利用python实现简单的情感分析实例教程
目录
- 1 数据导入及预处理
- 1.1 数据导入
- 1.2 数据描述
- 1.3 数据预处理
- 2 情感分析
- 2.1 情感分
- 2.2 情感分直方图
- 2.3 词云图
- 2.4 关键词提取
- 3 积极评论与消极评论
- 3.1 积极评论与消极评论占比
- 3.2 消极评论分析
- 总结
python实现简单的情感分析
1 数据导入及预处理
1.1 数据导入
# 数据导入
import pandas as pd
data = pd.read_csv('../data/京东评论数据.csv')
data.head()

1.2 数据描述
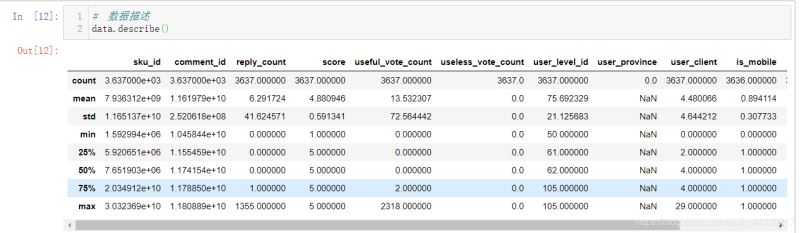
# 数据描述 data.describe()
1.3 数据预处理
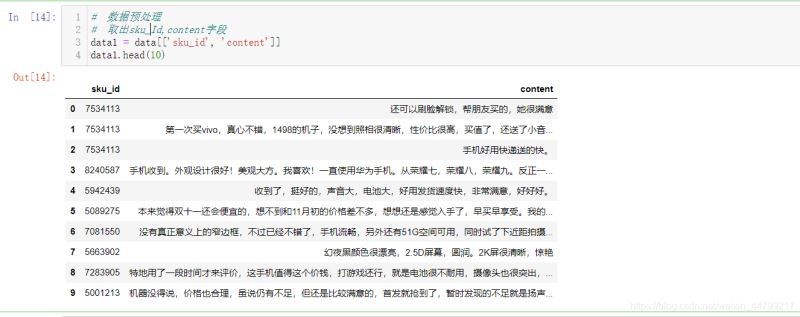
# 数据预处理 # 取出sku_Id,content字段 data1 = data[['sku_id', 'content']] data1.head(10)
2 情感分析
2.1 情感分
# 情感分析 from snownlp import SnowNLP data1['emotion'] = data1['content'].apply(lambda x: SnowNLP(x).sentiments) data1.head()

