SpringBoot使用前缀树过滤敏感词的方法实例
目录
- 一、前缀树
- 二、敏感词过滤器
- 总结
一、前缀树
一般设计网站的时候,会有问题发布或者是内容发布的功能,这些功能的有一个很重要的点在于如何实现敏感词过滤,要不然可能会有不良信息的发布,或者发布的内容中有夹杂可能会有恶意功能的代码片段,敏感词过滤的基本的算法是前缀树算法,前缀树也就是字典树,通过前缀树匹配可以加快敏感词匹配的速度。
前缀树又称为Trie、字典树、查找树。主要特点是:查找效率高,但内存消耗大;主要应用于字符串检索、词频统计、字符串排序等。
到底什么是前缀树?前缀树的功能是如何实现的?
举一个具体的例子:若有一个字符串"xwabfabcff",敏感词为"abc"、"bf"、"be",检测字符串,若有敏感词,则将敏感词替换为"*",实现一个算法。
前缀树的特点:
1. 跟结点为空结点,没有任何字符。
2. 除了根节点以外,每个结点只有一个字符。
3. 每个结点包含的子节点不相同。 例如,root的子节点本来有两个b,但我们只保留一个
4. 在每个敏感词的末尾结点做一个标记,表示从根节点到此节点组合成的字符串是一个敏感词,中间未被标记的结点和根节点中间的字符串不构成一个敏感词。

前缀树的算法逻辑:
1. 准备:我们需要三个指针,①指针指向前缀树,默认指向根节点; ②、③指针指向要检测的字符串(同向尺距法,②从头到尾走一遍,标记敏感词的开头,③随着②而动,标记敏感词的结尾),默认指向字符串的第一个字符。我们还需要一个存放检测结果的字符串(StringBuilder)。
2. ①访问树的第一层,发现没有'x',则②、③向下走一步,并将'x'存入StringBuilder字符串里。'w' 同理。
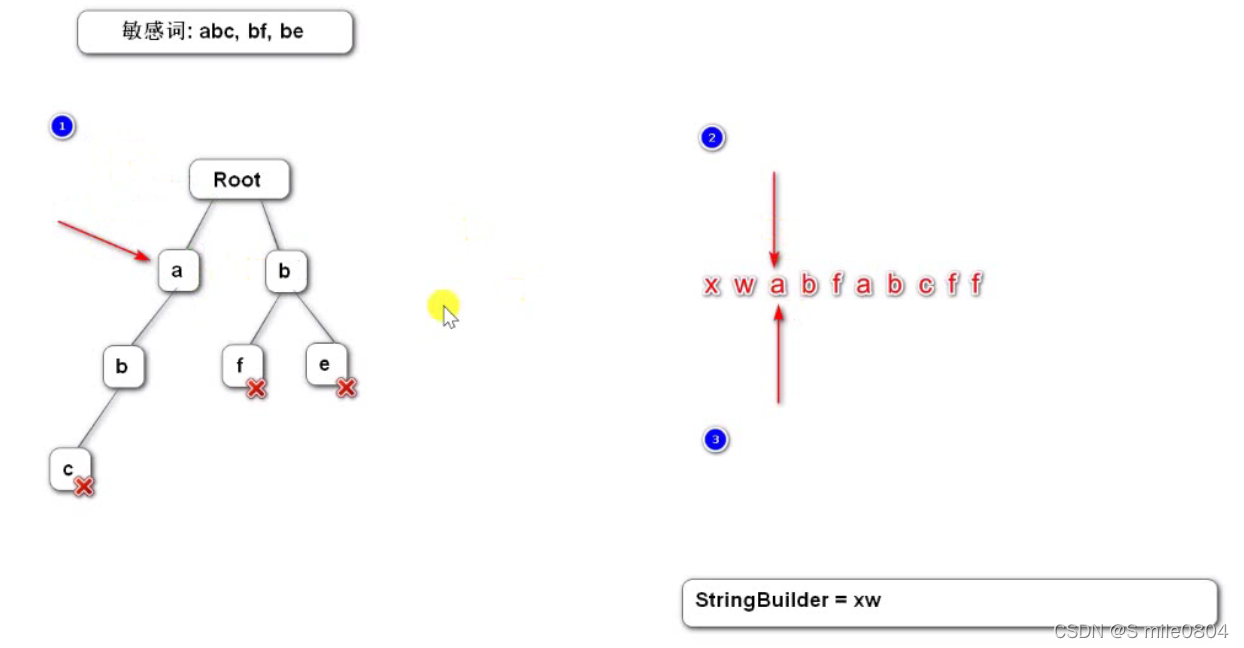
3. 此时②、③指向'a',①访问树的第一层,发现有'a',但'a'未被标记,所以不是敏感词,则把'a'存入StringBuilder字符串。然后②不动,①、③继续向下走,直至走到被标记的结点或者不匹配时,①归位,②向下走一步,③回到此时②指向的地方。重复以上步骤。
4. 若检测到敏感词,则在StringBuilder中存储"***",并使②跳过此敏感词,②、③共同指向原来③的下一个位置。

5. ②、③走到字符串的末尾时,检测完成。最终结果为"xwa******ff"。
二、敏感词过滤器
我们再开发项目时,需要开发出一个可复用的过滤敏感词的工具,成为敏感词过滤器,以便在项目中可以复用。
开发敏感词过滤器主要有以下三个步骤:
1. 定义前缀树
2. 根据敏感词,初始化前缀树
3. 编写过滤敏感词的方法
代码实现如下:
import org.apache.commons.lang3.CharUtils;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
@Component
public class SensitiveFilter {
// 记录日志
private static final Logger logger = LoggerFactory.getLogger(SensitiveFilter.class);
// 替换符
private static final String REPLACEMENT = "***";
// 初始化根节点
private TrieNode rootNode = new TrieNode();
/**
* 2. 根据敏感词,初始化前缀树
*/
@PostConstruct// 当容器在服务器启动时实例化此Bean,调用Bean的构造方法后,该方法就会被自动调用
public void init() {
try (
// 加载敏感词文件 sensitive-words.txt是自建的存放敏感词的文件
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
// 字节流 --> 字符流 --> 字符缓冲流
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
) {
String keyword;
while((keyword = reader.readLine()) != null){
// 添加到前缀树,addKeyword为自定义的方法,将一个敏感词添加到前缀树中去
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败:" + e.getMessage());
}
}
// 封装方法:将一个敏感词添加到前缀树中去
private void addKeyword(String keyword){
TrieNode tempNode = rootNode;
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if(subNode == null){
// 如果子节点中没有该字符,则以此字符初始化子节点,并装配到树中
subNode = new TrieNode();
tempNode.addSubNode(c,subNode);
}
// 指向字节点,进入下一层循环
tempNode = subNode;
// 设置结束标识
if(i == keyword.length() -1){
