python爬虫之requests库的使用详解
目录
- python爬虫—requests库的用法
- 基本的get请求
- 带参数的GET请求:
- 解析json
- 使用代理
- 获取cookie
- 会话维持
- 证书验证设置
- 超时异常捕获
- 异常处理
- 总结
python爬虫—requests库的用法
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多,requests 允许你发送 HTTP/1.1 请求。指定 URL并添加查询url字符串即可开始爬取网页信息等操作
因为是第三方库,所以使用前需要cmd安装
pip install requests
安装完成后import一下,正常则说明可以开始使用了
基本用法:
requests.get()用于请求目标网站,类型是一个HTTPresponse类型
import requests
response = requests.get('http://www.baidu.com')
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
以打印状态码为例,运行结果:
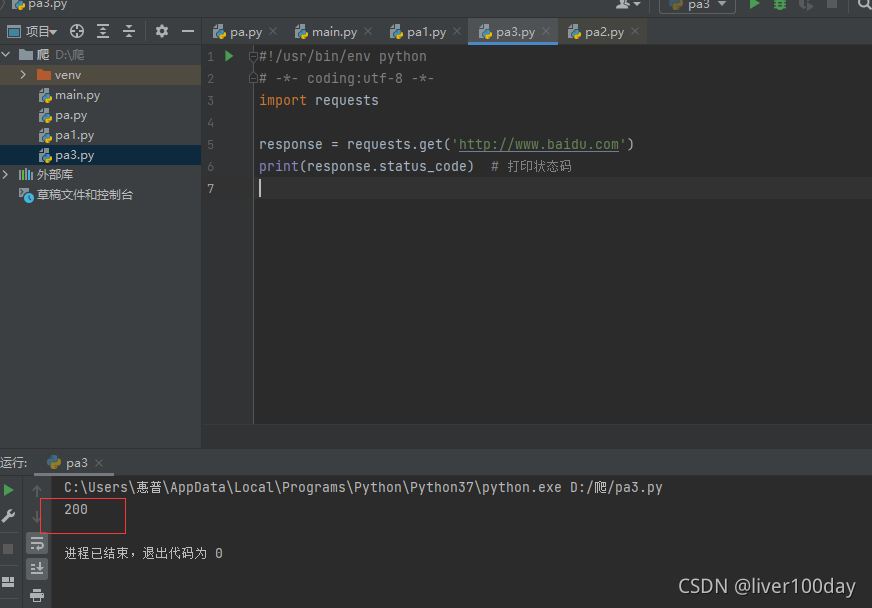
状态码:200,证明请求目标网站正常
若状态码为403一般是目标存有防火墙,触发了反爬策略被限制了IP
各种请求方式:
import requests
requests.get('http://www.baidu.com')
requests.post('http://www.baidu.com')
requests.put('http://www.baidu.com')
requests.delete('http://www.baidu.com')
requests.head('http://www.baidu.com')
requests.options('http://www.baidu.com')
基本的get请求
import requests
response = requests.get('http://www.baidu.com')
print(response.text)
带参数的GET请求:
第一种直接将参数放在url内
import requests
response = requests.get("https://www.crrcgo.cc/admin/crr_supplier.html?params=1")
print(response.text)
另一种先将参数填写在data中,发起请求时将params参数指定为data
import requests
data = {
'params': '1',
}
response = requests.get('https://www.crrcgo.cc/admin/crr_supplier.html?', params=data)
print(response.text)
基本POST请求:
import requests
response = requests.post('http://baidu.com')

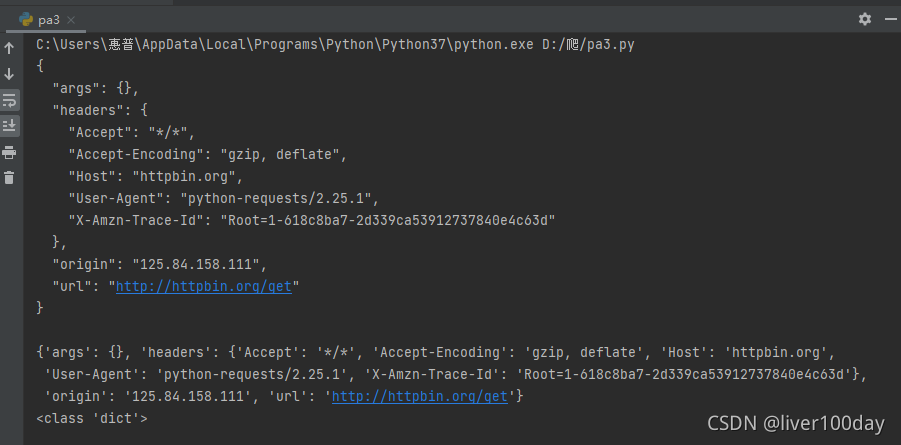
解析json
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
print(response.json()) #response.json()方法同json.loads(response.text)
print(type(response.json()))
简单保存一个二进制文件
import requests
response = requests.get('http://img.ivsky.com/img/tupian/pre/201708/30/kekeersitao-002.jpg')
b = response.content
with open('F://fengjing.jpg','wb') as f:
f.write(b)
为你的请求添加头信息
import requests
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 ' \
'(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 ' \
'(KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get('http://www.baidu.com',headers=headers)
此方法可以有效地避开防火墙的检测,隐藏自己身份
使用代理
同添加headers方法一样,代理参数也是一个dict这里使用requests库爬取了IP代理网站的IP与端口和类型。因为是免费的,使用的代理地址很快就失效了。
复制代码
import requests
import re
def get_html(url):
proxy = {
'http': '120.25.253.234:812',
'https' '163.125.222.244:8123'
}
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
req = requests.get(url, headers=heads,proxies=proxy)
html = req.text
return html
def get_ipport(html):
regex = r'<td data-title="IP">(.+)</td>'
iplist = re.findall(regex, html)
regex2 = '<td data-title="PORT">(.+)</td>'
portlist = re.findall(regex2, html)