# 情感数据描述 data1.describe()
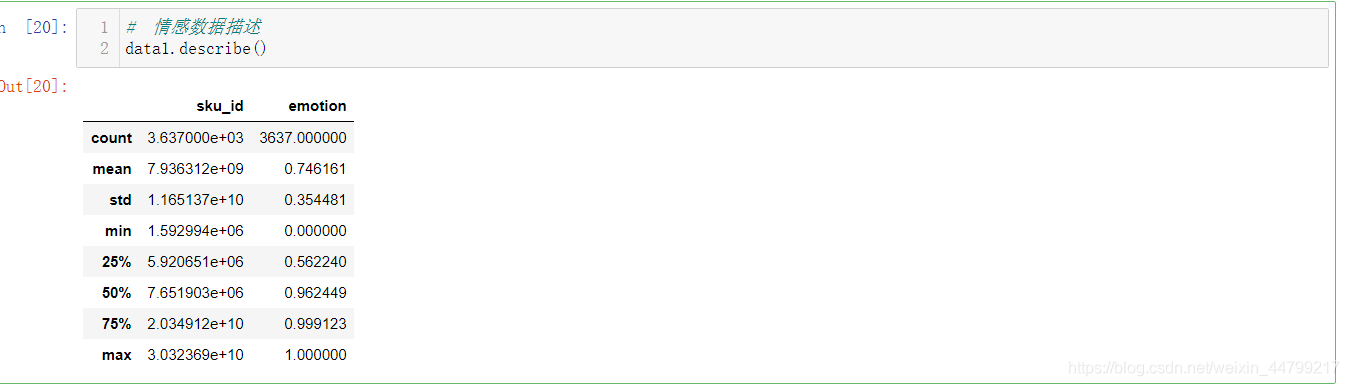
emotion平均值为0.74,中位数为0.96,25%分位数为0.56,可见不到25%的数据造成了整体均值的较大下移。
2.2 情感分直方图
# 绘制情感分直方图
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
bins = np.arange(0, 1.1, 0.1)
plt.hist(data1['emotion'], bins, color = '#4F94CD', alpha=0.9)
plt.xlim(0, 1)
plt.xlabel('情感分')
plt.ylabel('数量')
plt.title('情感分直方图')
plt.show()
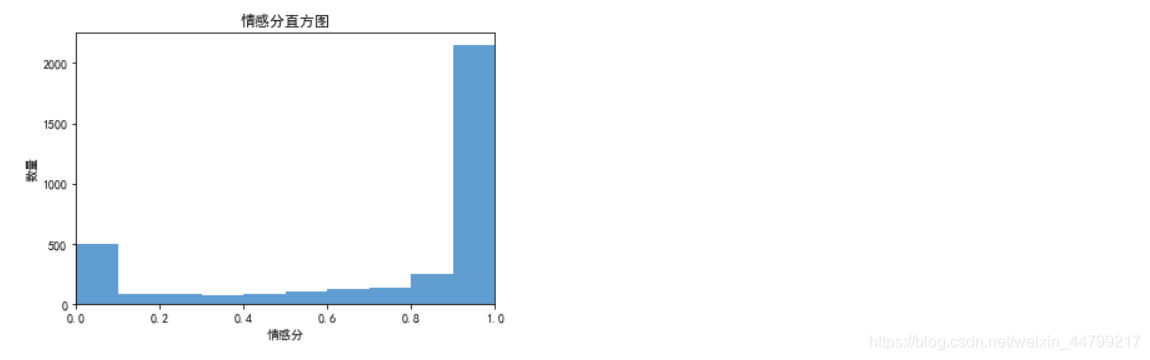
由直方图可见,评论内容两级分化较为严重;
3637条评论中有约2200条评论情感分在[0.9,1]区间内;同时,有约500条评论情感分在[0,0.1]区间内。
2.3 词云图
# 绘制词云图(这儿没有做停用词处理)
from wordcloud import WordCloud
import jieba
myfont = myfont = r'C:\Windows\Fonts\simhei.ttf'
w = WordCloud(font_path=myfont)
text = ''
for i in data['content']:
text += i
data_cut = ' '.join(jieba.lcut(text))
w.generate(data_cut)
image = w.to_file('词云图.png')
image

2.4 关键词提取
# 关键词提取top10 # 这儿直接写import jieba运行会显示没有analyse属性 from jieba import analyse key_words = jieba.analyse.extract_tags(sentence=text, topK=10, withWeight=True, allowPOS=()) key_words

以上关键词显示,消费者比较在意手机的“屏幕”“拍照”“手感”等特性,“华为”“小米”是出现频次最高的两个手机品牌。
参数说明 :
- sentence 需要提取的字符串,必须是str类型,不能是list
- topK 提取前多少个关键字
- withWeight 是否返回每个关键词的权重
- allowPOS是允许的提取的词性,默认为allowPOS=‘ns’, ‘n’, ‘vn’, ‘v’,提取地名、名词、动名词、动词
3 积极评论与消极评论
3.1 积极评论与消极评论占比
# 计算积极评论与消极评论各自的数目
pos, neg = 0, 0
for i in data1['emotion']:
if i >= 0.5:
pos += 1
else:
neg += 1
print('积极评论数目为:', pos, '\n消极评论数目为:', neg)

