python学习与数据挖掘应知应会的十大终端命令
目录
- 1、wget
- 2、head
- 3、tail
- 4、wc
- 5、grep
- 6、cat
- 7、find
- 8、sort
- 9、nano
- 10、Variables
IT界的每个人都应该知道终端(Terminal)的基本知识,数据科学家也不例外。有时,终端是你的全部,尤其是在将模型和数据管道部署到远程机器时。
让我们开始吧!
1、wget
wget实用程序用于从远程服务器下载文件。你可以用它来下载数据集,只要你知道网址,可以使用wget命令下载它,我以如下url为例:
https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv

如果你在Mac上,默认情况下wget不可用,请从终端执行brew install wget进行安装。数据集现在已经下载,让我们继续一些基本的探索。
2、head
如果你是Python用户,这会让您感到熟悉。否则,head命令用于打印文件的前N行。默认打印10行:

如果你想要一个不同的数字,比如说3,你可以使用-n参数。完整的命令是:
head -n 3 airline-passengers.csv
3、tail
tail命令与head命令非常相似,但它将打印最后N行。
默认打印10行:

与head一样,还可以使用-n参数指定要打印的行数。
我们现在已经介绍了基础知识,所以让我们继续讲一些更有趣的内容。
4、wc
有时你想知道文件中有多少个数据点。不需要打开它并手动滚动到底部。一个简单的命令可以为您节省一些时间:

总之,airline-passengers.csv文件包含144行。
5、grep
此命令用于处理文本,可以匹配字符串和正则表达式。我们将使用它只提取包含字符串“1949”的行。这是一个简单的数据集,所以我们不会有任何问题。默认情况下,grep命令将打印结果,但我们可以将其保存到另一个CSV文件:

6、cat
为了验证上一个操作是否成功,我们可以使用cat命令。它用于将整个文件打印到shell。你也可以用它来组合文件和更多,但这是另一个时间的主题。
现在,让我们打印整个文件。数据是按月汇总的,因此总共应该有12行:

7、find
你可以使用find命令搜索文件和文件夹。例如,执行以下命令将当前目录(由点指定)中的所有CSV文件打印到shell:

星号(*)表示文件名无关紧要,只要它以“.csv”结尾。
8、sort
顾名思义,sort命令可用于按某种标准对文件内容进行排序。例如,以下命令按乘客数量升序对数据集进行排序:

-k2参数指定对第二列进行排序。如果要按降序对文件排序,可以指定一个附加的-r参数:

