python 爬取豆瓣电影短评并利用wordcloud生成词云图
目录
- 前言
- 第一步、准备数据
- 第二步、编写爬虫代码
- 第三步、生成词云图
前言
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站【实验名称】 爬取豆瓣电影《千与千寻》的评论并生成词云
- 利用爬虫获得电影评论的文本数据
- 处理文本数据生成词云图
第一步、准备数据
需要登录豆瓣网站才能够获得短评文本数据movie.douban.com/subject/129…
首先获取cookies,使用爬虫强大的firefox浏览器
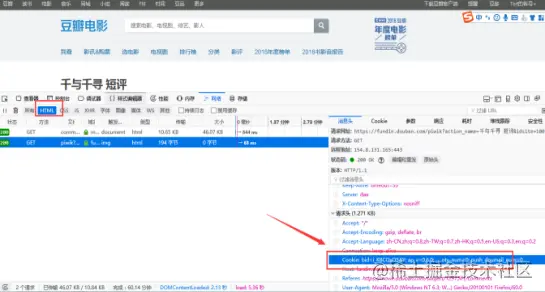
将cookies数据复制到cookies.txt文件当中备用,
第二步、编写爬虫代码
#coding = utf-8
import requests
import time
import random
from bs4 import BeautifulSoup
abss = 'https://movie.douban.com/subject/1291561/comments'
firstPag_url = 'https://movie.douban.com/subject/1291561/comments?start=20&limit=20&sort=new_score&status=P&percent_type='
url = 'https://movie.douban.com/subject/1291561/comments?start=0&limit=20&sort=new_score&status=P'
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0',
'Connection':'keep-alive'
}
def get_data(html):
# 获取所需要的页面数据
soup = BeautifulSoup(html, 'lxml')
comment_list = soup.select('.comment > p')
next_page = soup.select('#paginator > a')[2].get('href')
date_nodes = soup.select('..comment-time')
return comment_list, next_page, date_nodes
def get_cookies(path):
# 获取cookies
f_cookies = open(path, 'r')
cookies ={}
for line in f_cookies.read().split(';'): # 将Cookies字符串其转换为字典
name ,value = line.strip().split('=', 1)
cookies[name] = value
return cookies
if __name__ == '__main__':
cookies = get_cookies('cookies.txt') # cookies文件保存的前面所述的cookies
html = requests.get(firstPag_url, cookies=cookies,headers=header).content
comment_list, next_page, date_nodes = get_data(html) #首先从第一个页面处理
soup = BeautifulSoup(html, 'lxml')
while (next_page): #不断的处理接下来的页面
print(abss + next_page)
html = requests.get(abss + next_page, cookies=cookies, headers=header).content
comment_list, next_page, date_nodes = get_data(html)
soup = BeautifulSoup(html, 'lxml')
comment_list, next_page,date_nodes = get_data(html)
with open("comments.txt", 'a', encoding='utf-8')as f:
for ind in range(len(comment_list)):
comment = comment_list[ind];
date = date_nodes[ind]
comment = comment.get_text().strip().replace("\n", "")
date= date.get_text().strip()
f.writelines(date+u'\n' +comment + u'\n')
time.sleep(1 + float(random.randint(1, 100)) / 20)
每一页都会有20条的短评,所以我们依次遍历每一页a

第二步,处理爬到的数据,在第一步当中已经将数据存档到了commit.txt文件当中,

# -*- coding:utf-8 -*-
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
from scipy.misc import imread
f_comment = open("comments.txt",'rb')
words = []
for line in f_comment.readlines():
if(len(line))==12:
continue
A = jieba.cut(line)
words.append(" ".join(A))
# 去除停用词
stopwords = [',','。','【','】', '”','“',',','《','》','!','、','?','.','…','1','2','3','4','5','[',']','(',')',' ']
new_words = []
for sent in words :
word_in = sent.split(' ')
new_word_in = []
for word in word_in:
if word in stopwords:
continue
else:
new_word_in.append(word)
new_sent = " ".join(new_word_in)
new_words.append(new_sent)
final_words = []
for sent in new_words:
sent = sent.split(' ')
final_words +=sent
final_words_flt = []
for word in final_words:
if word == ' ':
continue
else:
final_words_flt.append(word)
text = " ".join(final_words_flt)
处理完数据之后得到带有空格的高频词:

