C++基础算法基于哈希表的索引堆变形
目录
- 问题来源
- 问题简述
- 问题分析
- 代码展示
问题来源
此题来自于Hackerrank中的QHEAP1问题,考查了对堆结构的充分理解。成功完成此题,对最大堆或者最小堆的基本操作实现就没什么太大问题了。
问题简述
实现一个最小堆,对3种类型的输入能给出正确的操作:
- “1 v” - 表示往堆中增加一个值为v的元素
- “2 v” - 表示删去堆中值为v的元素
- “3” - 表示打印出堆中最小的那个元素
注意:题目保证了要删的元素必然是在堆中的,并且在任何时刻,堆中不会有重复的元素。
输入格式:
第1行的值表示共有q个操作,然后再接下来的q行中,每行都有上述3中操作中的任意一种。
比如:
******************输入*******************
5
1 4
1 9
3
2 4
3
******************输出*******************
4
9
问题分析
对于一个最小堆来说,其满足的性质是只要每个子树中的父亲节点的元素小于其左孩子节点和右孩子节点的元素即可,比如下图所示的这样:

图1:最小堆示例图
没错,最小堆根部的元素必然是树中最小的那个元素。除了满足上述的条件之外,最小堆还必须是一颗完全二叉树。也正是由于这个完全二叉树的性质,最小堆是可以用数组来实现的,比如上图的这个最小堆就可以表示成
data = { 5, 8, 20, 10, 35, 12, 50, 15, 16 };
从树结构中不难看出索引之间有关系
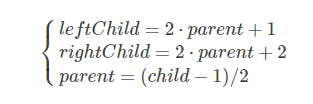
这是我们在更新堆信息时最重要的公式,第3个式子的除法是取整的,所以左右孩子都一样。
如果只需要满足操作”1 v”和操作”3”的话,上述这些就已经完全够用了,难点在于这里需要我们对堆中指定的元素进行删除”2 v”。讲道理,这并不是一个最小堆所应该有的操作,最小堆只要管住最小的那个值就好了,其他的结构怎么样,最小堆并不关心。不过,既然题目故意这么出了,要来刁难我们,我们也只能迎难而上了。
借助于索引堆的想法,我们用一个哈希表来记录每一个元素在堆中的索引位置,这样,我们在删除时只需要 O(1) 的复杂度就可以找到要删除的元素了,而删除的过程是 O(log(n)) 的复杂度。
还是以上面那组数据为例,我们希望记录的是如下的信息。
data = { 5, 8, 20, 10, 35, 12, 50, 15, 16 };
mp = {{20, 2}, {35, 4}, {8, 1}, {5, 0}, {16, 8}, {50, 6}, {12, 5}, {10, 3}, {15, 7}};
哈希表中元素的顺序完全无所谓,只要元素中的对应关系正确即可,所以上面的这个是我乱编的,具体的顺序和插入元素的顺序有关系。
代码展示
最后,来展示一下完整的代码,把下面这个代码直接复制粘贴到题目中去Submit是没问题的。
#include <vector>
#include <iostream>
#include <unordered_map>
using namespace std;
class myHeap{
private:
//作为堆的数组
vector<int> data;
//用于存放<元素值,在堆中的索引>的哈希表
unordered_map<int, int> mp;
//堆中元素的个数
int size;
private:
//上移操作,将元素小的顺着树结构往上移
void _shiftUp(int index){
if (index >= size || index < 0)
return;
while (index != 0){
int newIndex = (index - 1) / 2;
if (data[newIndex] > data[index]){
//更新哈希表中存放的索引
mp[data[newIndex]] = index;
mp[data[index]] = newIndex;
//更新堆中元素的位置
swap(data[newIndex], data[index]);
index = newIndex;
}
else
break;
}
return;
}
//下移操作,将元素大的顺着树结构往下移
void _shiftDown(int index){
if (index >= size || index < 0)
return;
while (index * 2 + 1 < size){
int newIndex = index * 2 + 1;
//选择左节点和右节点中比较小的那个元素
if (newIndex + 1 < size && data[newIndex + 1] < data[newIndex])
newIndex++;
if (data[newIndex] > data[index])
break;
//更新哈希表中存放的索引
mp[data[newIndex]] = index;
mp[data[index]] = newIndex;
//更新堆中元素的位置
swap(data[newIndex], data[index]);
index = newIndex;
}
return;
}
public:
myHeap(){
size = 0;
}
//添加元素
void add(int d){
data.push_back(d);
mp[d] = size++;
_shiftUp(mp[d]);
}
//删除元素
void del(int d){
int index = mp[d];
mp[d] = size - 1;
mp[data[size - 1]] = index;
swap(data[index], data[size - 1]);
size--;
data.pop_back();
_shiftUp(index);
_shiftDown(index);
mp.erase(d);
}
//打印堆中最小值
void showMin(){
cout << data[0] << endl;
}
};
int main() {
/* Enter your code here. Read input from STDIN. Print output to STDOUT */
int q;
cin >> q;
myHeap h;
for (int i = 0; i < q; i++){
int index;
cin >> index;
if (index == 1){
int v;
cin >> v;
h.add(v);
}
else if (index == 2){
int v;
cin >> v;
h.del(v);
}
else if (index == 3){
h.showMin();
}
}
}
如有不足,还请指正~
以上就是C++基础算法基于哈希表的索引堆变形的详细内容,更多关于C++算法哈希表索引堆变形的资料请关注我们其它相关文章!
