取目标值y 8.数据分割 第二部分:特征工程 标准化 第三部分:进行算法流程 1.算法执行 2.预测结果 3.检验效果 一.k-近邻算法原理及API 1.k-近邻算法原理 如果一个样本在特征空间中的k个最相
-
python机器学习基础特征工程算法详解
目录 一.机器学习概述 二.数据集的构成 1.数据集存储 2.可用的数据集 3.常用数据集的结构 三.特征工程 1.字典数据特征抽取 2.文本特征抽取 3.文本特征抽取:tf-idf 4.特征预处理:归一化 5.特征预处理:标准化 6.特征预处理:缺失值处理 一.机器学习概述 机器学习是从数据中,自动分析获得规律(模型),并利用规律对未知数据进行预测. 二.数据集的构成 1.数据集存储 机器学习的历史数据通常使用csv文件存储. 不用mysql的原因: 1.文件大的话读取速度慢: 2.格式不符合
-
用TensorFlow实现lasso回归和岭回归算法的示例
也有些正则方法可以限制回归算法输出结果中系数的影响,其中最常用的两种正则方法是lasso回归和岭回归. lasso回归和岭回归算法跟常规线性回归算法极其相似,有一点不同的是,在公式中增加正则项来限制斜率(或者净斜率).这样做的主要原因是限制特征对因变量的影响,通过增加一个依赖斜率A的损失函数实现. 对于lasso回归算法,在损失函数上增加一项:斜率A的某个给定倍数.我们使用TensorFlow的逻辑操作,但没有这些操作相关的梯度,而是使用阶跃函数的连续估计,也称作连续阶跃函数,其会在截止点跳跃扩
-
Python 机器学习之线性回归详解分析
为了检验自己前期对机器学习中线性回归部分的掌握程度并找出自己在学习中存在的问题,我使用C语言简单实现了单变量简单线性回归. 本文对自己使用C语言实现单变量线性回归过程中遇到的问题和心得做出总结. 线性回归 线性回归是机器学习和统计学中最基础和最广泛应用的模型,是一种对自变量和因变量之间关系进行建模的回归分析. 代码概述 本次实现的线性回归为单变量的简单线性回归,模型中含有两个参数:变量系数w.偏置q. 训练数据为自己使用随机数生成的100个随机数据并将其保存在数组中.采用批量梯度下降法训练模型,