tempNode.setKeywordEnd(true);
}
}
}
/**
* 3. 检索并过滤敏感词
* @param text 待过滤的文本
* @return 过滤后的文本
*/
public String filter(String text){
if(StringUtils.isBlank(text)){
return null;
}
// 指针①
TrieNode tempNode = rootNode;
// 指针②
int begin = 0;
// 指针③
int position = 0;
// 存放结果
StringBuilder sb = new StringBuilder();
while(position < text.length()){
char c = text.charAt(position);
// 跳过符号
if(isSymbol(c)){
// 若指针①处于根节点,将此符号计入结果,让指针②向下走一步
if(tempNode == rootNode){
sb.append(c);
begin++;
}
// 无论符号在未检测时出现还是正在检测时出现,指针③总是向下走一步
// (未检测时和指针②一起向下走一步,检测时指针②不动,指针③向下走一步)
position++;
continue;
}
// 检查下级节点
tempNode = tempNode.getSubNode(c);
if(tempNode == null){
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
// 进入下一个位置
begin++;
position = begin;
// 指针①归位,重新指向根节点
tempNode = rootNode;
}else if (tempNode.isKeywordEnd()){
// 发现敏感词,将begin~position字符串替换掉
sb.append(REPLACEMENT);
// 进入下一个位置
position++;
begin = position;
// 指针①归位,重新指向跟接待你
tempNode = rootNode;
}else {
// 检查下一个字符
position++;
}
}
// 将最后一批字符计入结果:指针③比指针②先到中终点,且两者之间的字符串不是敏感词
sb.append(text.substring(begin));
return sb.toString();
}
// 封装方法:判断是否为特殊符号
private boolean isSymbol(Character c){
// 0x2E80~0x9FFF 是东亚文字范围,不予当作特殊符号看待
return !CharUtils.isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF);
}
/**
* 1. 定义前缀树
*/
private class TrieNode {
// 敏感词(关键词)结束标识
private boolean isKeywordEnd = false;
// 子节点(key是下级字符,value是下级节点)
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
// 添加子节点
public void addSubNode(Character c, TrieNode node) {
subNodes.put(c, node);
}
// 获取子节点
public TrieNode getSubNode(Character c) {
return subNodes.get(c);
}
}
}
总结
到此这篇关于SpringBoot使用前缀树过滤敏感词的文章就介绍到这了,更多相关SpringBoot用前缀树过滤敏感词内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Spring Boot 实现敏感词及特殊字符过滤处理
背景: 技术采用的是 Spring Boot ,请求方法主要为 POST, 请求使用较多的注解为 @RequestBody 交付测试人员进行测试,测试人员在对模糊搜索模块进行了各种特殊字符的搜索,以至于敏感词和特殊字符均会入库. 对于我这样有情怀的开发者而言,是不能容忍的. 上来就是干!主要采用 @ControllerAdvice(basePackages = "com.my") 的方式,对用户提交的数据做处理. 以下是示例代码,不影响笔者要言表的功能实现: /** * @author
-

SpringBoot使用前缀树过滤敏感词的方法实例
目录 一.前缀树 二.敏感词过滤器 总结 一.前缀树 一般设计网站的时候,会有问题发布或者是内容发布的功能,这些功能的有一个很重要的点在于如何实现敏感词过滤,要不然可能会有不良信息的发布,或者发布的内容中有夹杂可能会有恶意功能的代码片段,敏感词过滤的基本的算法是前缀树算法,前缀树也就是字典树,通过前缀树匹配可以加快敏感词匹配的速度. 前缀树又称为Trie.字典树.查找树.主要特点是:查找效率高,但内存消耗大:主要应用于字符串检索.词频统计.字符串排序等. 到底什么是前缀树?前缀树的功能是如何实现
-
Go 语言前缀树实现敏感词检测