相关推荐
-

简单讲解哈希表
目录 一.哈希表的概念 1.查找算法 2.哈希表 3.哈希数组 4.关键字 5.哈希函数 6.哈希冲突 7.哈希地址 二.常用哈希函数 1.直接定址法 2.平方取中法 3.折叠法 4.除留余数法 5.位与法 三.常见哈希冲突解决方案 1.开放定址法 1)原理讲解 2)动画演示 2.再散列函数法 1)原理讲解 2)动画演示 3.链地址法 1)原理讲解 2)动画演示 4.公共溢出区法 1)原理讲解 2)动画演示 四.哈希表的实现 1.数据结构定义 2.哈希表初始化 3.哈希函数计算 4.哈希表查找
-
C语言基于哈希表实现通讯录
本文为大家分享了C语言基于哈希表实现通讯录的具体代码,供大家参考,具体内容如下 1.需求分析 本演示程序用C语言编写,完成哈希表的生成,电话号码的插入.以及查找等功能. (1)按提示输入相应的联系人的相关资料: (2)以相应的输出形式输出所存储的的联系人的资料: (3)程序可以达到建立.添加.查找.打印的功能: (4)程序可以判断用户输入的非法数据并引导正确的输入. 2.概要设计 存储电话号码的记录时,若在存储位置和其关键字之间建立某种确定的对应关系使得每个关键字和存储结构中一个唯一的存储位置相
-
C++语言实现hash表详解及实例代码
C++语言实现hash表详解 概要: hash表,有时候也被称为散列表.个人认为,hash表是介于链表和二叉树之间的一种中间结构.链表使用十分方便,但是数据查找十分麻烦:二叉树中的数据严格有序,但是这是以多一个指针作为代价的结果.hash表既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便. 打个比方来说,所有的数据就好像许许多多的书本.如果这些书本是一本一本堆起来的,就好像链表或者线性表一样,整个数据会显得非常的无序和凌乱,在你找到自己需要的书之前,你要经历许多的查询过程:而如果
-
C++ 实现哈希表的实例
C++ 实现哈希表的实例 该散列表的散列函数采用了除法散列函数.乘法散列函数.全域散列函数,每一个槽都是使用有序单向链表实现. 实现代码: LinkNode.h #include<iostream> using namespace std; class Link; class LinkNode { private: int key; LinkNode* next; friend Link; public: LinkNode():key(-1),next(NULL){} LinkNode(int
-
C++基础算法基于哈希表的索引堆变形
目录 问题来源 问题简述 问题分析 代码展示 问题来源 此题来自于Hackerrank中的QHEAP1问题,考查了对堆结构的充分理解.成功完成此题,对最大堆或者最小堆的基本操作实现就没什么太大问题了. 问题简述 实现一个最小堆,对3种类型的输入能给出正确的操作: "1 v" - 表示往堆中增加一个值为v的元素 "2 v" - 表示删去堆中值为v的元素 "3" - 表示打印出堆中最小的那个元素 注意:题目保证了要删的元素必然是在堆中的,并且在任何时
-
java数据结构和算法中哈希表知识点详解
树的结构说得差不多了,现在我们来说说一种数据结构叫做哈希表(hash table),哈希表有是干什么用的呢?我们知道树的操作的时间复杂度通常为O(logN),那有没有更快的数据结构?当然有,那就是哈希表: 1.哈希表简介 哈希表(hash table)是一种数据结构,提供很快速的插入和查找操作(有的时候甚至删除操作也是),时间复杂度为O(1),对比时间复杂度就可以知道哈希表比树的效率快得多,并且哈希表的实现也相对容易,然而没有任何一种数据结构是完美的,哈希表也是:哈希表最大的缺陷就是基于数组,因
-
带你了解Java数据结构和算法之哈希表