9、nano
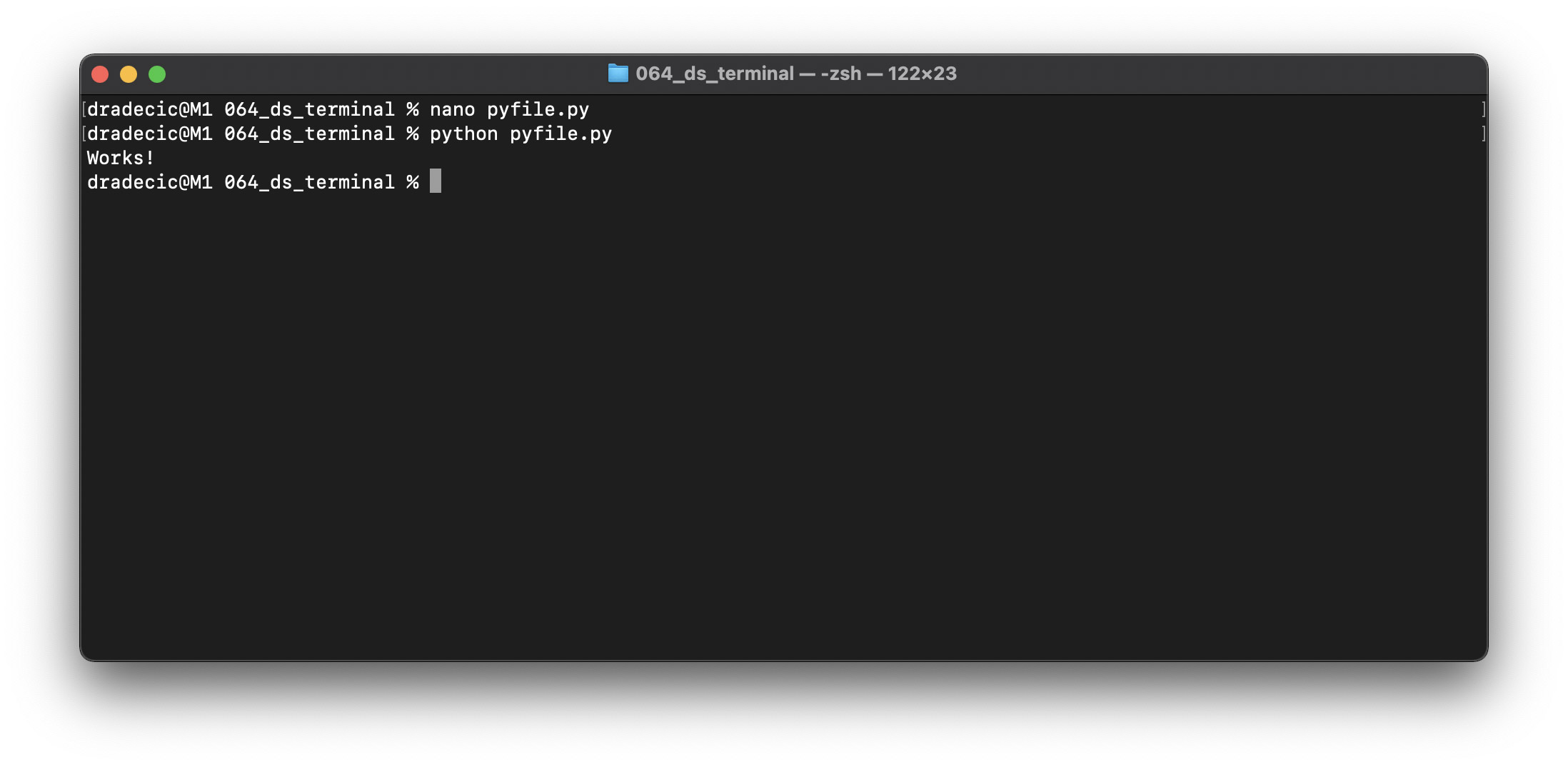
虽然技术上不是shell命令,但执行它会打开Nano编辑器。下面是如何创建Python文件:
nano pyfile.py
在这里,让我们编写一些简单的Python代码:

您可以在编辑器中编写任何Python代码,并进行对于简单终端命令来说过于复杂的分析。完成后,可以运行Python文件:
10、Variables
让我们用Variables来结束今天的文章。例如,当文件路径变长时,或者您需要多次使用它们时,它们可以派上用场。
下面是如何声明两个字符串变量并使用mv命令将airline-passengers-1949.csv文件重命名为new.csv:
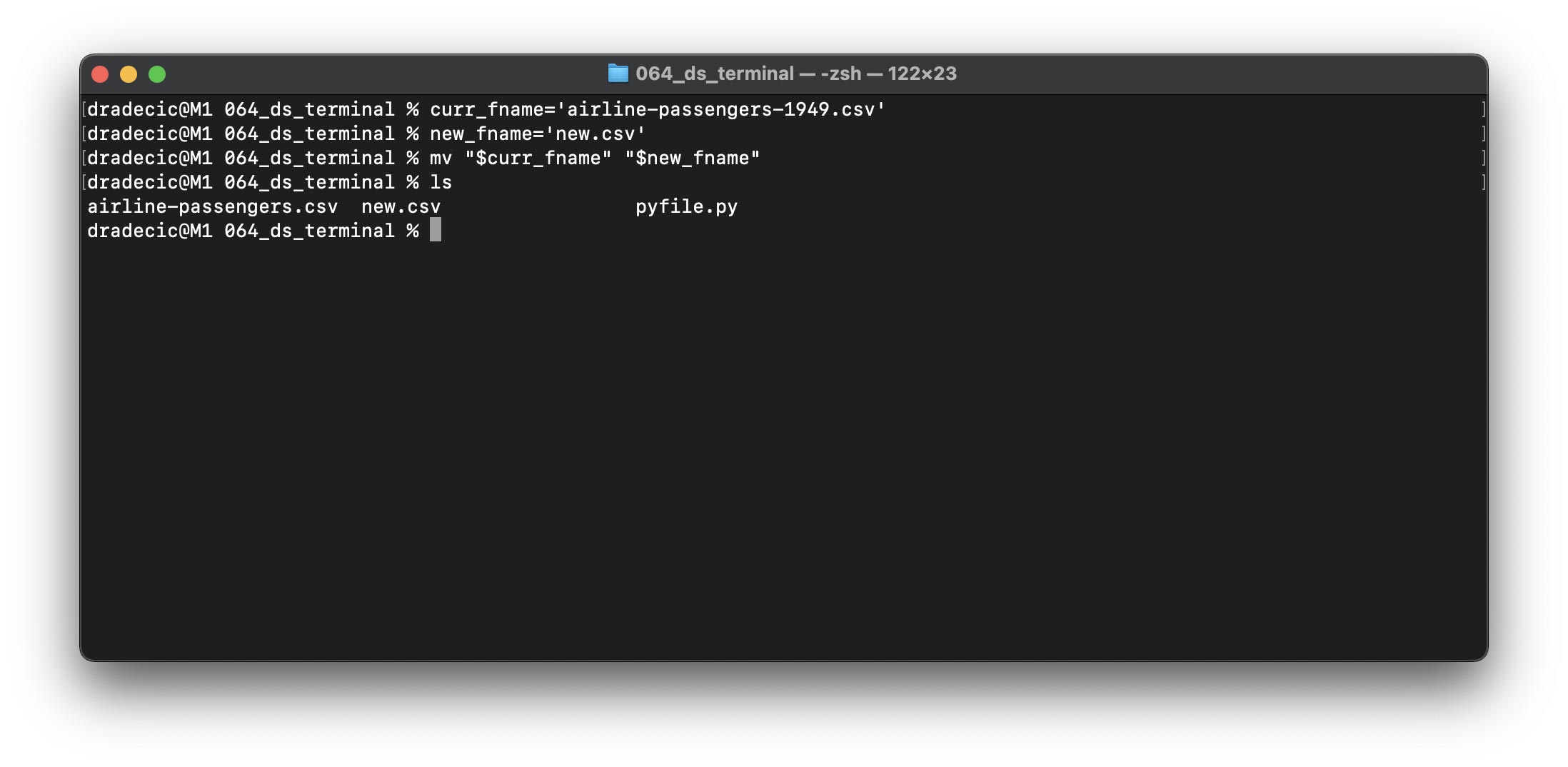
ls命令用于列出目录中的文件,如我们所见,重命名操作成功。
以上就是python学习与数据挖掘应知应会的十大终端命令的详细内容,更多关于python数据挖掘十大终端命令的资料请关注我们其它相关文章!
相关推荐
-
pyhton学习与数据挖掘self原理及应用分析
目录 1. 什么是class,什么是instance,什么是object? 2. 什么是method,什么是function? 3. 重点SELF分析 总结 对,你没看错,这是我初学 python 时的灵魂发问. 我们总会在class里面看见self,但是感觉他好像也没什么用处,就是放在那里占个位子. 如果你也有同样的疑问,那么恭喜你,你的class没学明白. 所以,在解释self是谁之前,我们先明确几个问题: 什么是class,什么是instance? 什么是object? 什么是method
-