regex3 = r'<td data-title="类型">(.+)</td>'
typelist = re.findall(regex3, html)
sumray = []
for i in iplist:
for p in portlist:
for t in typelist:
pass
pass
a = t+','+i + ':' + p
sumray.append(a)
print('高匿代理')
print(sumray)
if __name__ == '__main__':
url = 'http://www.baidu.com'
get_ipport(get_html(url))
获取cookie
import requests
response = requests.get('http://www.baidu.com')
print(response.cookies)
print(type(response.cookies))
for k,v in response.cookies.items():
print(k+':'+v)

会话维持
import requests
session = requests.Session()
session.get('https://www.crrcgo.cc/admin/crr_supplier.html')
response = session.get('https://www.crrcgo.cc/admin/')
print(response.text)
证书验证设置
import requests
from requests.packages import urllib3
urllib3.disable_warnings() #从urllib3中消除警告
response = requests.get('https://www.12306.cn',verify=False) #证书验证设为FALSE
print(response.status_code)
超时异常捕获
import requests
from requests.exceptions import ReadTimeout
try:
res = requests.get('http://httpbin.org', timeout=0.1)
print(res.status_code)
except ReadTimeout:
print(timeout)
异常处理
使用try…except来捕获异常
import requests
from requests.exceptions import ReadTimeout,HTTPError,RequestException
try:
response = requests.get('http://www.baidu.com',timeout=0.5)
print(response.status_code)
except ReadTimeout:
print('timeout')
except HTTPError:
print('httperror')
except RequestException:
print('reqerror')
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
使用requests库制作Python爬虫
使用python爬虫其实就是方便,它会有各种工具类供你来使用,很方便.Java不可以吗?也可以,使用httpclient工具.还有一个大神写的webmagic框架,这些都可以实现爬虫,只不过python集成工具库,使用几行爬取,而Java需要写更多的行来实现,但目的都是一样. 下面介绍requests库简单使用: #!/usr/local/env python # coding:utf-8 import requests #下面开始介绍requests的使用,环境语言是python3,使用下面的
-
python爬虫---requests库的用法详解
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多 因为是第三方库,所以使用前需要cmd安装 pip install requests 安装完成后import一下,正常则说明可以开始使用了. 基本用法: requests.get()用于请求目标网站,类型是一个HTTPresponse类型 import requests response = requests.get('http://www.baidu.com')print(response.status_c
-

python中数据爬虫requests库使用方法详解
一.什么是Requests Requests 是Python语编写,基于urllib,采Apache2 Licensed开源协议的 HTTP 库.它urllib 更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 一句话--requests是python实现的简单易用的HTTP库 二.安装Requests库 进入命令行win+R执行 命令:pip install requests 项目导入:import requests 三.各种请求方式 直接上代码,不明白可以查看我的urllib的基
-
Python爬虫requests库多种用法实例
requests安装和使用 下载安装:pip install requests #requests模块 import requests #发送请求 content:以二进制的形式获取网页的内容 response=requests.get("http://www.baidu.com").content.decode() #response=requests.request("get","http://www.baidu.com").content.