目录 1.哈希函数的引入 ①.把数字相加 ②.幂的连乘 2.冲突 3.开放地址法 ①.线性探测 ②.装填因子 ③.二次探测 ④.再哈希法 4.链地址法 5.桶 6.总结 1.哈希函数的引入 大家都用过字典,字典的优点是我们可以通过前面的目录快速定位到所要查找的单词.如果我们想把一本英文字典的每个单词,从 a 到 zyzzyva(这是牛津字典的最后一个单词),都写入计算机内存,以便快速读写,那么哈希表是个不错的选择. 这里我们将范围缩小点,比如想在内存中存储5000个英文单词.我们可能想到每个单词
-
php内核解析:PHP中的哈希表
PHP中使用最为频繁的数据类型非字符串和数组莫属,PHP比较容易上手也得益于非常灵活的数组类型. 在开始详细介绍这些数据类型之前有必要介绍一下哈希表(HashTable). 哈希表是PHP实现中尤为关键的数据结构. 哈希表在实践中使用的非常广泛,例如编译器通常会维护的一个符号表来保存标记,很多高级语言中也显式的支持哈希表. 哈希表通常提供查找(Search),插入(Insert),删除(Delete)等操作,这些操作在最坏的情况下和链表的性能一样为O(n). 不过通常并不会这么坏,合理设计的哈希
-
C++ 哈希表的基本用法及说明
目录 C++ 哈希表基本用法 为什么要用哈希表 遍历 查找 插入 删除 C++ 哈希表基础知识 常见的三种哈希结构 C++ 哈希表基本用法 哈希表是一种很常见的数据结构,我现在平时刷算法题一般使用C++刷(不要问我为什么,懂的都懂).C++关于哈希表有很多数据结构,平时使用的比较多的有unordered_set 跟 unordered_map.其中unordered_map 存储的是键值对. 其实我们在某些情况下可以使用数组构建哈希表(具体是哪些情况的呢,自行搜索).但是数组的大小是受限制的,而
-
PHP内核探索:哈希表碰撞攻击原理
下面通过图文并茂的方式给大家展示PHP内核探索:哈希表碰撞攻击原理. 最近哈希表碰撞攻击(Hashtable collisions as DOS attack)的话题不断被提起,各种语言纷纷中招.本文结合PHP内核源码,聊一聊这种攻击的原理及实现. 哈希表碰撞攻击的基本原理 哈希表是一种查找效率极高的数据结构,很多语言都在内部实现了哈希表.PHP中的哈希表是一种极为重要的数据结构,不但用于表示Array数据类型,还在Zend虚拟机内部用于存储上下文环境信息(执行上下文的变量及函数均使用哈希表结
-
TypeScript 基础数据结构哈希表 HashTable教程
目录 前言 1. 哈希表介绍和特性 2. 哈希表的一些概念 3. 地址冲突解决方案 3.1 方案一:链地址法 3.2 方案二:开放地址法 4. 哈希函数代码实现 5. 哈希表封装 5.1 整体框架 v1 版 5.2 添加 put 方法 v2 版 5.3 添加 get 方法 v3 版 5.4 添加 delete 方法 v4 版 6. 哈希表的自动扩容 前言 哈希表是一种 非常重要的数据结构,几乎所有的编程语言都有 直接或者间接 的应用这种数据结构. 很多学习编程的人一直搞不懂哈希表到底是如何实现的
-
详解JavaScript实现哈希表
目录 一.哈希表原理 二.哈希表的概念 三.哈希化冲突问题 1.链地址法 2.开放地址法 四.哈希函数的实现 五.封装哈希表 六.哈希表操作 1.插入&修改操作 2.获取操作 3.删除操作 4.判断哈希表是否为空 5.获取哈希表的元素个数 七.哈希表扩容 1.哈希表扩容思想 2.哈希表扩容实现 八.完整代码 一.哈希表原理 哈希表是一种非常重要的数据结构,几乎所有的编程语言都有直接或者间接的应用这种数据结构,它通常是基于数组实现的,当时相对于数组,它有更多的优势: 它可以提供非常快速的插入-删
-
JAVA中哈希表HashMap的深入学习
深入浅出学Java--HashMap 哈希表(hash table) 也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,本文会对java集合框架中HashMap的实现原理进行讲解,并对JDK7的HashMap源码进行分析. 一.什么是哈希表 在讨论哈希表之前,我们先大概了解下其他数据结构在新增,查找等基础操作执行性能 数组:采用一段连续的存储单元来存储数据.对于指定下标的查找,时间复杂度为O(1):通过给定值进