目录 一.前言 二.敏感词检测 暴力匹配 正则匹配 三.Go 语言实现敏感词前缀树 前缀树结构 添加敏感词 匹配敏感词 过滤特殊字符 添加拼音检测 四.源代码 一.前言 大家都知道游戏文字.文章等一些风控场景都实现了敏感词检测,一些敏感词会被屏蔽掉或者文章无法发布.今天我就分享用Go实现敏感词前缀树来达到文本的敏感词检测,让我们一探究竟! 二.敏感词检测 实现敏感词检测都很多种方法,例如暴力.正则.前缀树等.例如一个游戏的文字交流的场景,敏感词会被和谐成 * ,该如何实现呢?首先我们先准备一些敏
-
利用Python正则表达式过滤敏感词的方法
问题描述:很多网站会对用户发帖内容进行一定的检查,并自动把敏感词修改为特定的字符. 技术要点: 1)Python正则表达式模块re的sub()函数: 2)在正则表达式语法中,竖线"|"表示二选一或多选一. 参考代码: 以上这篇利用Python正则表达式过滤敏感词的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
SpringBoot实现过滤敏感词的示例代码
过滤敏感词 1. 创建一个储存要过滤的敏感词的文本文件 首先创建一个文本文件储存要过滤的敏感词 在下面的工具类中我们会读取这个文本文件,这里提前给出 @PostConstruct // 这个注解表示当容器实例化这个bean(服务启动的时候)之后在调用构造器之后这个方法会自动的调用 public void init(){ try( // 读取写有"敏感词"的文件,getClass表示从程序编译之后的target/classes读配置文件,读之后是字节流 // java7语法,在这里的句子
-
JAVA使用前缀树(Tire树)实现敏感词过滤、词典搜索
目录 简介 Trie树 code 结论 简介 有时候需要对用户输入的内容进行敏感词过滤,或者实现查找文本中出现的词典中的词,用遍历的方式进行替换或者查找效率非常低,这里提供一个基于Trie树的方式,进行关键词的查找与过滤,在词典比较大的情况下效率非常高. Trie树 Trie树,又叫前缀树,多说无益,直接看图就明白了 词典:[“猪狗”, “小狗”, “小猫”, “小猪”, “垃圾”, “狗东西”] Tire数据结构: code 树节点Node.class /** * trie tree * *
-
python实现过滤敏感词
简述: 关于敏感词过滤可以看成是一种文本反垃圾算法,例如 题目:敏感词文本文件 filtered_words.txt,当用户输入敏感词语,则用 星号 * 替换,例如当用户输入「北京是个好城市」,则变成「**是个好城市」 代码: #coding=utf-8 def filterwords(x): with open(x,'r') as f: text=f.read() print text.split('\n') userinput=raw_input('myinput:') for i in
-
jQuery中DOM树操作之使用反向插入方法实例分析
本文实例讲述了jQuery中DOM树操作之使用反向插入方法.分享给大家供大家参考.具体分析如下: 使用反向插入方法 这里我们先把创建的内容插人到元素前面,然后再把同一个元素插人到文档 中的另一个位置.通常,当在jQuery中操作元素时,利用连缀方法更简洁也更有效.可是我们现在没有办法这样做,因为this是.insertBefore()的目标,是.appendTo()的内容.此时,利 用反向插入方法,可以帮我们解决问题. 像.insertBefore()和.appendTo()这样的插人方法,一般
-
SpringBoot启动执行sql脚本的3种方法实例
目录 背景 配置application.yml文件 自定义DataSourceInitializer Bean 启动时执行方法 Springboot自动执行sql文件 总结 背景 项目里后端需要计算坐标距离,想用sql实现算法,然后通过执行一个sql脚本,创建一个函数供各业务调用.我们需要在springboot项目启动时执行sql脚本,在网上一顿搜索,总结了有三种做法: 配置application.yml文件 自定义DataSourceInitializer Bean 启动时执行方法 第一种做法
-
php过滤敏感词的示例
复制代码 代码如下: $badword = array( '张三','张三丰','张三丰田');$badword1 = array_combine($badword,array_fill(0,count($badword),'*'));$bb = '我今天开着张三丰田上班';$str = strtr($bb, $badword1);echo $str; 复制代码 代码如下: $hei=array('中国','日本');$blacklist="/".implode("|&
-
SpringBoot @Validated注解实现参数分组校验的方法实例
前言 在前后端分离开发的时候我们需要用到参数校验,前端需要进行参数校验,后端接口同样的也需要,以防传入不合法的数据. 1.首先还是先导包,导入pom文件. <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-validation</artifactId> </dependency> 2.解释一下注解的作用 @N