python可视化大屏库big_screen示例详解
目录 big_screen 特点 安装环境 输入数据 本地运行 在线部署 对于从事数据领域的小伙伴来说,当需要阐述自己观点.展示项目成果时,我们需要在最短时间内让别人知道你的想法.我相信单调乏味的语言很难让别人快速理解.最直接有效的方式就是将数据如上图所示这样,进行可视化展现. 具体如下: big_screen 特点 便利性工具, 结构简单, 你只需传数据就可以实现数据大屏展示. 安装环境 pip install -i https://pypi.tuna.tsinghua.edu.cn/simp
-
python机器学习使数据更鲜活的可视化工具Pandas_Alive
目录 安装方法 使用说明 支持示例展示 水平条形图 垂直条形图比赛 条形图 饼图 多边形地理空间图 多个图表 总结 数据动画可视化制作在日常工作中是非常实用的一项技能.目前支持动画可视化的库主要以Matplotlib-Animation为主,其特点为:配置复杂,保存动图容易报错. 安装方法 pip install pandas_alive # 或者 conda install pandas_alive -c conda-forge 使用说明 pandas_alive 的设计灵感来自 bar_ch
-
python数据可视化使用pyfinance分析证券收益示例详解
目录 pyfinance简介 pyfinance包含六个模块 returns模块应用实例 收益率计算 CAPM模型相关指标 风险指标 基准比较指标 风险调整收益指标 综合业绩评价指标分析实例 结语 pyfinance简介 在查找如何使用Python实现滚动回归时,发现一个很有用的量化金融包--pyfinance.顾名思义,pyfinance是为投资管理和证券收益分析而构建的Python分析包,主要是对面向定量金融的现有包进行补充,如pyfolio和pandas等. pyfinance包含六个模块
-
python数据挖掘使用Evidently创建机器学习模型仪表板
目录 1.安装包 2.导入所需的库 3.加载数据集 4.创建模型 5.创建仪表板 6.可用报告类型 1)数据漂移 2)数值目标漂移 3)分类目标漂移 4)回归模型性能 5)分类模型性能 6)概率分类模型性能 解释机器学习模型是一个困难的过程,因为通常大多数模型都是一个黑匣子,我们不知道模型内部发生了什么.创建不同类型的可视化有助于理解模型是如何执行的,但是很少有库可以用来解释模型是如何工作的. Evidently 是一个开源 Python 库,用于创建交互式可视化报告.仪表板和 JSON 配置文
-
python数据可视化JupyterLab实用扩展程序Mito
目录 遇见 Mito 如何启动 Mito 数据透视表 Mito 令人印象深刻的功能 可视化数据 自动代码生成 Mito 安装 JupyterLab 是 Jupyter 主打的最新数据科学生产工具,某种意义上,它的出现是为了取代Jupyter Notebook. 它作为一种基于 web 的集成开发环境,你可以使用它编写notebook.操作终端.编辑markdown文本.打开交互模式.查看csv文件及图片等功能. JupyterLab 最棒的体验就是有丰富的扩展插件,我记得过去我们不得不依赖 nu
-
python学习与数据挖掘应知应会的十大终端命令
目录 1.wget 2.head 3.tail 4.wc 5.grep 6.cat 7.find 8.sort 9.nano 10.Variables IT界的每个人都应该知道终端(Terminal)的基本知识,数据科学家也不例外.有时,终端是你的全部,尤其是在将模型和数据管道部署到远程机器时. 让我们开始吧! 1.wget wget实用程序用于从远程服务器下载文件.你可以用它来下载数据集,只要你知道网址,可以使用wget命令下载它,我以如下url为例: https://raw.githubus
-
Python学习笔记之迭代器和生成器用法实例详解
本文实例讲述了Python学习笔记之迭代器和生成器用法.分享给大家供大家参考,具体如下: 迭代器和生成器 迭代器 每次可以返回一个对象元素的对象,例如返回一个列表.我们到目前为止使用的很多内置函数(例如 enumerate)都会返回一个迭代器. 是一种表示数据流的对象.这与列表不同,列表是可迭代对象,但不是迭代器,因为它不是数据流. 生成器 是使用函数创建迭代器的简单方式.也可以使用类定义迭代器 下面是一个叫做 my_range 的生成器函数,它会生成一个从 0 到 (x - 1) 的数字流:
-
Python学习笔记之For循环用法详解
本文实例讲述了Python学习笔记之For循环用法.分享给大家供大家参考,具体如下: Python 中的For循环 Python 有两种类型的循环:for 循环和 while 循环.for 循环用来遍历可迭代对象. 可迭代对象是每次可以返回其中一个元素的对象, 包括字符串.列表和元组等序列类型,以及字典和文件等非序列类型.还可以使用迭代器和生成器定义可迭代对象 For 循环示例: # iterable of cities cities = ['new york city', 'mountain
-
Python学习之循环方法详解
目录 for循环 while循环 拓展:列表推导式 常见的推导式方法 循环的继续与退出(continue与break) continue的使用 break的使用 循环实现九九乘法表 什么是循环? —> 循环是有着周而复始的运动或变化的规律:在 Python 中,循环的操作也叫做 ‘遍历’ . 与现实中一样,Python 中也同样存在着无限循环的 方法与有限循环的方法.接下来我们就先看看有限循环的方法 —> for 循环 for 循环 for 循环的功能:通过 for 关键字将列表.元组.字符串
-
python学习之第三方包安装方法(两种方法)
这篇文章主要介绍了python学习之第三方包安装方法,最近在学习QQ空间.微博(爬虫)模拟登录,都涉及到了RSA算法.这样需要下一个RSA包(第三方包),在网上搜了好多资料,具体有以下两种方法: 第一种方法(不使用pip或者easy_install): Step1:在网上找到的需要的包,下载下来.eg. rsa-3.1.4.tar.gz Step2:解压缩该文件. Step3:命令行工具cd切换到所要安装的包的目录,找到setup.py文件,然后输入python setup.py install
-
python学习 流程控制语句详解
###################### 分支语句 python3.5 ################ #代码的缩进格式很重要 建议4个空格来控制 #根据逻辑值(True,Flase)判断程序的运行方向 # Ture:表示非空的量(String,tuple元组 .list.set.dictonary),所有非零的数字 # False:0,None .空的量 #逻辑表达式 可以包含 逻辑运算符 and or not if: ##################################
-
Python学习资料
官方网站 : www.python.org Python is an interpreted, interactive, object-oriented programming language. It is often compared to Tcl, Perl, Scheme or Java. Python combines remarkable power with very clear syntax. It has modules, classes, exceptions, very h
-
利用Python学习RabbitMQ消息队列
RabbitMQ可以当做一个消息代理,它的核心原理非常简单:即接收和发送消息,可以把它想象成一个邮局:我们把信件放入邮箱,邮递员就会把信件投递到你的收件人处,RabbitMQ就是一个邮箱.邮局.投递员功能综合体,整个过程就是:邮箱接收信件,邮局转发信件,投递员投递信件到达收件人处. RabbitMQ和邮局的主要区别就是RabbitMQ接收.存储和发送的是二进制数据----消息. rabbitmq基本管理命令: 一步启动Erlang node和Rabbit应用:sudo rabbitmq-serv
-
Python学习笔记整理3之输入输出、python eval函数
1. python中的变量: python中的变量声明不需要像C++.Java那样指定变量数据类型(int.float等),因为python会自动地根据赋给变量的值确定其类型.如 radius = 20,area = radius * radius * 3.14159 ,python会自动的将radius看成"整型",area看成"浮点型".所以编程时不用再像之前那样小心翼翼的查看数据类型有没有出错,挺人性化的. 2. input和print: 先贴个小的程序 #