第三步、生成词云图
首先安装python的wordcloud库:
pip install wordcloud
在第二步text后面加上下面代码生成词云图
font = r'C:\Windows\Fonts\FZSTK.TTF'
bk = imread("bg.png") # 设置背景文件
wc = WordCloud(collocations=False, mask = bk, font_path=font, width=1400, height=1400, margin=2).generate(text.lower())
image_colors = ImageColorGenerator(bk) # 读取背景文件色彩
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis("off")
plt.figure()
plt.imshow(bk, cmap=plt.cm.gray)
plt.axis("off")
plt.show()
wc.to_file('word_cloud1.png')
wordcloud作为对象是为小写,生成一个词云文件大概需要三步:
- 配置词云对象参数
- 加载词文本
- 输出词云文件(如果不加说明默认图片大小是400*200
| 方法 | 描述 |
|---|---|
| Wordcloud.generate(text) | 向wordcloud对象中加载文本text,例如:wordcloud.genertae(“python && wordclooud”) |
| Wordcloud.to_file(filename) | 将词云输出为图像元件以.png .jpg格式保存,例wordcloud.to_file(“picture.png”) |
具体的方法上面
wordcloud做词频统计时分为下面几步:
- 分割:以空格分割单词
- 统计:单词出现的次数并过滤
- 字体:根据统计搭配相应的字号
布局:

最后我么可以看到短评当中处理过后的高频词
我们随便照一张图片读取背景颜色

最后生成的词云图就出来了:

到此这篇关于python 爬取豆瓣电影短评并利用wordcloud生成词云图的文章就介绍到这了,更多相关python wordcloud词云图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python基于WordCloud制作词云图
这篇文章主要介绍了python基于WordCloud制作词云图,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1. 导入需要的包package import matplotlib.pyplot as plt from scipy.misc import imread from wordcloud import WordCloud,STOPWORDS import xlrd 2. 设置生成词云图的背景图片,最好是分辨率高且色彩边界分明的图片 de
-
Python基于wordcloud及jieba实现中国地图词云图
热词图很酷炫,也非常适合热点事件,抓住重点,以图文结合的方式表现出来,很有冲击力.下面这段代码是制作热词图的,用到了以下技术: jieba,把文本分词 wordcloud,制作热图 chardet,辨别文件的编码格式,其中中文统一为GB18030,更加的兼容 imageio,提取图片的形状 其他:自动识别文件编码,自动识别txt文件,图片文件名与txt文件一致,使用的是四大名著的文本(自行百度),部分中国地图 上代码: import os import jieba import wordclou
-
Python实现Wordcloud生成词云图的示例
wordcloud是Python扩展库中一种将词语用图片表达出来的一种形式,通过词云生成的图片,我们可以更加直观的看出某篇文章的故事梗概. 首先贴出一张词云图(以哈利波特小说为例): 在生成词云图之前,首先要做一些准备工作 1.安装结巴分词库 pip install jieba Python中的分词模块有很多,他们的功能也都是大同小异,我们安装的结巴分词 是当前使用的最多的类型. 下面我来简单介绍一下结巴分词的用法 结巴分词的分词模式分为三种: (1)全模式:把句子中所有的可以成词的词语都扫描出
-
python 爬取豆瓣电影短评并利用wordcloud生成词云图
目录 前言 第一步.准备数据 第二步.编写爬虫代码 第三步.生成词云图 前言 最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站[实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 利用爬虫获得电影评论的文本数据 处理文本数据生成词云图 第一步.准备数据 需要登录豆瓣网站才能够获得短评文本数据movie.douban.com/subject/129… 首先获取cookies,使用爬虫强大的firefox浏览器 将cookies数据复制到cookies.txt文件当中备用, 第二步.编写爬
-
python爬取豆瓣电影排行榜(requests)的示例代码
''' 爬取豆瓣电影排行榜 设计思路: 1.先获取电影类型的名字以及特有的编号 2.将编号向ajax发送get请求获取想要的数据 3.将数据存放进excel表格中 ''' 环境部署: 软件安装: Python 3.7.6 官网地址:https://www.python.org/ 安装地址:https://www.python.org/ftp/python/3.7.6/python-3.7.6-amd64.exe PyCharm 2020.2.2
-
python爬取豆瓣电影TOP250数据
在执行程序前,先在MySQL中创建一个数据库"pachong". import pymysql import requests import re #获取资源并下载 def resp(listURL): #连接数据库 conn = pymysql.connect( host = '127.0.0.1', port = 3306, user = 'root', password = '******', #数据库密码请根据自身实际密码输入 database = 'pachong', cha
-
Python爬虫——爬取豆瓣电影Top250代码实例
利用python爬取豆瓣电影Top250的相关信息,包括电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,导演,主演,年份,地区,类别这12项内容,然后将爬取的信息写入Excel表中.基本上爬取结果还是挺好的.具体代码如下: #!/usr/bin/python #-*- coding: utf-8 -*- import sys reload(sys) sys.setdefaultencoding('utf8') from bs4 import BeautifulSoup imp
-
用python爬取豆瓣前一百电影
目录 实现代码: 代码分析: 运行结果: 总结 网站爬取的流程图: 实现项目我们需要运用以下几个知识点 一.获取网页1.找网页规律:2.使用 for 循环语句获得网站前4页的网页链接:3.使用 Network 选项卡查找Headers信息:4.使用 requests.get() 函数带着 Headers 请求网页. 二.解析网页1.使用 BeautifulSoup 解析网页:2.使用 BeautifulSoup 对象调用 find_all() 方法定位包含单部电影全部信息的标签:3.使用 Tag
-
Python利用Scrapy框架爬取豆瓣电影示例
本文实例讲述了Python利用Scrapy框架爬取豆瓣电影.分享给大家供大家参考,具体如下: 1.概念 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 通过Python包管理工具可以很便捷地对scrapy进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包 pip install scrapy scrapy的组成结构如下图所示 引擎Scrapy Engine,用于中转调度其他部分的信号和数据
-
Python爬虫实现的根据分类爬取豆瓣电影信息功能示例
本文实例讲述了Python爬虫实现的根据分类爬取豆瓣电影信息功能.分享给大家供大家参考,具体如下: 代码的入口: if __name__ == '__main__': main() #! /usr/bin/python3 # -*- coding:utf-8 -*- # author:Sirius.Zhao import json from urllib.parse import quote from urllib.request import urlopen from urllib.reque
-
Python实现的爬取豆瓣电影信息功能案例
本文实例讲述了Python实现的爬取豆瓣电影信息功能.分享给大家供大家参考,具体如下: 本案例的任务为,爬取豆瓣电影top250的电影信息(包括序号.电影名称.导演和主演.评分以及经典台词),并将信息作为字典形式保存进txt文件.这里只用到requests库,没有用到beautifulsoup库 step1:首先获取每一页的源代码,用requests.get函数获取,为了防止请求错误,使用try...except.. def getpage(url): try: res=requests.get
-
Python爬取豆瓣视频信息代码实例
这篇文章主要介绍了Python爬取豆瓣视频信息代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quotefrom pyquery import PyQuery as pqimport requestsimport pandas as pddef get_text_page (movie_name)
-
Java爬取豆瓣电影数据的方法详解
本文实例讲述了Java爬取豆瓣电影数据的方法.分享给大家供大家参考,具体如下: 所用到的技术有Jsoup,HttpClient. Jsoup jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据. HttpClient HTTP 协议可能是现在 Internet 上使用得最多.最重要的协议了,越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资