# 积极消极评论占比 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] = False pie_labels = 'positive', 'negative' plt.pie([pos, neg], labels=pie_labels, autopct='%1.2f%%', shadow=True) plt.show()

3.2 消极评论分析
# 获取消极评论的数据 data2 = data1[data1['emotion'] < 0.5] data2.head()

#消极评论词云图(这儿没有做停用词处理)
text2 = ''
for s in data2['content']:
text2 += s
data_cut2 = ' '.join(jieba.lcut(text2))
w.generate(data_cut2)
image = w.to_file('消极评论词云.png')
image

#消极评论关键词top10 key_words = jieba.analyse.extract_tags(sentence=text2, topK=10, withWeight=True, allowPOS=()) key_words

消极评论关键词显示,“屏幕”“快递”“充电”是造成用户体验不佳的几个重要因素;屏幕和充电问题有可能是手机不良品率过高或快递压迫;
因此平台应注重提高手机品控,降低不良品率;另外应设法提升发货,配送,派件的效率和质量。
总结
到此这篇关于利用python实现简单的情感分析的文章就介绍到这了,更多相关python情感分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python snownlp情感分析简易demo(分享)
SnowNLP是国人开发的python类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典.注意本程序都是处理的unicode编码,所以使用时请自行decode成unicode.MIT许可下发行. 其 github主页 我自己修改了上文链接中的python代码并加入些许注释,以方便你的理解:
-
Python实现购物评论文本情感分析操作【基于中文文本挖掘库snownlp】
本文实例讲述了Python实现购物评论文本情感分析操作.分享给大家供大家参考,具体如下: 昨晚上发现了snownlp这个库,很开心.先说说我开心的原因.我本科毕业设计做的是文本挖掘,用R语言做的,发现R语言对文本处理特别不友好,没有很多强大的库,特别是针对中文文本的,加上那时候还没有学机器学习算法.所以很头疼,后来不得已用了一个可视化的软件RostCM,但是一般可视化软件最大的缺点是无法调参,很死板,准确率并不高.现在研一,机器学习算法学完以后,又想起来要继续学习文本挖掘了.所以前半个月开始了用
-
python使用Word2Vec进行情感分析解析
python实现情感分析(Word2Vec) ** 前几天跟着老师做了几个项目,老师写的时候劈里啪啦一顿敲,写了个啥咱也布吉岛,线下自己就瞎琢磨,终于实现了一个最简单的项目.输入文本,然后分析情感,判断出是好感还是反感.看最终结果:↓↓↓↓↓↓ 1 2 大概就是这样,接下来实现一下. 实现步骤 加载数据,预处理 数据就是正反两类,保存在neg.xls和pos.xls文件中, 数据内容类似购物网站的评论,分别有一万多个好评和一万多个差评,通过对它们的处理,变成我们用来训练模型的特征和标记. 首先导
-
python 爬取京东指定商品评论并进行情感分析
项目地址 https://github.com/DA1YAYUAN/JD-comments-sentiment-analysis 爬取京东商城中指定商品下的用户评论,对数据预处理后基于SnowNLP的sentiment模块对文本进行情感分析. 运行环境 Mac OS X Python3.7 requirements.txt Pycharm 运行方法 数据爬取(jd.comment.py) 启动jd_comment.py,建议修改jd_comment.py中变量user-agent为自己浏览器用户
-
利用python实现简单的情感分析实例教程
目录 1 数据导入及预处理 1.1 数据导入 1.2 数据描述 1.3 数据预处理 2 情感分析 2.1 情感分 2.2 情感分直方图 2.3 词云图 2.4 关键词提取 3 积极评论与消极评论 3.1 积极评论与消极评论占比 3.2 消极评论分析 总结 python实现简单的情感分析 1 数据导入及预处理 1.1 数据导入 # 数据导入 import pandas as pd data = pd.read_csv('../data/京东评论数据.csv') data.head() 1.2 数据
-
利用Python实现微信找房机器人实例教程