-
python爬虫基础教程:requests库(二)代码实例
get请求 简单使用 import requests ''' 想要学习Python?Python学习交流群:973783996满足你的需求,资料都已经上传群文件,可以自行下载! ''' response = requests.get("https://www.baidu.com/") #text返回的是unicode的字符串,可能会出现乱码情况 # print(response.text) #content返回的是字节,需要解码 print(response.content.decod
-
python爬虫利器之requests库的用法(超全面的爬取网页案例)
requests库 利用pip安装: pip install requests 基本请求 req = requests.get("https://www.baidu.com/") req = requests.post("https://www.baidu.com/") req = requests.put("https://www.baidu.com/") req = requests.delete("https://www.baid
-
python爬虫之requests库的使用详解
目录 python爬虫-requests库的用法 基本的get请求 带参数的GET请求: 解析json 使用代理 获取cookie 会话维持 证书验证设置 超时异常捕获 异常处理 总结 python爬虫-requests库的用法 requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多,requests 允许你发送 HTTP/1.1 请求.指定 URL并添加查询url字符串即可开始爬取网页信息等操作 因为是第三方库,所以使用前需要cmd安装 pip install
-
Python 网页请求之requests库的使用详解
目录 1.requests库简介 2.requests库方法介绍 3.代码实例 1.requests库简介 requests 是 Python 中比较常用的网页请求库,主要用来发送 HTTP 请求,在使用爬虫或测试服务器响应数据时经常会用到,使用起来十分简洁. requests 为第三方库,需要我们通过pip命令安装: pip install requests 2.requests库方法介绍 下表列出了requests库中的各种请求方法: 方法 描述 delete(url, args) 发送 D
-
Python爬虫之requests库基本介绍
目录 一.说明 二.基本用法: 总结 一.说明 requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,requests是Python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib简洁很多. Requests 有这些功能: 1.Keep-Alive & 连接池2.国际化域名和 URL3.带持久 Cookie 的会话4.浏览器式的 SSL 认证5.自动内容解码6.基本/摘要式的身份认证7.优雅的 key/value Cookie8.自
-
python爬虫之BeautifulSoup 使用select方法详解
本文介绍了python爬虫之BeautifulSoup 使用select方法详解 ,分享给大家.具体如下: <html><head><title>The Dormouse's story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse's story</b></
-
Python数据分析之Numpy库的使用详解
目录 前言
-
python可视化大屏库big_screen示例详解
目录 big_screen 特点 安装环境 输入数据 本地运行 在线部署 对于从事数据领域的小伙伴来说,当需要阐述自己观点.展示项目成果时,我们需要在最短时间内让别人知道你的想法.我相信单调乏味的语言很难让别人快速理解.最直接有效的方式就是将数据如上图所示这样,进行可视化展现. 具体如下: big_screen 特点 便利性工具, 结构简单, 你只需传数据就可以实现数据大屏展示. 安装环境 pip install -i https://pypi.tuna.tsinghua.edu.cn/simp
-
Python中的tkinter库简单案例详解
目录 案例一 Label & Button 标签和按钮 案例二 Entry & Text 输入和文本框 案例三 Listbox 部件 案例四 Radiobutton 选择按钮 案例五 Scale 尺度 案例六 Checkbutton 勾选项 案例七 Canvas 画布 案例八 Menubar 菜单 案例九 Frame 框架 案例十 messagebox 弹窗 案例十一 pack grid place 放置 登录窗口 TKinterPython 的 GUI 库非常多,之所以选择 Tkinte
-
python进阶collections标准库使用示例详解
目录 前言 namedtuple namedtuple的由来 namedtuple的格式 namedtuple声明以及实例化 namedtuple的方法和属性 OrderedDict popitem(last=True) move_to_end(key, last=True) 支持reversed 相等测试敏感 defaultdict 小例子1 小例子2 小例子3 Counter对象 创建方式 elements() most_common([n]) 应用场景 deque([iterable[,
-
Python中requests库的学习方法详解
目录 前言 一 URL,URI和URN 1. URL,URI和URN 2. URL的组成 二 请求组成 1. 请求方法 2. 请求网址 3. 请求头 4. 请求体 三 请求 1. get请求 2. get带请求头headers参数 3. post请求 四 响应 1. 响应状态码 2. 响应头 3. 响应体 总结 前言 好记性不如烂笔头!最近在接口测试,以及爬虫相关,需要用到Python中的requests库,之前用过,但是好久没有用又忘了,这次就把这块的简单整理下(个人笔记使用) 一 URL,U