目的 两年前曾为了租房做过一个找房机器人 「爬取豆瓣租房并定时推送到微信」,维护一段时间后就荒废了. 当时因为代码比较简单一直没开源,现在想想说不定开源后也能帮助一些同学更好的找到租房信息,所以简单整理后,开源到 github,地址:https://github.com/facert/zufang (本地下载) 下面是当时写的简单原理介绍: 身在帝都的人都知道租房的困难,每次找房都是心力交瘁.其中豆瓣租房小组算是比较靠谱的房源了,但是由于小组信息繁杂,而且没有搜索的功能,想要实时获取租房信息是件
-
如何利用Python实现简单C++程序范围分析
目录 1.实验说明 2.项目使用 3.算法原理 3.1构建CFG 3.2构建ConstraintGraph 3.3构建E-SSAConstraintGraph 3.4三步法 3.4.1Widen 3.4.2FutureResolution& Narrow 4.实验结果 5.总结 1. 实验说明 问题要求:针对静态单赋值(SSA)形式的函数中间代码输入,输出函数返回值的范围 实现思路: 基本根据 2013年在CGO会议上提出的“三步法”范围分析法加以实现[3],求得各个变量的范围 算法优势:空间复
-
利用python实现简单的邮件发送客户端示例
脚本过于简单,供学习和参考.主要了解一下smtplib库的使用和超时机制的实现.使用signal.alarm实现超时机制. #!/usr/bin/env python # -*- coding: utf-8 -*- import time import sys import logging import smtplib import socket import signal import ConfigParser from datetime import datetime from email
-
python+pygame简单画板实现代码实例
疑问:pygame已经过时了吗? 过没过时不知道,反正这玩意官方已经快四年没有更新了.用的人还是蛮多的(相对于其他同类项目),不过大家都是用来写写小东西玩一玩,没有人用这个做商业项目.pygame其实就是SDL的python绑定,SDL又是基于OpenGL,所以也有人用pygame+pyOpenGL做3D演示什么的.真的要写游戏的话pygame的封装比较底层,不太够用,很多东西都要自己实现(当然自由度也高).文档也不太好,好在前人留下了很多文章.拿来练手倒是很不错的选择,可以用来实践很多2D游戏
-
对Python实现简单的API接口实例讲解
get方法 代码实现 # coding:utf-8 import json from urlparse import parse_qs from wsgiref.simple_server import make_server # 定义函数,参数是函数的两个参数,都是python本身定义的,默认就行了. def application(environ, start_response): # 定义文件请求的类型和当前请求成功的code start_response('200 OK', [('Con
-
利用python画出AUC曲线的实例
以load_breast_cancer数据集为例,模型细节不重要,重点是画AUC的代码. 直接上代码: from sklearn.datasets import load_breast_cancer from sklearn import metrics from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split import pylab as p
-
利用Python实现简单的Excel统计函数
目录 需求分析 解决步骤 最终结果 技术总结 需求分析 根据原始数据,计算出累计和.回撤.连续正确.连续错误.连续正确值与连续错误值6项数据,其中原始数据大于等于0认定为正确,原始数据小于0为错误.明白了要求,那我们就开始撸代码吧~ 解决步骤 import pandas as pd #创建一个计算数据的函数 def calculate(df): pass #读取原始数据,将索引列去除 df = pd.read_excel('需求0621.xlsx',index_col=0) #调用计算数据的函数
-
利用Python实现简单的验证码处理
目录 序言 环境模块 代码展示 完整代码 序言 我们在做采集数据的时候,过快或者访问频繁,或者一访问就给弹出验证码,然后就蚌珠了~ 今天就给大家来一个简单处理验证码的方法 环境模块 这里需要用到一个 ddddocr 模块 ,这是别人开源写好的一个东西,简单又好用,但是精确度差一点点,但是还是非常好用的. 如果你追求精确度的话,可以调用别人写好的一些API . 咱们直接 win+r 弹出搜索框后输入 cmd ,点击确定弹出命令提示符窗口, 输入pip install ddddocr 即可安装. 不